
OpenAI Launched Deep Research for in-depth Research work, Outranks Every Other model on Humanity’s Last Exam
OpenAI's Deep Research dominates, Anthropic fortifies defenses, Jina AI offers alternatives for Deep Research, Toronto one-shots research, and R1-V flips scaling laws with 2B outperforming 72B.

Read time: 9 min 10 seconds
📚 Browse past editions here.
( I write daily for my 112K+ AI-pro audience, with 4.5M+ weekly views. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (3-Feb-2025):
🥉 OpenAI Launched Deep Research for in-depth Research work, outranks every otehr model on Humanity’s Last Exam
🥊Anthropic challenges you to break their new jailbreaking defense!
📡 Jina AI releases code to build an alternative to OpenAI's Deep Research using gemini-flash and jina reader
🗞️ Byte-Size Briefs:
University of Toronto generates full research report in one-shot using OpenAI’s Deep Research
R1-V open-sourced: 2B model beats 72B with 100 training steps.
🧑🎓 Deep Dive Tutorial
🔥 Build Your Own Free AI Operator: Automate Web Browsing Without Paying for Expensive Subscriptions
🥉 OpenAI Launched Deep Research for in-depth Research work, outranks every otehr model on Humanity’s Last Exam

🎯 The Brief
OpenAI launched Deep Research, a new ChatGPT feature for complex web research, delivering cited reports in under 30 minutes. It uses a fine-tuned o3 model. It becomes the absolute top-ranker on Humanity's Last Exam by achieving 26.6% accuracy where even o1 model scored only 9.1%.
It is essentially Google's Deep Research idea with multistep reasoning. May sometimes even take half an hour to complete its response. Its your 24/7 assistant who immediately becomes an expert on any topic surpassing even the the subject-matter experts.
⚙️ The Details
→ Deep Research is available for Pro users ($200/month) initially with 100 queries/month. It will expand to Plus and Team users soon. Tasks take 5-30 minutes, providing summaries from text, images, and PDFs.
→ It's powered by a version of o3 optimized for web browsing and data analysis, using reasoning to synthesize information from numerous online sources. This is aimed at professionals in finance, science, policy, and engineering for in-depth research.
→ Deep Research reports include citations and thinking summaries for verification. It excels at finding niche information. Trained using reinforcement learning similar to o1, it bridges the gap between quick summaries (GPT-4o) and detailed, verified research reports.
→ It returns MASSIVE well-researched reports, synthesized from many different sources, sometimes running 10k+ words.
A few examples you can try with it:
Read chapter 1 of War and Peace, analyze Tolstoy's character descriptions, and tell us what that says about his view of human nature.
Trawl through recent 10ks of of a Company to find unreported financial irregularities.
Understand US healthcare system and analyze issues around enforcement of the Sherman Act .
→ Unlike Google’s Advanced Reserach version (in Gemini app), which is a summarizer of many sources, OpenAI is more like engaging an opinionated (often almost PhD-level!) researcher who follows lead. So it is much more of an agentic solution than Google’s approach, which is much less exploratory (but examines far more sources).
→ If you want an overview, Google’s version is really good. If you want a researcher to go digging through a few sources, getting into the details with strong opinion, then go for Deep Research of OpenAI. Neither has access to paywalled research & publications which limits them (for now)
→ While powerful, Deep Research’s access is currently compute-intensive, and so expensive. And the 100 / month is a relative low limit for serious professionals who can take the most benefit from it.
🥊Anthropic challenges you to break their new jailbreaking defense!

🎯 The Brief
Anthropic has introduced Constitutional Classifiers, a security mechanism designed to defend LLMs against universal jailbreaks. They released a paper along with a demo where they challenge you to jailbreak the system. These classifiers are trained on synthetic data to detect and block harmful inputs and outputs while minimizing false positives. During 3,000+ hours of human red teaming, no universal jailbreak was discovered. Automated evaluations showed a jailbreak success rate reduction from 86% to 4.4%, with only a 0.38% increase in refusal rates and 23.7% higher compute costs. A public demo invites users to test vulnerabilities, aiming to refine the system further.
⚙️ The Details
→ Constitutional Classifiers are based on a predefined constitution that determines permissible and impermissible content, ensuring models reject harmful prompts.
→ Unlike traditional safety tuning, which relies on real-world attack samples, this method prepares against unseen jailbreaks by simulating variations in attack styles, languages, and obfuscation techniques.
