
🧬 OpenAI just released FrontierScience to test PhD-level science reasoning, and says GPT-5.2 leads but lags on research-style tasks.
OpenAI's GPT-5.2 faces limits in research tasks, Google launches Gemini 3 Flash, Tencent drops real-time world model, and MIT flags issues in multi-agent systems.
Read time: 8 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (17-Dec-2025):
🧬OpenAI just released FrontierScience to test PhD-level science reasoning, and says GPT-5.2 leads but lags on research-style tasks.
🏆 Google just launched Gemini 3 Flash — and claims it’s as fast as using traditional Search.
👨🔧 Tencent just dropped HY World 1.5 (WorldPlay), an open-sourced real time world model that streams at 24 FPS with long term geometric consistency
😵 New Google x MIT research points to pitfalls in multi-agent systems
👨🔧 Videos to Watch: The future of intelligence | Demis Hassabis (Co-founder and CEO of DeepMind)
🧬 OpenAI just released FrontierScience to test PhD-level science reasoning, and says GPT-5.2 leads but lags on research-style tasks.

OpenAI Unleashes FrontierScience for AI-Fueled Scientific Reasoning.
OpenAI worked with a biotech lab to see if GPT-5 could improve a real lab procedure, not just answer questions.
They gave it a standard DNA cloning protocol, let it suggest changes, ran those changes in a controlled setup, and then fed the results back so it could revise the next round.
After a few iterations, the updated protocol produced about 79x more of the “correct, working DNA result” than the original protocol did, when they ran the same kind of cloning job.
In cloning, a lot of attempts fail or produce the wrong DNA, so “usable output” is basically the amount of correct product you can actually take forward to the next experiment.
So 79x is saying the improved method turned many more of the attempts into successful, correct results, or produced much more correct DNA per run, compared to the baseline.
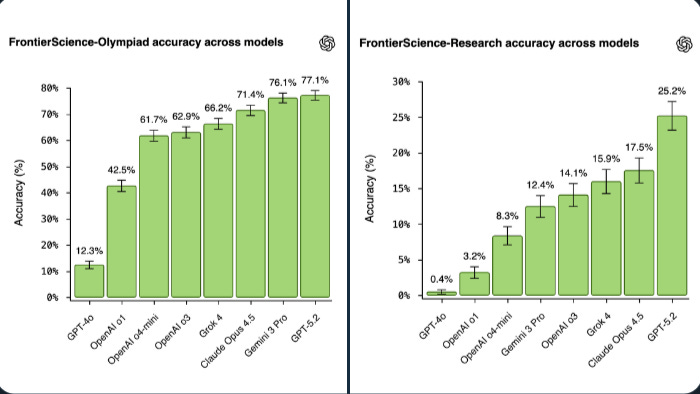
FrontierScience targets harder, expert-written, text-only problems across physics, chemistry, and biology.
It has 700+ questions overall, but the scored gold set is 160, split into 100 Olympiad and 60 Research tasks. Its available on Hugging Face
Olympiad questions have short answers, while Research tasks are multi-step and graded with a rubric.
Each Research rubric totals 10 points, and OpenAI counts at least 7 points out of 10 as correct.
OpenAI says it uses a model grader, so rubric items are written to be checkable.
OpenAI reports GPT-5.2 at 77% on Olympiad and 25% on Research, showing a big structured-versus-open gap.
Molecular cloning copies and joins DNA pieces, so better efficiency means fewer failed runs before usable DNA.
🏆 Google just launched Gemini 3 Flash — and claims it’s as fast as using traditional Search.
