
📢 OpenAI Released GPT-Realtime API updates for production voice agents
GPT-Realtime API is production-ready, OpenAI drops official prompting guide, Microsoft’s AI turns text into podcasts, and Karpathy shares infinite synthetic data trick from textbooks.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (28-Aug-2025):
📢 OpenAI Released GPT-Realtime API updates for production voice agents
👨🔧 OpenAI also published their exhaustive official Realtime Prompting Guide.
🔊 Microsoft's latest AI project can generate a 90-minute podcast in English or Mandarin from nothing but text — and anyone can try it out
🧑🎓 Deep Dive: Andrej Karpathy just explained a great way to generate infinite Synthetic data from text books
📢 OpenAI Released GPT-Realtime API updates for production voice agents
OpenAI took the Realtime API out of beta, added a new speech-to-speech model called gpt-realtime, and turned on 3 big platform features, MCP tool support, image input, and SIP phone calling, so you can run true production voice agents on web, mobile, or the phone network.
🔌 Support for remote Model Context Protocol (MCP) servers
🖼️ Image input
📞 phone calling through Session Initiation Protocol (SIP),
♻️ Reusable prompts
gpt-realtime was trained with customers to excel at real-world tasks like support, personal assistance, and education
Instead of the old stack where 1 model turns speech into text, a second model thinks, then a third model turns text back into speech, gpt-realtime takes audio in and produces audio out with a single model, which cuts round trips and keeps subtle cues like pauses, laughs, and tone. It’s better at:
Following instructions
Calling tools
Natural, expressive speech
Understanding cues (like laughs)
Switching languages
Where it got smarter
The model can capture non-verbal cues (like laughs), switch languages mid-sentence, and adapt tone (“snappy and professional” vs. “kind and empathetic”). The model also shows more accurate performance in detecting alphanumeric sequences (such as phone numbers, VINs, etc) in other languages, including Spanish, Chinese, Japanese, and French.
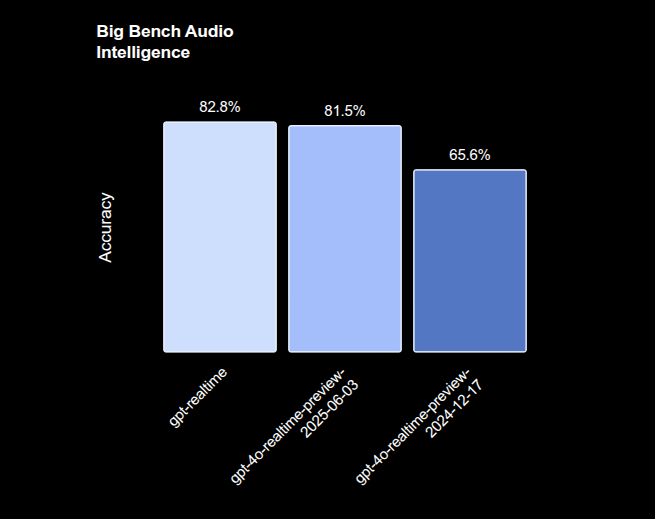
On reasoning with audio input it scores 82.8% on Big Bench Audio, on instruction following it hits 30.5% on the MultiChallenge audio eval, and on function-calling with audio prompts it reaches 66.5% on ComplexFuncBench, all up from prior releases.
In the livestream demo, the team showed emotional range, language switching in a single reply, strict policy following for a refund cap of $10, and image understanding for a safety check on a photo of a child, these are exactly the behaviors the new model was trained to honor, such as reading scripts word-for-word and repeating long alphanumeric strings.
For Developers:
Starting Thursday, the Realtime API and the new gpt-realtime model are available to all developers. MCP tools, plug-and-play, you point the session at a remote Model Context Protocol server, the platform wires tool calls for you, which means you can add or swap capabilities without custom glue code.
