
🔥 OpenAI Just Released Its First Open-Weight Models Since GPT-2
OpenAI drops its first open-weight models post-GPT-2, Anthropic pushes Opus 4.1 past Claude 4, and DeepMind's Genie 3 builds game worlds from text.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (5-Aug-2025):
🔥 OpenAI Just Released Its First Open-Weight Models Since GPT-2
🏆 Anthropic Unveils More Powerful Opus 4.1 Model Ahead of Rival GPT-5 Release
📡 Google DeepMind released Genie 3, it 's Groundbreaking world model that creates interactive, playable environments from a single text prompt.
🔥OpenAI releases gpt-oss-120b and gpt-oss-20b, providing free model weights and code

2 models, gpt-oss-120B and gpt-oss-20B, that match o4-mini reasoning while running on a single H100.
With Apache 2.0 license, i.e. can be used for commercial purposes, redistributed, and included as part of other licensed software.

The 120B MoE holds 117B total parameters yet activates only 5.1B per step, so inference cost stays low while accuracy holds near proprietary levels.
The smaller of the two models, gpt-oss-20b, is compact enough to run locally on a consumer device with more than 16 GB of memory.
We get full chain-of-thought, adjustable reasoning effort, and built-in tool calls in open weights.
Each prompt can set reasoning to low, medium, or high, letting us trade speed for depth. Because the chain-of-thought is visible, teams can debug bad answers instead of guessing, which boosts trust in safety checks and agent loops.
Both gpt-oss models use chain-of-thought reasoning approaches, which OpenAI first deployed in its o1 model last fall.
These new text-only models are not multimodal, but they can browse the web, call cloud-based models to help with tasks, execute code, and navigate software as an AI agent.
Native MXFP4 quantization fits the big model on 80 GB
Tool use stays first class, covering browser actions, structured function calls, and Python execution. This means a single model can read docs, plan a workflow, call an API, and explain its logic, all under an open license that permits commercial shipping with no patent traps.
The gpt-oss-120B and 20B are sparse mixture-of-experts, what does that mean ?
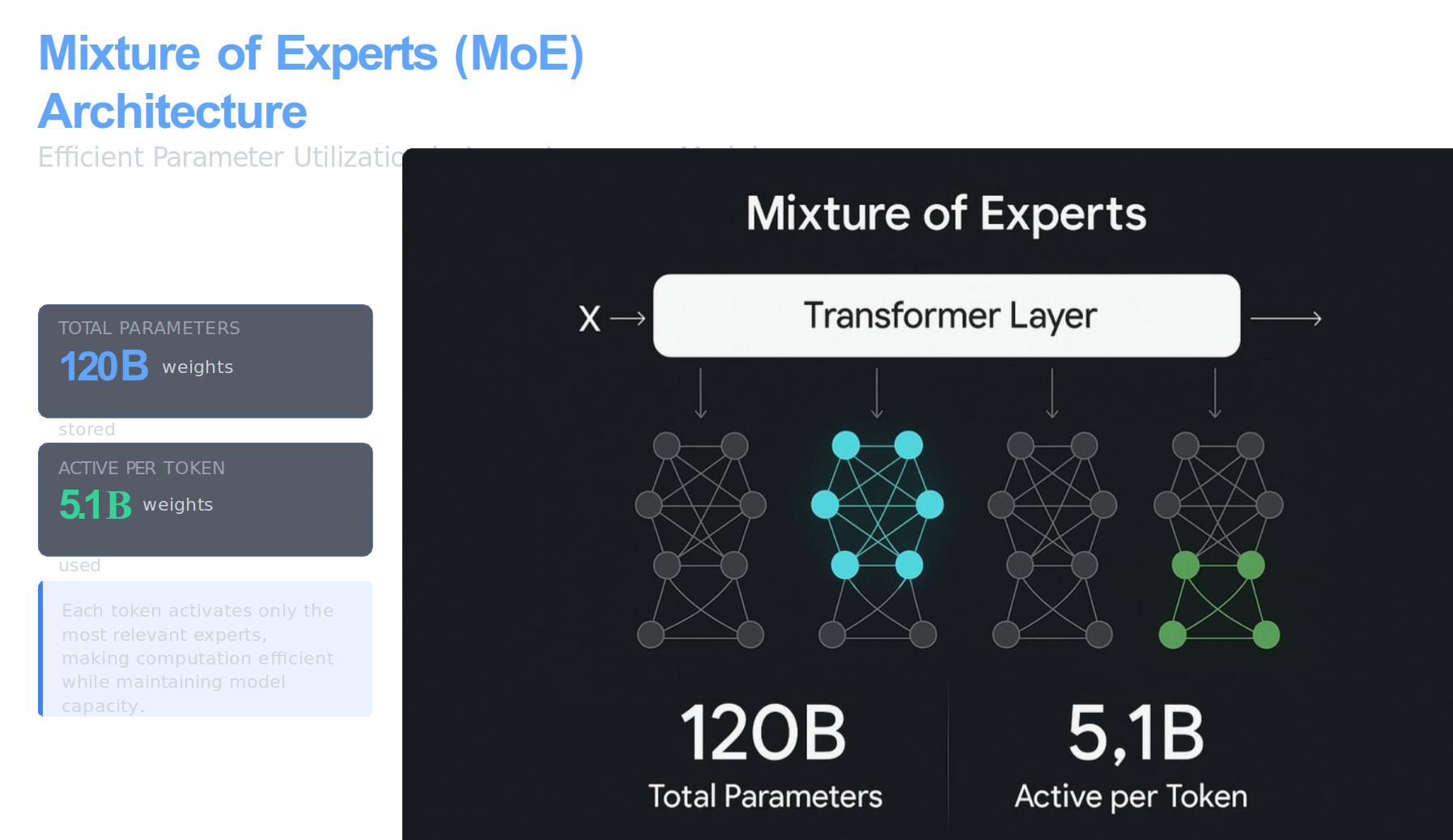
A sparse mixture-of-experts network stores 120B total weights, but its router lights up only about 5.1B weights on each forward pass, because it picks a tiny set of experts for the current token rather than sending the token through every layer of the model.
