
👨🔧 OpenAI launches Codex app to gain ground in AI coding race
OpenAI's Codex app launch, open-source LLM misuse risks, AI hurting human skill growth, inference memory bottlenecks, and enterprise SaaS stocks sliding over AI fears.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (2-Feb-2026):
👨🔧 OpenAI launches Codex app to gain ground in AI coding race
🚫 A new study warned of criminal misuse across thousands of open-source LLM deployments.
🧠 New Anthropic study, somewhat scary - AI definitely helps with speed, though it hurts skill growth if people start depending on it too much.
📡 New paper from Microsoft & Imperial College London shows, AI agent inference is starting to hit a memory capacity wall and adding more compute FLOPs will not fix it.
🛠️ American enterprise software stocks have taken a hit, losing about 10% of their value in a year due to fear of AI replacing traditional SAAS.
👨🔧 OpenAI launches Codex app to gain ground in AI coding race
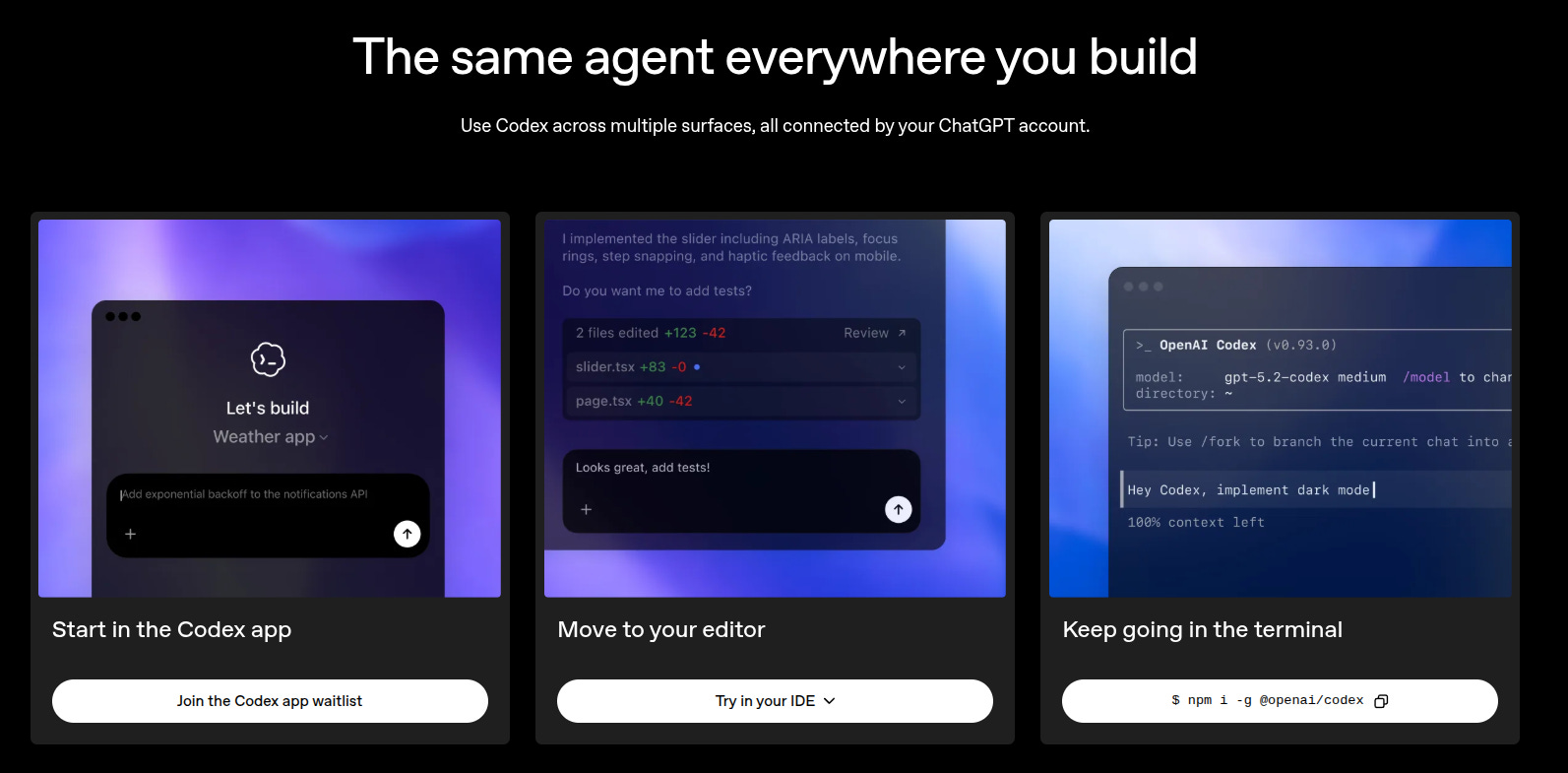
It is built for parallel, long-running work with human review without losing context, and to help users handle multiple AI agents at the same time. Terminal tools and integrated development environment (IDE) plug-ins are fine for 1 agent, but get messy with several agents and multi-day tasks.
