
🗞️ OpenAI just moved frontier-level health AI from premium reasoning models into the free GPT-5.5 Instant model.
Free GPT-5.5 health AI, DeepAdapt’s 33x inference claims, Satya Nadella on token capital, Claude Opus 4.7 robodog coding, machine-readable SEC filings, Meta hacker culture pushback, Claude Design upgr
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (19-April-2026):
🗞️ OpenAI just moved frontier-level health AI from premium reasoning models into the free GPT-5.5 Instant model.
🗞️ Today’s Sponsor: DeepAdapt’s Adaptive Continual Intelligence Claims 33x Faster Inference and 96.4% Accuracy Without GPU Calls
🗞️ The article that went super viral - Satya Nadella on organizational economics of AI and “token capital”
🗞️ Anthropic just showed Claude Opus 4.7 program a robodog in 12:07 mint, about 20x faster than last year’s Claude-aided human team on the tested tasks.
🗞️ This was long needed for AI in finance - Making SEC filings readable for machines without flattening the accounting logic.
🗞️ Mark Zuckerberg is trying to restart Meta’s hacker culture after 8,000 layoffs but employees are pushing back.
🗞️ Anthropic just rolled out a major Claude Design update, adding design system imports, code round-trips, and a fix for its heavy token usage issue.
🗞️ OpenAI just moved frontier-level health AI from premium reasoning models into the free GPT-5.5 Instant model.

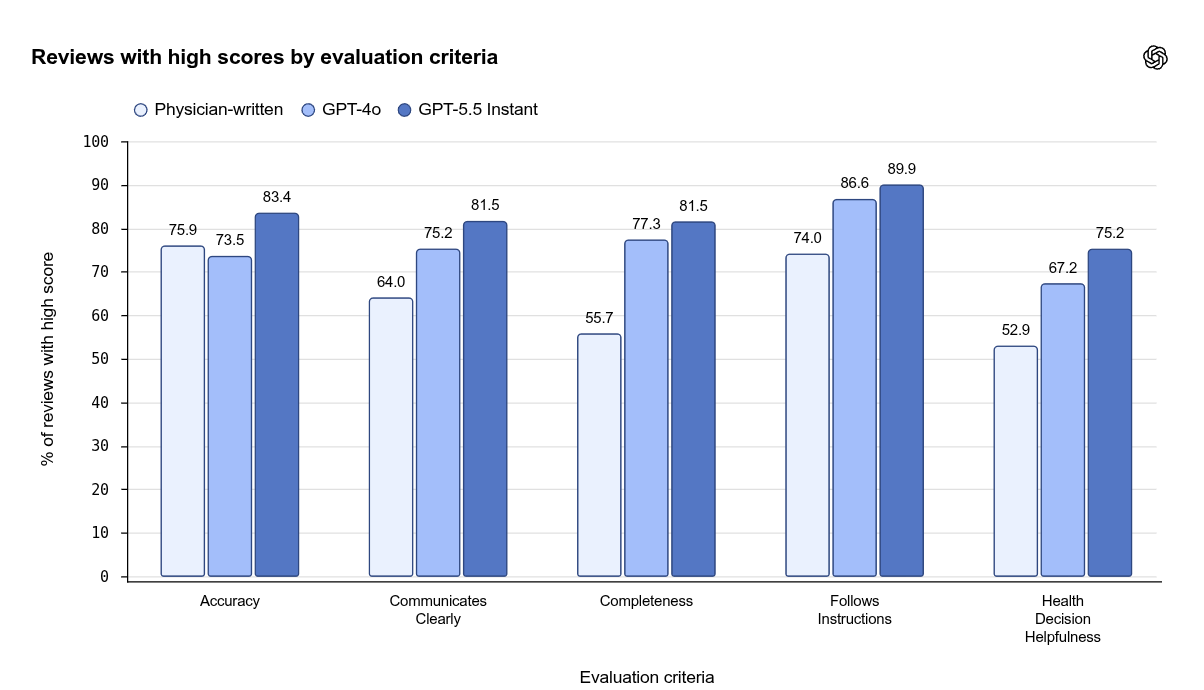
GPT-5.5 Instant now performs near OpenAI’s Thinking models on health evaluations, meaning the cheaper, faster default model is being trained to behave more like the slower models that spend extra computation checking their reasoning.
The update targets the gap between a chatbot that sounds fluent and a health assistant that knows when to slow down, ask for missing details, admit uncertainty, and push the user toward care when symptoms look urgent.
OpenAI says more than 230 million people ask ChatGPT health and wellness questions every week, so moving this capability into the free product changes the scale from premium assistance to mass access.
From OpenAI’s blog looks like they did a huge “distillation” to achieve this. i.e. a stronger teacher model and human experts create high-quality responses, and a cheaper student model learns the answer patterns without repeating the same expensive internal search every time.
i.e. OpenAI’s training loop was heavily physician-shaped: more than 260 doctors across 60 countries, 49 languages, and 26 specialties reviewed over 700,000 model responses and judged whether answers were accurate, cautious, clear, complete, and useful.
OpenAI’s likely mechanism seems to be a mix of supervised fine-tuning, where Instant is shown better answers, and preference training, where it learns which answer a physician-led rubric prefers when two outputs differ.
The physician part is crucial because the target is not just “medical facts,” but clinical response behavior, such as asking for age, pregnancy status, duration, medication history, severe pain, breathing trouble, fever, neurological symptoms, or other missing context before giving guidance.
So the strongest improvement is not medical trivia but behavior under uncertainty, because a good health answer often means saying what cannot be known yet, what context is missing, what red flags matter, and what the next safe step should be.
OpenAI also reports 71% fewer flagged factuality issues in real health traffic over two months, which suggests the update is reducing wrong claims in everyday use rather than only improving benchmark scores.
🗞️ Today’s Sponsor: DeepAdapt’s Adaptive Continual Intelligence Claims 33x Faster Inference and 96.4% Accuracy Without GPU Calls