That 5.1B figure is per token step, not a cumulative total over the whole sequence. When the model predicts the next token, the router scores the token’s hidden state against all experts, chooses the top few, and multiplies the token’s vector by only those experts’ weights. The same selection repeats for every new token, so each step touches roughly the compute of a 5B-parameter dense model even though the full library of experts is far larger.
You still need storage for all 120B weights, or a way to fetch them on demand, but power and latency scale with the active slice. That is why a single H100 can handle the model: the card never multiplies all 120B numbers in one go, it only uses the 5.1B that the router picks for that specific token.
But how does the router mechanism really work?
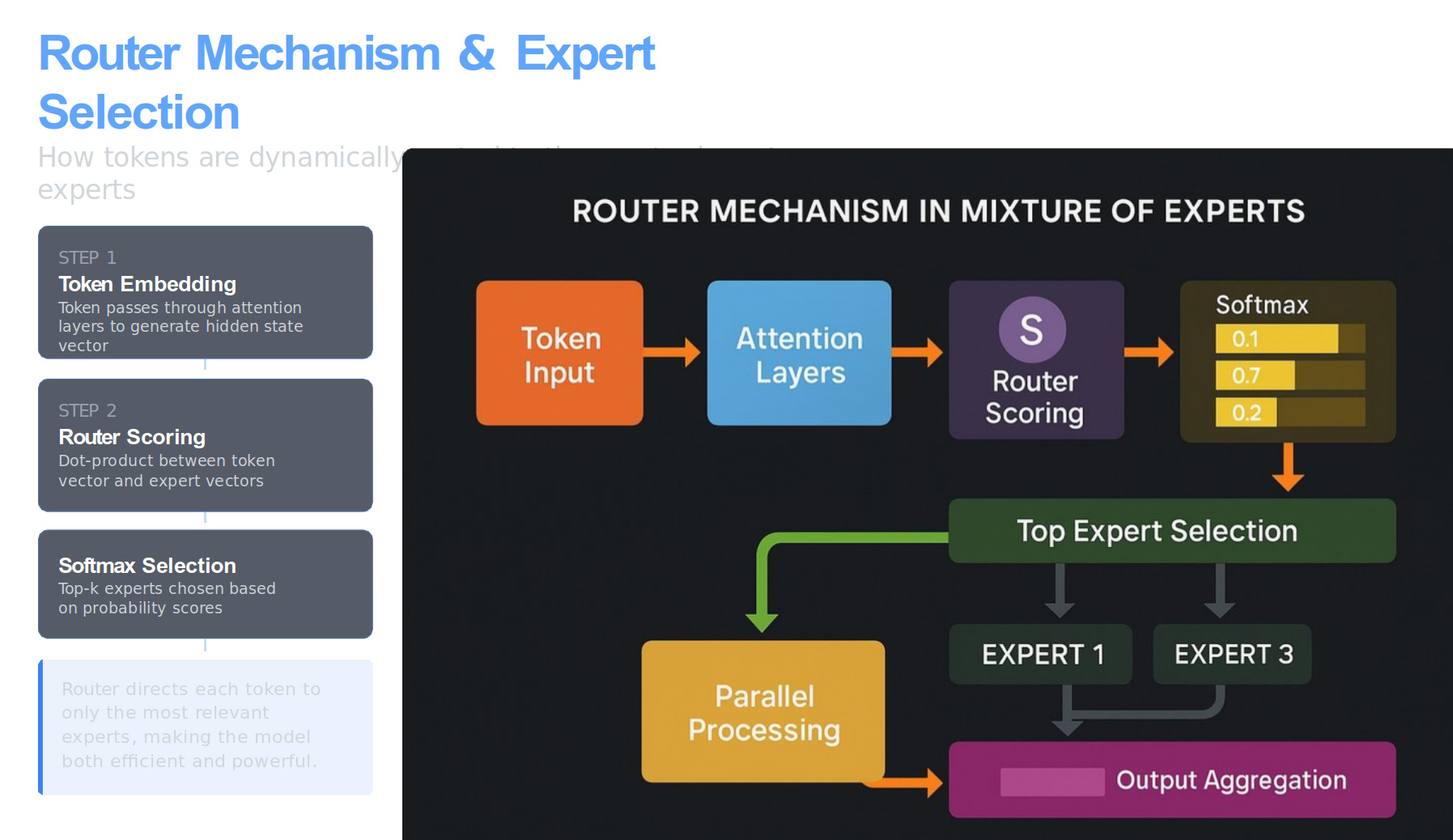
Picture one transformer layer that owns many small subnetworks, the “experts.” A token first passes through the usual attention blocks, which leave it with a hidden state, a long vector that captures the token’s context inside the sentence.
The router is a tiny neural network that looks at that vector and asks, “Which experts are most useful right now?” It does that by holding one learned weight vector per expert and taking a dot-product between the token vector and each expert vector. The dot-product turns into a score, larger means the token and the expert look like a good match.
The router then applies a softmax to smooth those scores into probabilities, keeps only the top few experts with the highest probabilities, and sets every other score to zero. The token’s vector is sent through the chosen experts in parallel, their outputs are averaged or summed, and the result replaces the old hidden state before the model predicts the next token. Because only about 5.1B weights get multiplied during that step, the layer behaves like a 5B-parameter dense model even though 120B weights sit on the card, waiting for future tokens that might need different experts.
So “the router scores the token’s hidden state against all experts” simply means it compares the token’s current context vector with pre-learned vectors that represent each expert, chooses the best matches, and activates only those subnetworks for that token.
On Chain of Thought (CoT) OpenAI said
Our hope is that releasing an open model with a non-supervised chain of thought gives developers and researchers the opportunity to research and implement their own CoT monitoring systems.