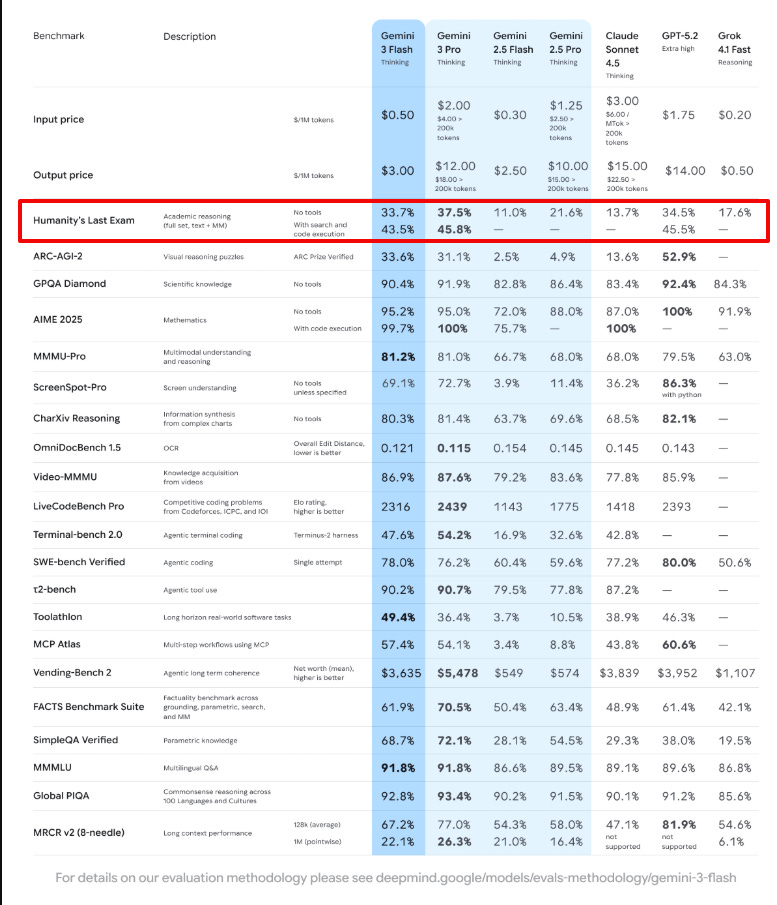
Gemini 3 Flash Outperforms GPT-5.2 in some benchmarks. 3x speed, 30% fewer tokens, and strong benchmark scores
It is rolling out globally across the Gemini app and AI Mode in Search, and it is also available to developers through the Gemini API in Google AI Studio, Gemini CLI, and Google Antigravity, plus enterprise routes like Vertex AI and Gemini Enterprise.
Gemini 3 Flash was built to be highly efficient, pushing the Pareto frontier of quality vs. cost and speed.
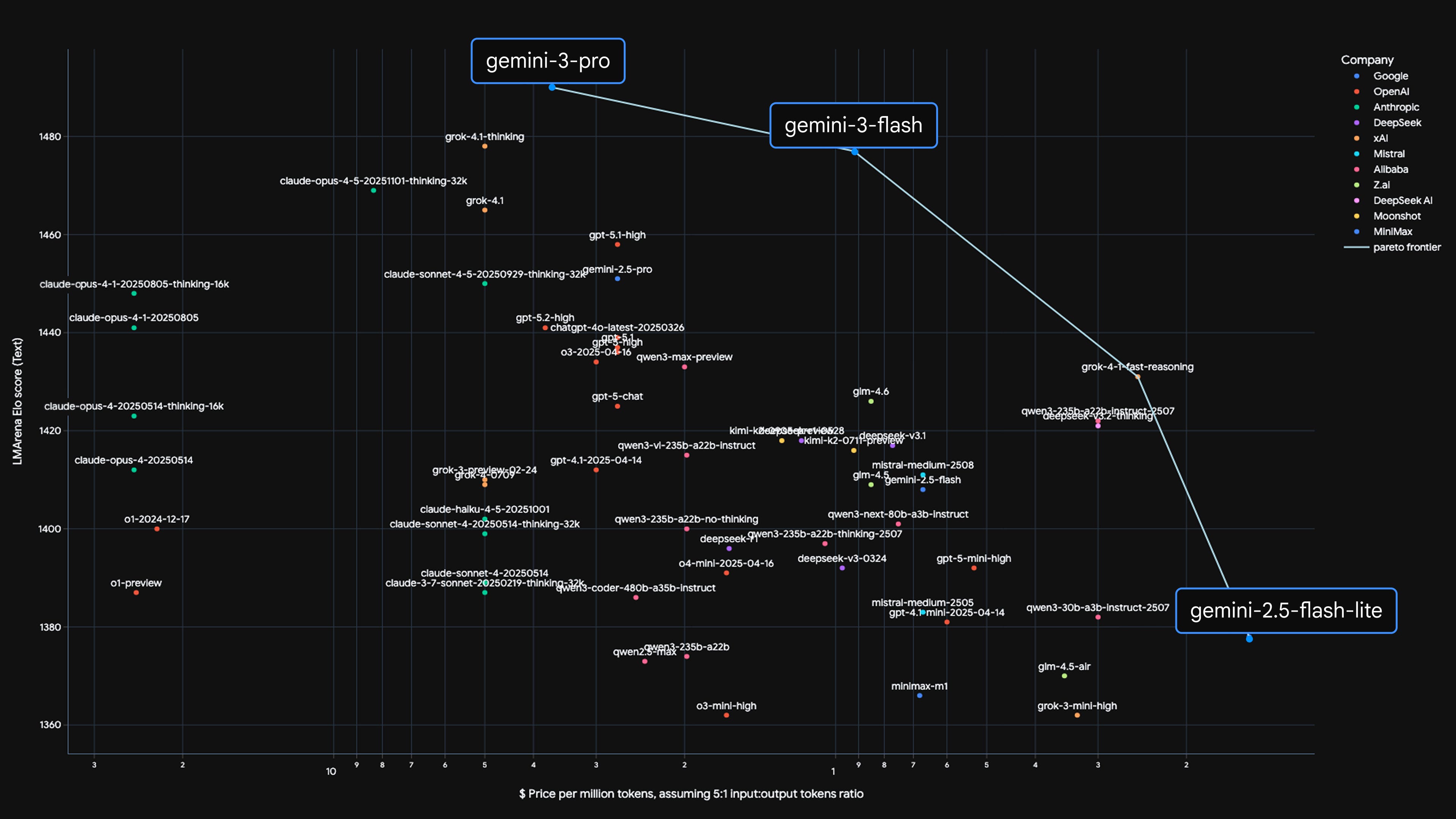
“Pareto frontier,” means the best tradeoffs where you cannot improve quality without paying more or slowing down, and Gemini 3 Flash is shown as moving that best-tradeoff line outward.
The big technical claim is that speed is not being bought by “getting dumber,” since it posts 90.4% on GPQA Diamond and 33.7% on Humanity’s Last Exam without tools, plus 81.2% on MMMU Pro.
Gemini 3 Flash also leans on “dynamic thinking,” which means it can spend more internal effort on harder prompts and spend less on easy prompts. Google says that, on typical traffic, this ends up using 30% fewer tokens than Gemini 2.5 Pro.
On speed and price, its 3x faster than Gemini 2.5 Pro, with pricing at $0.50/1M input tokens and $3/1M output tokens, and audio input at $1/1M input tokens.
For coding agents, it scores 78% on SWE-bench Verified, which is a test that checks whether an agent can actually fix real software issues instead of just sounding confident.
On the product side, Gemini 3 Flash becomes the default model in the Gemini app (replacing 2.5 Flash), and Google frames this as a free upgrade for everyday tasks.
Gemini 3 Flash can literally make “agent-like” apps feel snappy, where the model has enough reasoning to plan and act, but not so much latency that the app feels stuck.