→ The system was tested using Claude 3.5 Sonnet, with human and automated evaluations proving its robustness. Participants failed to achieve a universal jailbreak despite bug bounty incentives up to $15,000.
→ Automated tests on 10,000 synthetic jailbreak prompts showed Claude's native defenses blocked only 14%. With Constitutional Classifiers, 95% of jailbreaks were stopped.
→ The model refused only 0.38% more queries, meaning it avoids overblocking while enforcing strict security. Unlike naive keyword-based filtering, this classifier understands semantic intent, making it resilient to adversarial input manipulations like weird capitalization or obfuscated text.
→ Adding classifiers only increased compute by 23.7%, yet reduced jailbreak success rates from 86% to 4.4%. This trade-off is commercially viable, as it makes LLMs safer without crippling inference speeds or significantly increasing costs.
→ Future improvements aim to reduce refusals and compute costs while adapting defenses to emerging jailbreak techniques.
📡 Jina AI releases code to build an alternative to OpenAI's Deep Research using gemini-flash and jina reader
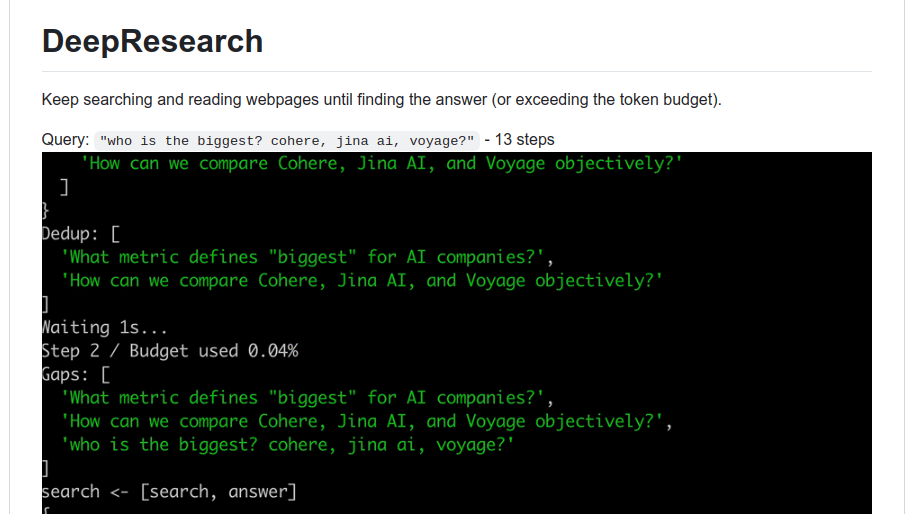
🎯 The Brief
It integrates Gemini API for reasoning, Brave/DuckDuckGo for search, and Jina Reader for content extraction from web pages, to autonomously search, read, and reason in a loop until an answer is found. The system dynamically processes queries, iterating through multiple steps while optimizing for token budget constraints. The approach resembles OpenAI’s Deep Research.
Build Your Own Free AI Operator: Automate Web Browsing Without Expensive Subscriptions
Tired of paying for AI-powered search tools? You can build your own AI operator that searches, reads, and extracts answers from the web for free using Gemini Flash, DuckDuckGo, and Jina Reader.
Here’s a simple step-by-step guide to set up an AI-powered browsing assistant in Node.js.
Step 1: Install Dependencies
You'll need: ✅ Gemini API (for LLM reasoning) ✅ DuckDuckGo/Brave API (for web search) ✅ Jina Reader API (for reading web pages)
Install Node.js and Required Packages Run the following:
git clone https://github.com/jina-ai/node-DeepResearch.git
cd node-DeepResearch
npm installSet up your API keys:
export GEMINI_API_KEY=your_gemini_key
export JINA_API_KEY=jina_your_key
export BRAVE_API_KEY=your_brave_key Optional, defaults to DuckDuckGoStep 2: Run Your First AI-Powered Search
Try a simple query:
npm run dev "Who is the CEO of OpenAI?"For multi-step reasoning, run:
npm run dev "Who is bigger: Cohere, Jina AI, or Voyage?"This triggers a recursive AI loop:
Searches the web for the answer
Reads relevant pages
Reasons over multiple steps
Returns a final answer
Step 3: Run as an API Server
Launch the server:
npm run serveQuery it via API:
curl -X POST http://localhost:3000/api/v1/query \
-H "Content-Type: application/json" \
-d '{"q": "Latest AI breakthroughs?", "budget": 1000000, "maxBadAttempt": 3}'Monitor the live response stream:
curl -N http://localhost:3000/api/v1/stream/YOUR_REQUEST_IDStep 4: Customize Your AI Operator
🔹 Modify reasoning steps in the agent.js file
🔹 Add new data sources (e.g., Wikipedia API)
🔹 Limit token budget to control API costs
🔹 Deploy it as a web service using Docker
🗞️ Byte-Size Briefs
University of Toronto Professor writes a detailed research report with a one-shot prompt to OpenAI’s just released o3 Deep Research. So no iteration and 10 minutes of thinking produced this report.