This new app keeps project threads, shows diffs for review, and uses git worktrees, multiple working copies of 1 repository, so agents can edit in isolation. You can run several tasks in parallel, keep each task’s context, and review or steer their changes in 1 place, instead of juggling terminals, tabs, and lost threads.
It shares session history with the Codex command line interface (CLI) and IDE extension, so switching surfaces keeps the same setup. Skills are pre-made “recipes” for agents, they package the steps, tools, and instructions needed to do a task the same way every time.
The Automations with Codex i.e. the Codex feature for scheduling or triggering agent jobs inside the Codex workflow, let those Skills run automatically on a schedule or trigger, then put the results into a review queue so a developer can quickly approve, reject, or adjust things like issue triage and routine maintenance.
Agents are sandboxed to the working folder or branch, and ask before elevated actions like network access.
Codex is included in ChatGPT Plus, Pro, Business, Enterprise and Edu, and is temporarily on Free and Go, with higher rate limits on paid plans. OpenAI says usage doubled since mid-December 2025 and 1M developers used Codex last month.
Sam Altman also officially announced “To celebrate the launch of the Codex app, we doubled all rate limits for paid plans for 2 months! And added access for free/go.”
🚫 A new study warned of criminal misuse across thousands of open-source LLM deployments.

A lot of people installed Ollama to run AI locally, but many left it reachable from the public internet. A scan over 293 days found 175,108 public Ollama servers in 130 countries.
That means strangers online could send prompts to them, and sometimes do more than just get text back. Ollama is supposed to listen only on 127.0.0.1, which means only the same computer can reach it.
If it is set to 0.0.0.0, it listens on the whole network, and can become public by mistake. Researchers logged 7.23M sightings of these hosts, with 13% of hosts making 76% of sightings, so a small core stays up a lot.
About 48% advertised tool-calling, which can let a prompt trigger actions like running functions instead of only generating text. Some public setups also use retrieval, and prompt injection can trick the system into leaking data it pulls in. Open endpoints can be hijacked as free compute for spam or phishing, and a 5,000-host group averaged 87% uptime.
🧠 New Anthropic study, somewhat scary - AI definitely helps with speed, though it hurts skill growth if people start depending on it too much.
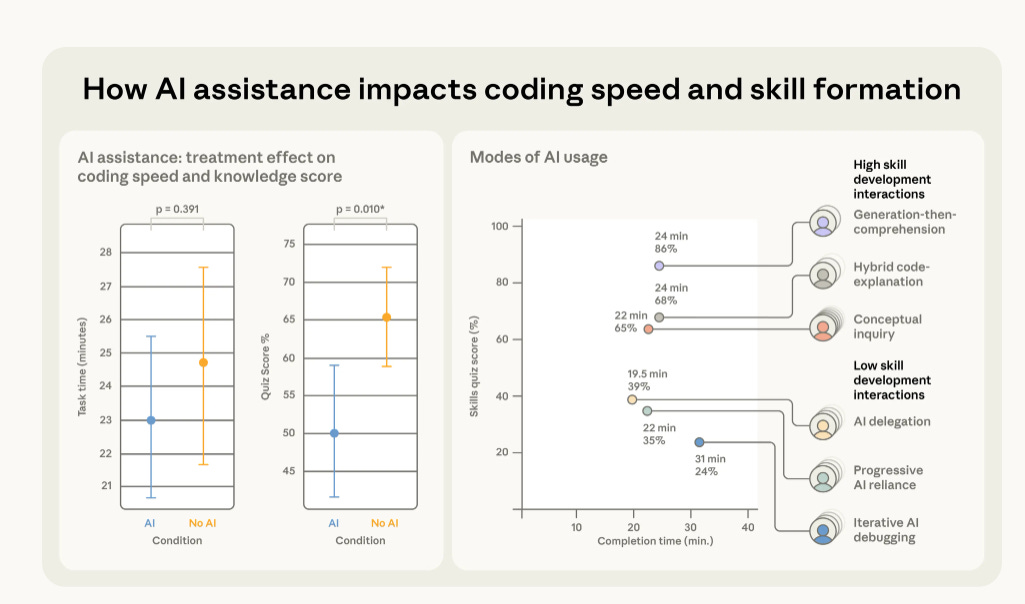
In a randomized-controlled trial, they took 52 developers who did not know a Python library called Trio, then gave them a small coding task to do.