In the tough Humanity’s Last Exam suite, Gemini 3 Flash scored less than a percentage point worse than GPT-5.2 when neither model had access to tools like web search. In a handful of other benchmarks, Gemini 3 even managed to outperform OpenAI’s latest. For instance, in MMMU-Pro, a benchmark designed to test a model’s multimodal understanding and reasoning, it edged out GPT-5.2 with a result of 81.2 % compared to 79.5 %.
👨🔧 Tencent just dropped HY World 1.5 (WorldPlay), an open-sourced real time world model that streams at 24 FPS with long term geometric consistency

HY World 1.5 that turns text or an image into a controllable, real time 3D world.
Supports both first-person and third-person perspectives, enabling applications like promptable events and infinite world extension.
On the architecture side:
WorldPlay is an autoregressive streaming video diffusion model that predicts the next 16-frame chunk from user actions using a 3D VAE and a Diffusion Transformer, so generation can run continuously.
A Dual Action Representation blends discrete keys like WASD (the 4 keyboard keys used for movement in PC games) with continuous camera pose, giving robust control across scene scales while caching exact locations for future revisits.
For stability when returning to the same place, Reconstituted Context Memory rebuilds context from recent chunks and spatially relevant older chunks, then applies temporal reframing to treat far past but important frames as near in time.
To improve action following and visuals, WorldCompass RL uses clip-level rollouts plus complementary rewards for motion accuracy and image quality, which reduces exposure bias on long horizons.