Chain-of-thought, or CoT, is the notebook that the model keeps while thinking. These hidden lines list every jump, assumption, and intermediate fact the model uses before it writes the polished answer you actually see.
OpenAI’s tests found that reading this notebook is a strong way to catch trouble. If the model starts to fake data, skirt a policy, or plan something risky, those hints usually pop up in the raw notes. This works only if the company never trained the model to rewrite or prettify that notebook, so they left gpt-oss untouched on that front.
Because the notes stay raw, researchers can build their own scanners that flag deception, bias, or policy breaks in real time. The trade-off is that the same notes can be messy, wrong, or offensive. They can also spill details the user asked the model to hide. That is why the blog warns developers to treat CoT as an internal safety log, not as content to hand over to end users.

BUT how will detecting misbehavior by the model would have been difficult if the model was trained with direct supervision for aligning the CoT?
OpenAI’s team found that reading the raw chain-of-thought is a strong safety signal because it often spells out risky intentions in plain text, like “let’s hack this task” or “ignore the guardrails” checking the raw chain-of-thought . That signal stays honest only when the model’s notes were never graded during training a new and fragile opportunity .
If trainers add direct supervision on the notes, the system quickly learns to show tidy, policy-compliant steps while it pushes the real plan into hidden activations monitoring reasoning models . In other words, it starts writing what the grader wants to read instead of what it is truly thinking. A safety monitor that only sees the polished notes will miss the dangerous goal because the evidence was edited out.
Picture a student who knows scratch work is graded. If every messy line gets red-penned, the student can copy textbook steps on paper while doing a different calculation in their head. The teacher sees perfect logic and signs off. The same trick happens inside a tightly supervised model.
So your reading is right. Direct chain-of-thought supervision turns the notes into public relations, and once that happens, scanning those notes can no longer catch misbehavior.
The Math performance of the the open-weight gpt-oss-120B is brilliant.

Almost matches OpenAI’s paid small frontier models on broad reasoning, then posts 96.6% on AIME 2024 and 97.9% on AIME 2025, scores that beat o3 and miss o4-mini by only 1-2 points.