DeepAdapt has launched a runtime intelligence layer that cuts AI operating costs by up to 82% and 33X faster inference by shifting repetitive workloads from GPUs to standard CPUs.
They are calling it Adaptive Continual Intelligence, ACI.
ACI is a runtime learning layer where analytical learning, supervised learning, and reinforcement learning work together while the system is already in production.
ACI is not caching, memory, a knowledge graph, routing, or a simple optimization trick.
This technique learns from model decisions, corrections, labels, outcomes, and experience, then serves known decisions locally on CPU. Only new, uncertain, or complex requests are routed back to the underlying model.
ACI can also be pre-trained for specific domains, making continual learning faster and cheaper. DeepAdapt is rolling out first for cloud-based LLM agents, but the same architecture becomes even more important on personal devices, where compute, battery, latency, and local inference reliability are much tighter constraints.
In their benchmarks, ACI has shown up to 90% lower token consumption, 5.7X lower production-scale cost, 33X faster inference with 159 ms median latency, 96% accuracy vs. 85% without ACI, 85.7% lower energy per 1,000 decisions, and 4.8× fewer rule violations.
DeepAdapt intercepts user requests, serving known answers instantly from a standard CPU to completely bypass the expensive GPU.
New questions go to the GPU, but the system logs the output and any human corrections to learn for the next time.
This keeps the underlying language model entirely frozen while the outer software layer handles all real-time learning and auditing.
ACI requires zero training. No fine-tuning. No retraining pipelines. You wire it into your existing stack and it starts learning from real use on the very first request. Every improvement happens at runtime.
The effect: GPU dependency and cost decrease as the system matures, and energy consumption drops proportionally.
In ACI-native agents, everything else becomes a tool inside the ACI runtime: the LLM, memory, tools, knowledge graphs, prompts, workflows, APIs, and external systems. ACI decides what can be handled locally, what should be learned, what must be enforced, and when the system actually needs to fall back to the model.
Inference is becoming one of AI’s biggest cost centers. Token prices may fall, but total AI bills keep rising because usage is exploding. The real leverage is avoiding unnecessary GPU calls altogether.
With ACI, the LLM is no longer the center of the architecture, because ACI becomes the runtime intelligence layer that decides what can be inferred locally, what should be learned, what must be enforced, and when the model is actually needed.
🗞️ The article that went super viral - Satya Nadella on organizational economics of AI and “token capital”

