
📢: OpenAI just dropped 2 new open-weights reasoning safety model to classify harms
OpenAI drops reasoning safety models, Claude enters finance via Excel, legal pressure mounts on LLMs, and OpenAI's memo lands at the White House.
Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-Oct-2025):
📢: OpenAI just dropped 2 new open-weights reasoning safety model to classify harms
🧮 Anthropic expanded Claude for Financial Services with a beta Excel add‑in
🏗️🇺🇸 OpenAI just published a memo for the White House
⚖️ A New York judge denied the motion to dismiss a direct copyright infringement claim against OpenAI
🧑🎓 Legal LLMs still not there yet, and they have a long way to go
📢: OpenAI just dropped 2 new open-weights reasoning safety model to classify harms
gpt-oss-safeguard-120b and gpt-oss-safeguard-20b under Apache 2.0, allows commercial use.
The model takes a developer’s policy plus the content as inputs, returns a label plus an explanation, and lets you enforce your own rules with auditable reasoning.
These models move moderation from fixed classifiers to reasoning over your policy at inference. So Changing the rules is as easy as editing the policy text, no new training, no new dataset, no new checkpoint.
Because the policy is an input, you can swap policies for different products, regions, or ages, and the same model will follow each one. You also get an explanation of how the policy text led to the decision, which makes audits and appeals easier.
The output includes a short rationale that shows how the policy text led to the decision, which makes reviews and appeals far easier. The approach shines when risks are new, data to train on is thin, the domain is nuanced, or the priority is high-quality explainable labels rather than the lowest latency.
A forum can flag cheating talk using its own definition, and a reviews site can screen for fake testimonials using its own criteria, all by editing the policy text instead of collecting thousands of labels.
Internally, OpenAI uses a similar tool called Safety Reasoner, which they trained with reinforcement fine-tuning to reward policy-consistent judgments so the model learns to reason from the policy text.
That same strategy lets them update safety rules in production quickly, starting strict and then relaxing or tightening as they learn, a process they call iterative deployment.
They also report that safety reasoning sometimes takes real compute, and in some launches it reached 16% of total compute to apply policies carefully.
A practical pattern OpenAI described from their own internal stack.
Run a tiny cheap classifier first to filter out the obvious safe stuff, only send the small fraction of tricky items to the heavier reasoning model. Safety Reasoner is now part of their core safety stack for image generation and Sora 2, where it evaluates outputs step by step and blocks unsafe generations in real time.
The same layered checks classify outputs against a detailed taxonomy across systems like GPT-5 and ChatGPT Agent, which lets the platform tailor the response to the specific risk category.
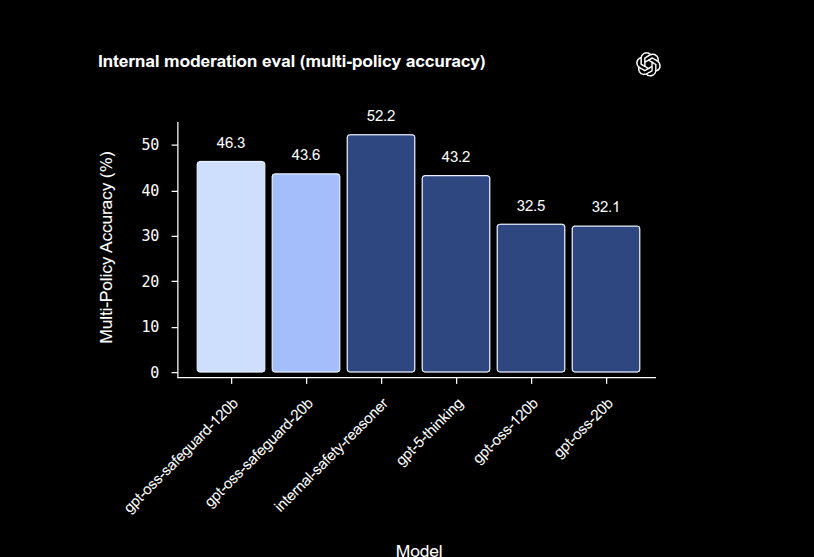
On internal multi-policy accuracy, where a single input must be correct under several policies at once, gpt-oss-safeguard-120b scored 46.3% and gpt-oss-safeguard-20b scored 43.6%, while the internal Safety Reasoner reached 52.2%, and gpt-5-thinking reached 43.2%.
This metric is strict, accuracy only counts if the model matches the gold labels across all policies for the same input, so it is a tough bar that stresses consistency.
On OpenAI’s 2022 moderation set, both gpt-oss-safeguard models hit 82.9 F1 and the internal Safety Reasoner reached 82.8, which puts the open-weight models in the same ballpark. On the ToxicChat benchmark, gpt-oss-safeguard-120b and 20b scored 79.3 and 79.9 F1, while the internal Safety Reasoner and gpt-5-thinking scored 81.3 and 81.0, which suggests the compact open models are competitive but not top in this specific test.
The models are fine-tuned versions of OpenAI’s open models, so they fit into existing open-weight stacks and can run where data residency or offline control is a requirement.
There are clear limits, a dedicated classifier trained on tens of thousands of high-quality labels can still outperform reasoning-from-policy on hard categories.
There is also a cost tradeoff, reasoning takes more time and compute than a small classifier, so a tiered pipeline is the practical pattern for high-volume platforms.
The upshot for builders is straightforward, use gpt-oss-safeguard when the policy changes a lot, explanations matter, and labeled data is scarce, and use a dedicated classifier when you can afford a big labeling run and need the last few points of accuracy.
Overall, the strongest idea here is policy-as-prompt with visible reasoning, which decouples safety rules from weights and shortens the loop from policy change to production behavior.
🧮 Anthropic expanded Claude for Financial Services with a beta Excel add‑in