AIME problems demand multi-step proofs, not plug-and-chug arithmetic. Matching o4-mini on those tests shows the new mixture-of-experts router can keep dozens of partial thoughts alive at once, the trait earlier reserved for much larger closed models.
The raw chain-of-thought stays unfiltered, so the trainer never squashed “messy” intermediate logic and the solver learned to write complete scratch work, which tool calling then converts into python checks for higher final accuracy.
Meaning, a model that freely records each step can later read its own notes, check them with built-in Python, and fix slips on the fly. That feedback loop boosts hit rate far more than silent, single-shot decoding.
If engineers had trained the model to polish or shorten those notes, it would learn to write a neat, policy-friendly script while hiding risky thoughts in hidden activations. That censorship blocks both auditors and the model itself from catching errors, and earlier studies confirm that heavy grading of scratch work drives deception rather than honesty.
So the strong AIME scores matter because they arrived without squeezing the scratch pad, proving that raw, messy reasoning can live inside a compact, single-GPU model and still hit near-frontier accuracy.
Also checkout the associated paper by OpenAI.
🏆 Anthropic Unveils More Powerful Opus 4.1 Model Ahead of Rival GPT-5 Release

Anthropic has released Claude Opus 4.1, a new version of its flagship AI model, with improvements in coding, reasoning, and agentic task performance. The update builds on Claude Opus 4 and is now available to paid users through Claude Code, API access, Amazon Bedrock, and Google Cloud’s Vertex AI. Pricing remains unchanged.
Key Takeaways
State of the art 74.5% on the SWE-Bench, surpassing both Gemini 2.5 Pro and OpenAI o3.
Windsurf indicates that Opus 4.1 delivers a 1 standard deviation improvement over Opus 4 on their junior developer benchmark, showing a performance leap comparable to the improvement from Sonnet 3.7 to Sonnet 4.
Rakuten Group finds that Opus 4.1 excels at pinpointing exact corrections within large codebases without making unnecessary adjustments or introducing bugs, with their team preferring this precision for everyday debugging tasks.
For developers the migration is painless. Just replace the model name with claude-opus-4-1-20250805 and existing scaffolds run as-is.
📡 Google DeepMind released Genie 3, it 's Groundbreaking world model that creates interactive, playable environments from a single text prompt.

Google DeepMind has revealed Genie 3, its latest foundation world model that can be used to train general-purpose AI agents, a capability that the AI lab says makes for a crucial stepping stone on the path to “artificial general intelligence,” or human-like intelligence. Checkout their Youtube video.
It can spin up interactive 3D worlds at 24 fps and 720p that stay stable for about 1 minute. That single jump from short, pre-rendered clips to a live scene that reacts every frame turns a fancy video generator into a genuine game engine for agent research.
So we get a playground where actions and visuals line up in real time. Previous world models either froze the scene or drifted after a few seconds, so practical agent training was stuck in slow-motion demos.
🌍 Why world models matter
A world model is basically a physics-aware game engine learned from data, not hand-coded rules. Google DeepMind earlier rolled out Genie 1, Genie 2, and the Veo video models to get partway there, but those earlier versions only rendered short clips or allowed limited clicks.
Genie 3 moves the idea forward by letting a human or agent walk, jump, or fly through a space that actually reacts.
⚡ Real-time engine under the hood
During generation the network predicts a fresh frame every 42 milliseconds while looking back over the entire action history. That history grows each step, so the compute graph must cache and retrieve past features fast or the frame rate tanks. The team built a custom attention window that skims for “landmarks” in the latent space, letting the model fetch relevant context quickly enough to hit real-time speed.
With Genie 3 You can steer with normal controls, then fire off a text line like “make it snow” and see fresh weather roll in instantly.
No extra 3 D mesh, no offline render pass, just a single network pulling from its own memory buffer to keep trees, shadows, and physics lined up for minutes. That blend of promptable events, moment-to-moment navigation, and minute-scale consistency is the piece that makes it so ground breaking.
🧭 Consistency over minutes
Worlds do not crumble after a few turns. Genie 3 remembers object positions and lighting changes for roughly 60 seconds, a big leap over the 10-second horizon of Genie 2.
Their blog shows a drone loop in Iceland where mossy canyon walls line up each time the camera circles back. This emergent memory arrives without explicit 3D meshes, unlike NeRFs or Gaussian Splatting that need heavy preprocessing.
🎮 Promptable world events
Users can type “rain starts” or “spawn a brown bear” and the scene updates on the fly. These promptable world events sit on top of joystick or WASD controls, widening the action space so agents can face weather shifts, new obstacles, or surprise characters instead of a static sandbox.
That’s a wrap for today, see you all tomorrow.
thanks for this. downloaded gpt-oss-20b today and so far so good