

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (26-April-2026):
🗞️ OpenAI launched GPT-5.5 in ChatGPT and Codex.
🗞️ Today’s Sponsor: A super-massive 38.6TB dataset from TARS and other top Institutions will teach robots what contact actually feels like
🗞️ DeepSeek releases V4, the first open-source model to match a closed model on competitive programming, and a huge 1M-context window
🗞️ DeepSeek paper’s big idea is a new way to make very long-context LLMs much cheaper without giving up much ability.
🗞️ Anthropic just mapped the first large-scale link between AI use, productivity, and replacement fear.
🗞️ OpenAI launched GPT-5.5 in ChatGPT and Codex.
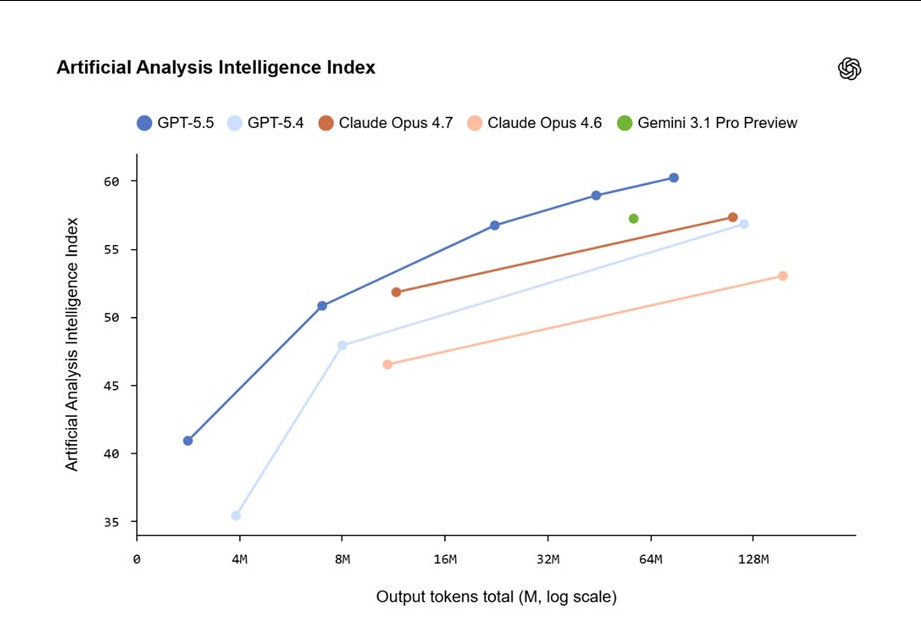
OpenAI launched GPT-5.5 and the even stronger GPT-5.5 Pro, its most capable frontier models so far. The main GPT-5.5 and GPT-5.5 Pro, internally nicknamed “Spud” during training, push long-horizon agentic AI further with better long-context reasoning, coding, spreadsheet and document handling, computer-use tasks, and scientific research workflows.
GPT-5.5 posted SOTA scores on several real-world benchmarks: 82.7% on Terminal-Bench 2.0 and 84.9% on GDPval. It scored 58.6% on SWE-Bench Pro, behind Opus 4.7 at 64.3%, but reviewers said that misses efficiency improvements and tokenizer differences that make GPT-5.5 faster and more reliable, helping it perform at the top level in production.
The GPT-5.5 system card argues that GPT-5.5 appears to make fewer accidental destructive moves during agentic work and gets more individual facts right, but it also produces denser answers with more claims, which means the total surface area for error can still expand.
OpenAI also launched ChatGPT for Clinicians, a clinical version of ChatGPT offered free to verified U.S. physicians, nurse practitioners, physician assistants, and pharmacists to help with clinical documentation and medical research.

The announcement came alongside HealthBench Professional, an open benchmark for measuring AI performance in clinical chat tasks like care consults and medical research.