Half the people could use an AI assistant during the task, and the other half could not. After they finished, everyone took a test with no AI allowed, so it measured what they actually learned in their own head.
The people who used AI scored lower by 17% on the test, about 50% vs 67%. The biggest weakness was debugging, which is basically finding and fixing what is broken.
A simple way to think about it is like using a calculator while learning math, you can get answers, but you might not build the skill to do it yourself. In this case, the no-AI group hit more errors and had to fix them, and that struggle seemed to train their brains for the test.
The surprising part is that the AI group did not even finish much faster on average, because some people spent a lot of time writing prompts to the AI. The researchers also noticed that some people used AI like a shortcut, and those people learned the least.
Other people used AI like a tutor, asking “why does this work” and then making sure they understood, and those people learned much more. The big deal is that AI can help you complete the assignment today while making you worse at handling problems tomorrow.
That matters because real life coding is full of reading old code and fixing bugs, and if AI does those parts for you, your skill can grow slower. It also matters in serious settings where you must catch mistakes in AI-written code, because you cannot spot a bug you do not understand.
If someone wants the benefits without the learning loss, the safer approach is using AI for explanations and hints, then writing and debugging the core parts yourself.
📡 New paper from Microsoft & Imperial College London shows, AI agent inference is starting to hit a memory capacity wall and adding more compute FLOPs will not fix it.

It reframes inference bottleneck with operational intensity (OI), operations per byte moved from dynamic random-access memory (DRAM), and capacity footprint (CF), bytes that must sit in memory per request.
With long interactive contexts, CF can blow past any single accelerator, and low OI during decoding means the hardware mostly moves data instead of computing.
The usual scaling playbook assumes a GPU cluster can cover everything by packing in more compute and more high bandwidth memory (HBM). That maps well to the roofline model, which predicts speed from peak compute and memory bandwidth given a kernel’s ops per byte, but it ignores whether the data even fits.
Agentic workflows break the fit assumption because the same base model can see very different prompt growth and state size across coding, web-use, and computer-use loops.
A coding agent can accumulate 300K-1M tokens over 20-30 environment interactions, and a computer-use agent can spend orders of magnitude more tokens in prefill than a chatbot.
At batch size 1 with a 1M context, a single DeepSeek-R1 request is estimated to need roughly 900GB of memory, and even a LLaMA-70B coding agent can exceed an NVIDIA B200 capacity ceiling.
During decode, key-value (KV) cache reads drive OI so low that the system becomes bandwidth-bound and capacity-bound at the same time.
The proposed default is disaggregated serving, splitting prefill and decode onto specialized accelerators and separate memory pools, connected by fast links like optical interconnects.
🛠️ American enterprise software stocks have taken a hit, losing about 10% of their value in a year due to fear of AI replacing traditional SAAS.

Economist published a piece on this.
“The carnage reflects growing nervousness over the future of the software industry in the age of artificial intelligence. “ On January 29th SAP fell 15% and ServiceNow fell 13%
Official data show business-software investment growth slowed from 12% in 2021-22 to 8% in 2024. The AI fear has 2 channels, coding tools that enable more in-house builds and AI-native startups that sell versions of old workflows.
Because business logic is moving from the software application to the AI agents. Currently, you buy software for its specific features and rules.
‘A recent paper by Fiona Chen and James Stratton of Harvard University examined the productivity of programmers using AI, and found that it resulted in an increase in output (measured by the number of tasks completed) only for those at companies selling software.’
This story argues the market is pricing an AI disruption that looks smaller than a normal macro slowdown. If AI lowers software build costs while incumbents bundle features into sticky suites, spending can rise even as unit prices fall.
This is a “worst case” scenario, not a base case. The point is that private credit is more exposed to borrower business models that AI could upend. UBS also estimates that about 35% of the $1.7T private credit market is tied to technology and services exposed to AI risk, so a shock there hits private credit first.
The UBS worst-case is a big deal because a large slice of private-credit borrowers sit in software and business-services niches that could see revenues, pricing power, or headcount compressed by AI, and because this market is relatively opaque and illiquid, stress can build fast.
If AI compresses margins or obsoletes products across software, IT services, and back-office heavy industries, cash flows of mid-market borrowers weaken first. Private credit is less traded, more concentrated by sponsor and sector, and often held in closed-end funds, so rising impairments can linger and compound before pricing clears.
There is a lot of AI-linked credit being created at the same time. The Bank for International Settlements estimates private credit loans to AI-related firms already exceed $200B and could reach $300B–$600B by 2030, which lifts system exposure.
For context on financing flow, private lenders and banks are actively funding AI build-outs.
That’s a wrap for today, see you all tomorrow.