For speed without drift, Context Forcing distills a bidirectional teacher into a few-step autoregressive student by aligning teacher and student memory context, preserving long range consistency with only 4 denoising steps.
Engineering choices like mixed sequence plus attention parallelism across 8 GPUs, progressive streaming VAE decoding, quantization, and attention KV cache keep latency low while frames keep flowing.
Training spans 320K curated clips from games, real 3D captures, synthetic 4D renders, and in-the-wild videos, and the model supports first person, third person, promptable events, infinite world extension, and 3D reconstruction.
Benchmarks show stronger short-term quality and larger gains in long horizon revisit stability versus baselines that are fast but forgetful or consistent but slow.
😵 New Google x MIT research points to pitfalls in multi-agent systems

e.g. it shows financial analysis tasks improved by about 81% when split across agents, but Minecraft tasks that need careful step-by-step execution got worse by up to 70%.
Across 180 controlled runs on models from OpenAI, Google, and Anthropic, results swung based on whether the task could be cleanly split up or needed tight step-by-step work.
A multi-agent workflow means several copies of an LLM each do a slice of the job, then a coordinator tries to merge the slices into 1 final answer.
Across 180 matched budget tests, team setups ranged from about +81% to -70% versus 1 agent. They keep the tools, instructions, and total text budget fixed, then change only the task, model, and coordination style.
They compare 1 solo agent with 4 team patterns, independent (no sharing), centralized with 1 manager, decentralized debate, and hybrid mix.
The main driver is task shape, decomposable finance analysis improves with a manager, but step by step planning gets worse. Coordination has a tax, agents must summarize and sync, so each one has less room to reason and use tools safely.
They measure overhead, redundancy, and error amplification (how mistakes spread), then a predictor picks the best setup in 87% of held out cases.
The pattern is simple, tasks with independent sub-problems benefit from parallel work, while tasks that depend on a single consistent plan can break when agents disagree or lose shared context.
Multiple agents also burn the same token budget faster, so each agent gets less room to think, and useful context gets dropped earlier.
When 1 agent was already around 45% accurate, adding more agents usually made outcomes worse, which points to coordination overhead beating any extra “brains.”
👨🔧 Videos to Watch: The future of intelligence | Demis Hassabis (Co-founder and CEO of DeepMind)

He mentioned that the “jagged intelligence” we see could come from how tokenization works, but believes many of these odd behaviors can be fixed. He also said models don’t yet use inference-time reasoning consistently, and it should include more double-checking and use of tools.
He hasn’t seen a strict scaling “wall,” even though gains are slowing. He thinks progress now sits in a middle zone—not exploding, but still meaningful—and pointed to Gemini 3 as proof of steady improvement.
He explained that synthetic data can help bypass data shortages, especially for coding and math, where results can be verified and give endless training signals.
He highlighted that world models like Genie have uses beyond language, and he personally wants to use them to make the ultimate game experiences.
He said they’re creating physics benchmarks with accurate game engines and controlled setups to test if Veo or Genie truly model physics instead of just faking realistic-looking video. Current models still fall short of full reliability.
He believes AI is hyped too much in the short run but underestimated long-term. Some startups seem overpriced, while major tech firms have stronger fundamentals; he’s not too focused on whether this is a bubble.
He expects a “proto-AGI” to come from combining Gemini 3, Nano Banana Pro, and their world-model or agent projects like Genie and Simma into one system.
He described the frontier work as exciting but exhausting. He barely sleeps, feels constant progress, and senses big responsibility because the coming decade’s effects are not fully grasped yet.
He called today’s systems mostly “passive,” but said far more agent-like systems are coming soon. He warned that autonomy will increase risks, making the next agent phase especially sensitive.
His thought on AI bubble
Says some AI startups with tens of billions of valuations are wildly overpriced — and a correction may come.
AI is overhyped in the short term, underappreciated in the medium to long term. An “AI bubble” exists in parts of the ecosystem, especially seed stage startups raising at tens of billions in valuation before proving anything, which he sees as unsustainable.
However, he differentiates that from big tech, where he thinks there is real business value behind the valuations, though outcomes still depend on execution. Booms and corrections are normal for transformative tech, similar to the internet and mobile cycles.
That’s a wrap for today, see you all tomorrow.