New surprising archtecture R1-V is released, and fully open-sourced. The project shows a 2B-parameter model surpassing a 72B-parameter counterpart in generalization tests. With only 100 training steps (vs. thousands in conventional methods), 30 minutes on 8 A100 GPUs and $2.62 total cost.
🧑🎓 Deep Dive Tutorial
🔥 Build Your Own Free AI Operator: Automate Web Browsing Without Paying for Expensive Subscriptions
This tutorial walks you through setting up Browser-Use WebUI, an open-source tool that lets you automate web browsing using AI—completely free and running on your own machine! Browser Use is the easiest way to connect your AI agents with the browser. It makes websites accessible for AI agents.
🛠️ Step 1: Install Prerequisites
Before we start, ensure you have Python 3.11+ installed. If not, download it from python.org.
Install uv for Python Environment We will use uv to create a virtual environment and manage dependencies efficiently.
uv venv --python 3.11Activate the environment:
# Mac/Linux:
source .venv/bin/activate
# Windows:
.venv\Scripts\activate🔧 Step 2: Install Dependencies
Install Browser-Use Package Browser-Use is the core AI-driven automation package. Install it with:
uv pip install browser-useInstall Playwright for Browser Automation Playwright enables AI agents to interact with websites. Install it with:
playwright install🤖 Step 3: Create Your AI Agent
Now, let’s write a simple AI-powered browsing agent that compares AI model prices online.
Create a new Python file, agent.py, and add the following code:
from langchain_openai import ChatOpenAI
from browser_use import Agent
from dotenv import load_dotenv
import asyncio
load_dotenv() Load API keys from .env file
# Define the LLM model to use
llm = ChatOpenAI(model="gpt-4o")
async def main():
agent = Agent(
task="Compare the price of gpt-4o and DeepSeek-V3",
llm=llm,
)
result = await agent.run()
print(result)
#Run the AI agent
asyncio.run(main())This script does the following:
Loads ChatGPT (GPT-4o) as the LLM model.
Creates an Agent that performs a web search comparing AI model prices.
Executes the agent using
asyncio.run().Prints the result.
🔑 Step 4: Set Up LLM API Keys
Your AI agent needs API keys to communicate with AI models. Store them in a .env file in the project directory:
OPENAI_API_KEY=your_openai_api_key
ANTHROPIC_API_KEY=your_anthropic_api_keyIf using other models, check LangChain’s documentation on setting up API keys.
🚀 Step 5: Run Your AI-Powered Browser Automation
Run the agent with:
python agent.pyYour AI assistant will now browse the web, find information, and return results—without any paid subscriptions!
🎯 Optional: Run with a Web UI
For a graphical interface, you can install Browser-Use WebUI and interact with your AI assistant visually.
Clone the Web UI repository:
git clone https://github.com/browser-use/web-ui.git
cd web-uiInstall dependencies & start the WebUI:
uv pip install -r requirements.txt
python webui.py --ip 127.0.0.1 --port 7788Open your browser and go to
http://127.0.0.1:7788
to interact with your AI assistant via the UI.
Congratulations! 🎉 You’ve successfully set up your own AI-powered browser automation tool—without paying for expensive subscriptions. Your AI agent can now search, compare, and interact with websites automatically.
🚀 Next Steps
Experiment with custom AI tasks (e.g., auto-filling forms, scraping data, or even controlling web apps).
Use other LLMs like DeepSeek, Gemini, or Anthropic for different AI capabilities.
Run the Web UI in Docker for a fully containerized experience.
That’s a wrap for today, see you all tomorrow.