Image input in a voice session, you can attach a screenshot or photo to the live conversation, the model grounds answers in what it sees, and the platform treats each image like a message, not a video stream, so you control when it looks and what it sees.
SIP calling, you can connect to the phone network, PBX, or desk phones directly from Realtime, so a single agent can handle web voice and real phone lines with the same behavior and policies.
Asynchronous function calling, the model keeps talking naturally while a tool runs in the background, so long database calls or third-party APIs do not stall the conversation.
Reusable prompts and smarter context control, you can save developer messages and tool setups, then set token limits that truncate older turns in bulk to hold cost down during long calls.
Privacy and residency, EU data residency is supported, and enterprise privacy commitments apply across Realtime, with active classifiers that can halt harmful sessions and preset voices that reduce impersonation risk.
Why this is interesting if you use the API
You get lower latency because there is no extra hop between speech-to-text and text-to-speech, you get higher compliance because the model follows narrow instructions like “read this disclaimer exactly,” and you get richer interaction because it detects laughs, hesitations, and mixed-language turns, all of which make support, tutoring, or sales calls feel less robotic.
Under the hood view
Audio is sliced into short chunks and turned into discrete tokens the model can process, the model reasons over the running stream plus recent conversation state, and then it emits audio tokens that the client renders as speech, this single loop is why timing and prosody survive instead of getting flattened by a text round-trip.
Function calling is simple to picture, the model decides “I should call get_shipping_quote with zip=94016,” the platform runs that function, returns the result as data, and the model weaves it into the next spoken sentence, with the new async setup it can keep chatting while the function completes, then incorporate the result when it lands.
MCP is basically a standard way to expose tools and data to models over a server, so instead of baking integrations into your app, you register an MCP server and the Realtime session discovers and calls those tools, which shortens integration time and keeps your agent modular.
SIP is the common internet telephony protocol, so by speaking SIP the agent can place and receive real phone calls, transfer to agents, or join a queue, without a third-party voice gateway in between.
Voice quality and control
OpenAI added 2 new voices, Cedar and Marin, and refreshed the existing 8 voices so the model can change pace, tone, and style on command, for example “snappy and professional” or “kind and empathetic,” and it can repeat long IDs and codes reliably in multiple languages.
Costs and availability
There is a 20% price cut versus the prior preview, $32 / 1M audio input tokens with $0.40 / 1M cached input tokens, and $64 / 1M audio output tokens, and the model is available to all developers now in the API and in the Playground.
What you can build right away
A voice agent on your website that sees user screenshots during a support call, explains what is on screen, calls your order system through MCP, and reads a legally required script verbatim before making changes, that is 1 project that now needs less custom piping and gives a smoother call flow because the agent can keep talking while tools run.
A customer-support phone line that is 1 application only, because the same agent handles both browser voice chats and real SIP calls, it can verify accounts by reading back long alphanumeric strings and can escalate to a human if the conversation crosses a policy boundary.
A tutoring or coaching helper that mixes languages mid-sentence when that helps the learner, and that adjusts tone on request, which the demo showcased live with rapid style and language shifts.
Key takeaways, compressed
The Realtime API is generally available with gpt-realtime, single-model speech-to-speech brings lower latency and better nuance, tool use is stronger and non-blocking, MCP, image input, and SIP unlock practical deployments, and prices dropped by 20% with clear token controls for long sessions.
If you are deciding whether to try it, start by wiring a small flow with 1 MCP tool, 1 SIP entry point, and reuse a prompt across sessions, then measure latency and cost with caching on input, you will get a good feel for the new stack in under 1 afternoon.
👨🔧 OpenAI also published their exhaustive official Realtime Prompting Guide.

This is for gpt-realtime, their newly launched speech-to-speech model in the API. Realtime model benefits from different prompting techniques that wouldn't directly apply to text based models.
Structure the system prompt into clear, labeled sections, each focused on a single purpose like role, tone, context, pronunciations, tools, rules, conversation flow, and safety.