OpenAI said the tool was built with feedback from hundreds of physician advisors, who together reviewed more than 700,000 model responses based on real-world clinical and patient interactions. Before launch, advisors evaluated 6,924 conversations across care delivery, documentation, and research scenarios. The company said doctors rated 99.6% of responses as safe and accurate.
🗞️ Today’s Sponsor: A super-massive 38.6TB dataset from TARS and other top Institutions will teach robots what contact actually feels like

Robots have been good at seeing for a while, but this work and the super-massive 38.6TB dataset from TARS and other top Institutions, is about the part that Robots still routinely miss: What contact actually feels like.
If you want to know why robots still find ordinary physical tasks hard, why providing additional tactile perception to robots actually make them perform worse? This is a good place to look: robotic manipulation has long lacked modeling of contact dynamics and effective utilization of tactile information.
OmniVTA is trying to solve a super important robotics problem: Understanding Contact.
They introduced OmniVTA and OmniViTac, a paired model-and-dataset effort aimed at one of robotics’ hardest problems: getting robots to handle contact-rich manipulation by not only seeing the world, but also predicting contact trends in advance (e.g., upcoming contact, changes in contact intensity, or slip risk) before the next mistake happens.
Robots do not struggle most when they are moving through empty space, they struggle when the world pushes back, and OmniVTA is designed for that moment.
The hard part in tasks like wiping, peeling, cutting, assembly, grasping, and in-hand adjustment is that vision misses the exact signals that decide success, because slip, friction changes, force buildup.
And tiny contact transitions often happen at the fingertip and unfold too fast or too subtly for cameras alone.
That is why this work starts with OmniViTac, a large synchronized visuo-tactile-action dataset with 21,879 trajectories across 86 tasks and 100+ objects, collected with multiple tactile sensors and two embodiments, a robot arm and a handheld system, so the data covers both robot-like motion and scalable human-centric data collection instead of staying trapped in one narrow setup.
What makes the dataset interesting is that it is organized around 6 physics-grounded interaction patterns rather than a random bag of demos, which means the data is grouped by how contact actually behaves.
And the paper shows this clearly through two recurring properties of touch in manipulation: spatial locality, where useful signals often live in small fingertip regions, and contact-driven dynamics, where the meaning of touch changes sharply once real physical interaction begins.
Research Paper: https://arxiv.org/pdf/2603.19201
Project Homepage: https://mrsecant.github.io/OmniVTA/
Huggingface Dataset: https://huggingface.co/datasets/tars-robotics/OmniVitac
🗞️ DeepSeek releases V4, the first open-source model to match a closed model on competitive programming, and a huge 1M-context window
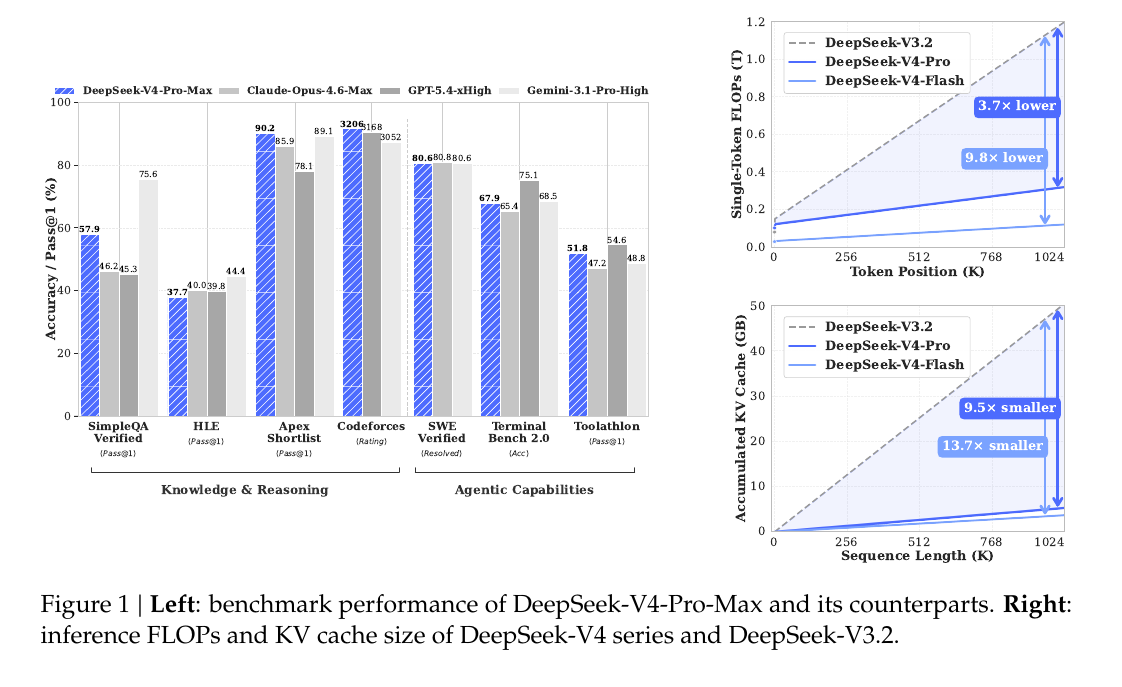