The real AI advantage is not model quality alone, but the learning loop built around the model.
Human capital becomes more valuable because humans decide what the AI should learn and optimize for.
Token capital is the AI capability a firm builds, owns, and improves over time.
Companies can offload tasks, but they cannot afford to offload their learning.
Private evals matter because each company needs to measure AI against its own business outcomes.
Private reinforcement loops turn real workflows, corrections, failures, and judgments into compounding AI capability.
Institutional memory must become queryable so AI can use the firm’s actual knowledge, history, and context.
The firm’s new IP is the loop that connects people, workflows, data, feedback, and AI improvement.
Companies need sovereignty so they can switch models without losing their accumulated expertise.
A generic frontier model is not enough; firms need company-specific systems that behave like experienced insiders.
The danger is that a few model owners absorb everyone’s knowledge and capture most of the value.
AI should create a frontier ecosystem, not a winner-take-all model economy.
The stable future is one where every company can compound its own human and token capital.
Employees should see their judgment amplified, scaled, and made reusable rather than erased.
The companies that build these learning loops early will create advantages that are hard to copy.
🗞️ Anthropic just showed Claude Opus 4.7 program a robodog in 12:07 mint, about 20x faster than last year’s Claude-aided human team on the tested tasks.

Project Fetch asks whether an LLM can connect real robot hardware, read camera/lidar feeds, write movement code, track location, and detect a ball.
Opus 4.7 did 5 tasks alone versus Team Claude’s 264 minutes, while writing 1,045 lines instead of 10,309.
The gain came from choosing the right interfaces quickly and writing scripts that worked without long human trial-and-error.
It still couldn’t fetch the ball. The failure came from closed-loop control, where the robot must see a drifting ball and adjust movement after each shove.
AI is getting very good at turning messy hardware into working code, but real-time physical judgment is still hard.
🗞️ This was long needed for AI in finance - Making SEC filings readable for machines without flattening the accounting logic.

Stanford + Univ of Calif + Nanjing Univ researcher has just released a dataset and methods for a cleaner way to turn SEC filings into useful LLM training data without losing the meaning inside financial tables.
A 152B-token public snapshot and estimate the full archive could become about 550B tokens of long financial documents.
Has less than 0.1% overlap with Common Crawl-derived corpora.
The authors propose SEFD, a rebuilt version of EDGAR filings that keeps table structure, indentation, and financial meaning while using fewer tokens for LLM training.
The dataset turns EDGAR into layout-faithful MultiMarkdown, preserving merged headers, indentation, signs, spans, and table hierarchy while shrinking enormous presentation scaffolding into usable tokens.
🗞️ Mark Zuckerberg is trying to restart Meta’s hacker culture after 8,000 layoffs but employees are pushing back.

In an internal memo sent to staff on last week, Zuckerberg tried to boost morale, but it seemed like a pretty clear misread of the moment. He promised a companywide AI hackathon in July, only for employees to push back hard because they were clearly not interested.
🗞️ Anthropic just rolled out a major Claude Design update, adding design system imports, code round-trips, and a fix for its heavy token usage issue.

The old version worked more like a smart visual generator: you described a webpage, slide, or app screen, and Claude created something polished, but the output came from Claude’s own taste rather than your company’s design system.
The new version changes the control layer, because Claude can now import design systems from repos, design files, or codebases, then build with the actual buttons, fonts, colors, spacing rules, and components your team already uses.
That means the model is no longer only generating a design; it is checking whether its own output matches the approved system before you see it.
This is a big deal for companies because brand consistency is usually boring, manual, and easy to break when many teams are making pages, decks, ads, and product screens at high speed.
The Claude Code sync is the other major shift, because design and engineering can now pass work back and forth through the same Claude environment instead of relying on screenshots, specs, or a developer rebuilding the mockup from scratch.
A designer can start with a visual design, hand it to Claude Code, and a developer can continue from the real component library, while a developer can also start in code and sync the design project back.
The canvas editor also super useful, because small changes like drag, resize, and align no longer need a full model regeneration, which should reduce wasted tokens and make the tool feel less like a demo and more like daily software.
Anthropic wants Claude Design to become the starting point for branded assets, product prototypes, and code-ready interfaces, then send that work into tools like Canva, Adobe, Vercel, Replit, PDF, and PowerPoint.
That’s a wrap for today, see you all tomorrow.