State the role and objective explicitly so the model consistently knows its identity and what success looks like.
Tune speech behavior directly by setting target length like 2 to 3 sentences, pacing guidance to sound faster but not rushed, and a strict language lock to prevent switching.
Provide short sample phrases to anchor style, then add a variety rule to avoid repetitive openings and confirmations.
Include reference pronunciations for tricky terms and require character by character or digit by digit read backs for numbers, codes, and IDs with confirmation loops.
Tighten instructions by removing ambiguity, defining terms, resolving conflicts, and using critique prompts to iterate.
Handle unclear audio deterministically by only responding to clear input and asking for clarification in the same language when speech is unintelligible.
Specify tools precisely by listing only real tools, stating when to use or avoid each, and choosing whether to speak a short preamble or ask for confirmation before calls.
If you split duties between a thinker and a responder, require the responder to rephrase the thinker text into a short, natural, speech first reply.
Organize the conversation as states with goals, instructions, exit criteria, and sample phrases so progress is clear and consistent.
For complex scenarios, use a JSON state machine or dynamically update session rules and tool lists so the model sees only what is relevant in each phase.
Define concrete escalation triggers such as safety issues, explicit human requests, strong frustration, or repeated failures like 2 failed tool calls or 3 consecutive no input events.
When escalation triggers fire, speak a brief neutral line and hand off to a human.
🔊 Microsoft's latest AI project can generate a 90-minute podcast in English or Mandarin from nothing but text — and anyone can try it out

Microsoft Unveils VibeVoice, an Open-Source Text-to-Speech AI Model. VibeVoice can produce up to 90 minutes of synthetic dialogue with as many as four distinct speakers. GitHub and Huggingface.
- VibeVoice-1.5B, a 2.7B-parameter TTS that makes long, multi-speaker audio with stable voices and natural turns.
- It handles up to 90 minutes and up to 4 speakers, keeping each voice steady across the whole session.
- The key is continuous acoustic and semantic tokenizers at 7.5 Hz, compressing audio by 3200x while preserving the cues that matter.
- It targets long-context scaling, speaker consistency, and turn-taking that typical TTS systems struggle to keep aligned.
- An LLM drives dialogue context and a next-token diffusion head renders high-fidelity acoustic features that decode back to waveform.
- This release pairs Qwen2.5-1.5B with a sigma VAE style tokenizer stack and a 4-layer, ~123M diffusion head.
- A length curriculum grows context to 65,536 tokens, which lets the model track pacing and callbacks across long scenes.
- MIT License for research with an audible disclaimer and an imperceptible watermark in every output, plus abuse logging and provenance checks.
- Out-of-scope includes voice impersonation without consent, real-time voice conversion, non-speech audio, languages beyond English and Chinese, and no overlapping speech synthesis.
Overall, a strong open baseline for podcast automation, and the big things to watch are stability over full 90-minute runs and how well multi-speaker timing holds under messy prompts.
Special note on production use.
We do not recommend using VibeVoice in commercial or real-world applications without further testing and development. This model is intended for research and development purposes only. Please use responsibly.
🧑🎓 Deep Dive: Andrej Karpathy just explained a great way to generate infinite Synthetic data from text books

Karpathy’s point is to rebuild textbooks and courses in an LLM-first format so a model can actually study, practice, and get graded, not just read a pdf.
Here is the idea. Take a normal pdf textbook, then rebuild it so an LLM can actually study it, practice it, and get graded on it without a human squinting at a pdf. LLM-first textbooks turn education content into a training loop with structure, tools, and ground truth. That is how an LLM stops parroting a book and starts studying it.
Synthetic data expansion. For every specific problem, you can create an infinite problem generator, which emits problems of that type. For example, if a problem is "What is the angle between the hour and minute hands at 9am?" , you can imagine generalizing that to any arbitrary time and calculating answers using Python code, and possibly generating synthetic variations of the prompt text.