DeepSeek-V4 introduces a new open-source Mixture-of-Experts language model family: DeepSeek-V4-Pro at 1.6T parameters with 49B activated, and DeepSeek-V4-Flash at 284B parameters with 13B activated. The goal is to remove the computational bottleneck that stops existing AI models from processing extremely long contexts efficiently, while also pushing forward broader capabilities.

Generally this week’s open-model releases suggest the bottleneck in AI is moving from intelligence to systems design.
Open models are crossing a threshold where raw capability matters less than whether they can hold state, use tools, and stay coherent over long chains of work.
DeepSeek-v4 is the clearest example. Its real contribution is not the 1 million token context by itself, but the attempt to make that context economically usable through attention compression and KV-cache reduction.
Once long context stops crushing VRAM, the model stops behaving like a clever chatbot and starts looking more like infrastructure for codebases, manuals, and persistent working memory.
Kimi-K2.6 points in a different direction. Its significance is not just multimodality or strong coding scores, but reliability as an orchestrator inside agent swarms, where the hard problem is preserving intent across many delegated steps.
Agentic systems usually break before they hit the frontier of reasoning. They break on drift, bad task decomposition, weak handoffs, swollen context, and tools used at the wrong moment.
That is why these releases matter together. One pushes on memory economics, another on orchestration discipline, and both are more relevant to real products than a small benchmark lead ever is.
So the open-source race is no longer just about matching the smartest closed model. It is about who makes autonomy cheap, controllable, and durable enough to survive production.
At the same time, Washington has turned AI distillation into a diplomatic fight, accusing DeepSeek and other Chinese firms of extracting U.S. model behavior to build rivals.
"The US government has information indicating that foreign entities, principally based in China, are engaged in deliberate, industrial-scale campaigns to distil US frontier AI systems," Michael Kratsios, director of the White House Office of Science and Technology Policy, wrote in a memo
Distillation is a technique, where a smaller model studies a stronger model’s answers, letting it copy patterns cheaply without owning the original code or data.
U.S. officials say that can create low-cost models that look strong on narrow tests while losing parts of the original system’s range and safety design.
Beijing calls the charge baseless.
🗞️ DeepSeek paper’s big idea is a new way to make very long-context LLMs much cheaper without giving up much ability.

DeepSeek paper’s big idea is a new way to make very long-context LLMs much cheaper without giving up much ability.
Proposes a cheaper memory system for LLMs that need to read very long inputs.
The big result is that at a 1M-token context, DeepSeek-V4-Pro uses about 27% of the single-token compute and 10% of the KV cache of DeepSeek-V3.2, while still staying competitive on many major benchmarks.
Standard attention tries to compare the current token with a huge number of earlier tokens, and that cost grows so fast that long-context reasoning becomes too expensive.