A data connector is basically a plug that lets Claude pull info from another platform directly. So instead of you copying data from, say, Bloomberg or Moody’s, the connector gives Claude direct access to that data in real time — things like stock prices, earnings transcripts, or credit ratings.
A pre-built Agent Skill is like a ready-made workflow Claude already knows how to do. For example, instead of teaching Claude step-by-step how to build a discounted cash flow model or write a company report, you just trigger that skill, and it runs the full process automatically using built-in scripts and templates.
These new Claude for Financial Services features build on Sonnet 4.5, which leads the Finance Agent benchmark at 55.3% accuracy, showing strong performance in specialized financial reasoning.
Claude for Excel runs in a sidebar, letting users read, trace, and edit spreadsheets while keeping full transparency through tracked changes and linked cell explanations.
The beta starts with 1,000 Max, Enterprise, and Teams initial users before a wider release. Claude can now pull live financial data directly from several sources instead of relying on static inputs.
Aiera gives it real-time transcripts and summaries from earnings calls.
Third Bridge adds expert interviews and company research.
Chronograph brings private equity fund and portfolio data.
Egnyte lets Claude securely search internal company files.
LSEG provides live stock, bond, and macroeconomic data.
Moody’s adds credit ratings and financial info for millions of companies.
MT Newswires gives up-to-date global market news.
The Agent Skills bundle includes ready workflows for comparable company analysis, discounted cash flow, due diligence packs, company profiles, earnings reviews, and coverage reports, all usable across Claude apps and the API.
Claude already handles Excel and PowerPoint creation from prompts, so combining that with real-time data and skills makes it a stronger in-tool analyst assistant.
🏗️🇺🇸 OpenAI just published a memo for the White House
Says electricity is the bottleneck and pushes 100 GW/year of new energy plus policy steps that turn AI infrastructure into a national security asset.
China added 429 GW in 2024 while the US added 51 GW, and the memo warns this electron gap needs a rapid build to 100 GW/year.
It proposes a strategic reserve for copper, aluminum, and rare earths plus expanded tax credits for chips, servers, and transformers, and faster permits to reduce risk in key supply chains.
OpenAI is also planning certifications and a jobs site to funnel workers into roles like electricians, lineworkers, HVAC techs, welders, network techs, server techs, and facility operators.
They estimate the combined AI data center and energy builds would require about 20% of the entire skilled trades workforce that exists in the US today over the next 5 years.
⚖️ A New York judge denied the motion to dismiss a direct copyright infringement claim against OpenAI

If a jury agrees the outputs are substantially similar to books, OpenAI could owe money damages and be forced to change how its models generate story content. The ruling says a jury could find substantial similarity, so the case continues, and fair use is not decided yet.
A motion to dismiss is an early exit request, so denial means the authors cleared the threshold and can seek evidence and a trial path. The court used the more discerning observer test, which filters ideas and compares protected expression like plot, characters, and setting, and found the filed outputs could be seen as too close.
The opinion calls the outputs potential abridgments, meaning condensed retellings can infringe even without copying the same sentences. Examples include detailed sequel plans and condensed storylines that track core arcs.
OpenAI said the complaint quoted no outputs, but the judge reviewed outputs filed with the motion and found them sufficient. The dispute is a multidistrict litigation combining 2 Southern District cases, 4 transfers from California, and 2 more New York cases.
The Authors Guild sued in Sep-23 with 17 named authors, and a newsroom case followed around Jan-24.
🧑🎓 Legal LLMs still not there yet, and they have a long way to go

Says strong LLMs still fail at a basic legal task across long documents. The paper builds a realistic test using full opinions and asks models to find explicit overruling.
Overruling means a newer decision says an older decision no longer controls. The dataset has 236 confirmed case pairs from real Supreme Court decisions.
Task 1 asks an open question, name the overruled case using the opinion text. Task 2 asks a yes or no about a given pair using the same context. Task 3 flips time, asking an impossible pair that should be rejected.
Models do very well on the impossible time check but miss many real cases in Task 1. Some answers even invent time order that the years in the text contradict. Accuracy drops for older writing, which shows a bias toward modern language.
Long context alone does not fix mistakes in timeline reasoning or legal meaning. The benchmark exposes shallow shortcuts where deep legal reading is required.
That’s a wrap for today, see you all tomorrow.