Human-first vs LLM-first
Human-first content is built for our eyes. It mixes fonts, sidebars, footnotes, cross references, and figures sprinkled across pages. LLM-first content strips that noise and keeps structure that a model can consume. You keep the meaning, but you store it in clean text, clean references, and machine-checkable answers.
What an LLM-ready textbook looks like
The prose moves into a single markdown document. Headings become a clear tree. Bold and italics carry emphasis that the model can learn. Tables and lists stay as text tables and lists. Figures are saved as separate images with short alt text that says what they show, not pixels.
Every cross reference turns into a direct link like “see definition X” so the model can jump, retrieve, and reason without guessing where “the figure above” lives.
Worked examples become SFT fuel
All solved problems convert into pairs for supervised fine-tuning (SFT). The input is the problem plus any needed context. The output is the full chain of steps in plain language. You do not paste symbols. You teach the move in text. This gives the model grounded patterns for how to think through that topic.
Practice problems become an RL playground
Unsolved problems plus an answer key become an environment for reinforcement learning (RL). The reward is simple. If the model’s final answer matches the key or passes a programmatic checker, give a positive score, otherwise give a negative score. If a free response needs judging, you add a small LLM judge that compares structure, units, and reasoning against the key, then emits a numeric score. Now the model can practice, get feedback, and iterate.
Synthetic generators keep the teacher honest
Each problem template gets a programmatic generator. You write a small script that emits new instances and computes the correct answer with code. Take the classic clock angle prompt. The generator samples a time, computes the angle using code, and stores both. No equations are pasted in the dataset. The model sees 100s or 1,000s of controlled variations with guaranteed ground truth. Coverage improves because you can sweep edge cases, trick cases, and mixed concepts, not just the 5 examples a human wrote.
RAG and MCP make it legible at runtime
All exposition and figures get indexed for retrieval augmented generation (RAG). During training and evaluation the model can fetch the exact definition or theorem it needs. You can also expose the corpus through Model Context Protocol (MCP) so tools can serve chapters, figures, and answer checkers on demand. That turns a course into a set of callable tools, not a dead file.
How the LLM “takes” the course
First, it reads the cleaned textbook through RAG so answers cite the right passages.
Next, it trains on the solved examples with SFT, which teaches step shapes and phrasing. Then, it practices on the unsolved set with RL, which tightens final answers under a reward tied to the answer key or checker.
Finally, it sits for a held out exam with strict graders that only know the rubric and the key.
Why this beats plain pdf-to-text
The traditional pdf-to-text ingestion pipeline stops at “convert the pdf and dump that raw text into pretraining,” and the loss mainly rewards reproducing the next phrase, not verifying a numeric answer, not pointing to an exact definition, not following a marked step template. You still learn useful knowledge, but the signal is weak on explicit skills because there is no ground truth checker, no linked references, no structured input-output pairs.
Karpathy’s pipeline goes past extraction and builds structured supervision. The exposition becomes clean markdown with stable IDs so retrieval can fetch the exact definition on demand. Worked examples become supervised pairs that teach step shapes. Practice problems become a reinforcement environment with programmatic graders that give rewards. Generators create fresh variants with code-verified answers so coverage and difficulty are controllable.
A quick mental picture of the pipeline
You start with 1 textbook. You export 1 markdown corpus, 1 image set, 1 solved set for SFT, 1 unsolved set for RL, and 1 bank of generators with code-based checkers. You index everything for RAG and expose it with MCP. You now have a full course the model can actually study.
Practical notes that make or break it
Keep references stable so a link in the solved set points to the same definition every time. Store units and accepted formats so graders do not mark correct answers as wrong. Deduplicate near clones so the model learns patterns, not noise. Log every generator seed and checker version so results are reproducible. Treat graders as real software with tests, because the reward is your contract with the model.
That’s a wrap for today, see you all tomorrow.