DeepSeek-V4 changes that with a hybrid attention system where some layers compress the past and then look only at the most relevant compressed blocks, while other layers compress the past even more aggressively and use that cheaper summary directly.
That is a real algorithmic change because the model no longer stores and reads the whole past at full detail, and instead uses a layered memory system that keeps local detail nearby and uses compact summaries for older text.
A second innovation is that it adds a new kind of residual path, which is the route information takes across layers, and this is designed to stay stable when the model gets very deep and complicated.
A third innovation is using the Muon optimizer at large scale, which matters because these attention and routing changes are only useful if the model can still train fast and not become numerically unstable.
So the big deal is that the paper is proposing a new efficiency recipe for LLMs, where better memory handling changes the cost curve itself, which is why DeepSeek-V4 can reach 1M tokens while using far less compute and cache than DeepSeek-V3.2.
🗞️ Anthropic mapped the first large-scale link between AI use, productivity, and replacement fear.

Anthropic published one of the clearest reads yet on work and AI: 81,000 Claude users say the biggest effect is expanded scope, where people can now do tasks they could not do before.
The survey ties displacement anxiety closely to actual AI exposure. People whose jobs overlap more with what Claude can already do are more likely to worry that AI could replace them, and younger workers at the start of their careers worry the most.
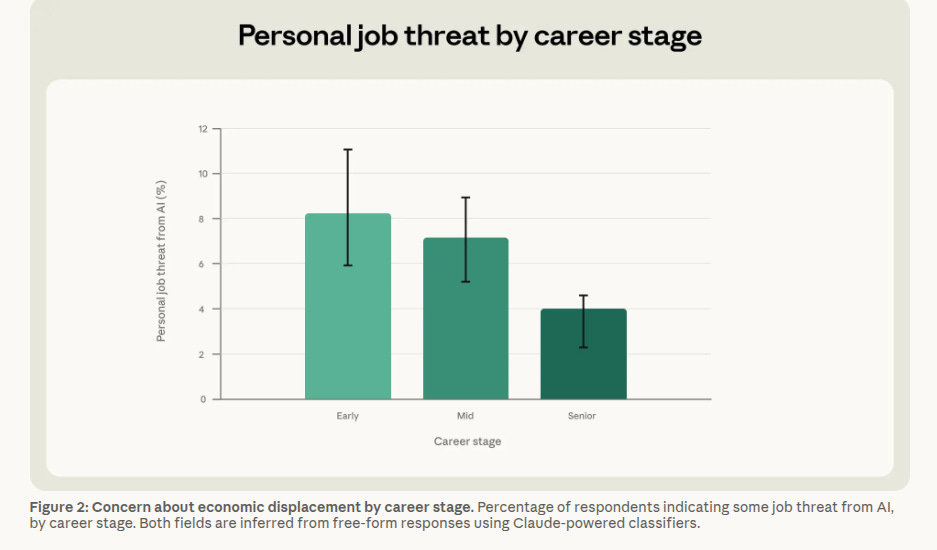
Reported productivity gains were broad and often large, but the gains were uneven, with high-wage workers usually reporting the biggest lift while legal and scientific workers lagged.
The central split is simple to picture: speed helps people finish known tasks faster, but scope changes what kind of worker they can be by letting them cross skill boundaries that used to block them.
Most respondents said the surplus mainly stayed with workers rather than firms, but senior professionals captured more than junior ones, and about 1 in 10 said employers were just extracting more output.
The sharpest paradox is that the people getting the fastest boost often fear replacement the most, while some people whom AI slows down, especially artists and writers, fear losing work as AI spreads anyway.
The sample likely leans optimistic because it comes from opt-in personal-account users rather than a broad employer-run dataset.
This is a strong signal that the first economic effect of AI may be widening the gap between workers who can absorb new scope and workers whose role boundaries are easier to erase.
That’s a wrap for today, see you all tomorrow.