
🚨 OpenAI releases o3-pro, 87% cheaper than o1-pro & slashes o3 pricing by 80%
OpenAI's o3-pro beats top models in math/coding, gets 80% cheaper; Mistral drops reasoning model; agents start browsing the web smartly.

Read time: 9 min.
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (10-Jun-2025):
🚨 OpenAI releases o3-pro, tops Gemini 2.5 and Claude 4 in science and math, crushes coding reliability with 2301 Elo
🔥 OpenAI slashes o3 pricing by 80% to $2 input / $8 output
📡 Some Strategies to handle OpenAI’s o3-pro
📣 Mistral’s first reasoning model, Magistral, launches with large and small Apache 2.0 version
🛠️ AI agents from Yutori now watch the web for you, conditionally
🚨OpenAI releases o3-pro, tops Gemini 2.5 and Claude 4 in science and math, crushes coding reliability with 2301 Elo

o3-pro is rolling out now for all chatgpt pro users and in the api.
OpenAI slashed o3 API prices by 80% and unveiled o3-pro as its new top reasoning model.
→ The o3-pro is a more capable variant of its reasoning-focused o3 model, now replacing o1-pro in the ChatGPT model picker for Pro and Team users. Enterprise and Edu users get access next week. It's also live in the API.
→ A 200k-token context window with up to 100k output tokens leaves plenty of room for entire project histories or large codebases
→ API pricing is $20 per million input tokens and $80 per million output tokens. That’s about 750K words per million input tokens. Same model architecture as o3, but tuned for higher reliability and precision.
→ o3-pro excels in "4/4 reliability" benchmarks: 90% in AIME (math), 76% in GPQA Diamond (PhD-level science), and a 2301 Elo score in Codeforces (coding). This means it gets all four tries correct, not just one.
→ For pass@1 (correct on first try), o3-pro hits 93% on AIME, 84% on GPQA, and 2748 Elo in Codeforces. These numbers beat both Claude 4 Opus and Gemini 2.5 Pro in OpenAI’s internal tests.
In expert evaluations, reviewers consistently prefer OpenAI o3-pro over o3, highlighting its improved performance in key domains

→ In human evaluations, reviewers preferred o3-pro over o3 in 64% of tasks, including scientific analysis (64.9%), programming (62.7%), and writing (66.7%). Gains were most prominent in clarity, accuracy, and instruction-following.
→ o3-pro supports tools like Python, browsing, file analysis, image reasoning, and memory. However, it's slower than o1-pro, can’t generate images, doesn’t support Canvas, and has temporary chats disabled due to a technical issue.
→ It’s optimized for consistency over speed, making it better suited for high-stakes, correctness-sensitive tasks like code, research, and data analysis.
Pricing vs o1-pro: Massive reduction in cost… the intelligence/cost ratio continues to improve!
o3-pro API pricing: $20/million input tokens, $80/million output tokens - 87% cheaper than o1-pro!
Availabiity
OpenAI o3-pro is available in the model picker for Pro and Team users starting today, replacing OpenAI o1-pro. Enterprise and Edu users will get access the week after. As o3-pro uses the same underlying model as o3
🔥 OpenAI slashes o3 pricing by 80% to $2 input / $8 output

o3: Input $2 / Output $8 (from your screenshot)
o3-pro: Input $20 / Output $80
o4-mini: Input $1.10 / Output $4.40
o1-pro: Input $150 / Output $600
→ OpenAI just dropped prices for its o3 reasoning model by 80%, from $10 to $2 per million input tokens and $40 to $8 per million output tokens. Cached inputs now cost only $0.50 per million. This makes o3 way more accessible for experimentation and deployment. Here’s the detail pricing page.
→ o3 is OpenAI's top reasoning model. It's built for complex, logic-heavy tasks. Despite the steep discount, it maintains competitive performance against Claude Opus 4 and Gemini 2.5 Pro.
→ The new pricing now undercuts Claude Opus 4, which charges $15 input and $75 output, and undercuts Gemini Pro’s $1.25–$2.50 input and $10–$15 output. Only DeepSeek models offer cheaper rates but with tradeoffs in performance.
→ o3 also introduced Flex mode, which lets developers choose synchronous processing at a rate of $5 input / $20 output per million tokens, providing flexibility for latency-sensitive workloads.
→ In benchmark tests by Artificial Analysis, o3 ran the full task suite at $390, cheaper than Gemini 2.5 Pro ($971) but slightly more expensive than Claude 4 Sonnet ($342). This narrows the cost-performance gap significantly.
→ o3 is available via API and Playground, with no minimum spend required. Developers, startups, and researchers can now work with top-tier reasoning power on low budgets.
→ OpenAI’s move forces pricing pressure on rivals and signals a shift: high-performance LLMs are getting cheaper, fast.
📡 Strategies for putting o3-pro model to work

→ o3-pro shines when you stop chatting and start feeding it full background. Long transcripts, product roadmaps, and raw meeting notes give the model the material it needs to build a structured plan. Smaller prompts rarely expose the gap; the intelligence surfaces only after you supply that deep context.
🛠️ Tool sense, not tool spam
Earlier o-series releases could list every function in sight, sometimes hallucinating access they never had. o3-pro is better at reading the room: it names only real tools, asks clarifying questions when unsure, and selects Python or web search only when needed.
OpenAI attributes this to vertical reinforcement learning work—internally branded Deep Research and Codex—which trains the model to reason first, then decide if a call is worthwhile
In practice this means fewer wasted calls, faster end-to-end jobs, and more reliable chaining when you let o3-pro operate as an orchestrator.
📏 Context window tactics
A 200k window sounds endless, yet real workflows still hit limits. Pack dense information: use bullet logs or tables for repetitive data, then spell out the goal clearly at the end. Chunk large PDFs into ordered passages so the model can cite sections precisely. Because token costs drop sharply with the new pricing, stuffing background is now affordable even for independent developers
⚖️ Model match-ups
Compared with Gemini 2.5 Pro and Claude Opus, o3-pro’s answers feel less generic and more decisive, especially on business strategy and code reviews. Gemini remains quicker on short chats, while Claude often writes longer prose. For raw reasoning with tool autonomy, o3-pro sets a higher bar. The o3 model already orchestrates search, Python, and vision tools; the pro tier simply does it with greater precision
⚡ Shortcomings you should expect
When context is thin, o3-pro can over-analyze and miss obvious direct answers—sometimes slower than o3 in straight SQL queries
🚀 Final word on Putting it to work
• Gather every relevant document, meeting note, and metric.
• Frame a single explicit objective: “Produce a quarterly growth plan with cut-offs.”
• Let o3-pro run end-to-end; resist the urge to interrupt mid-thought.
• Inspect its plan, then loop with specific follow-ups rather than re-explaining background.
With cheap tokens, vast memory, and a cooler head for tool use, o3-pro finally makes the “LLM as analyst” workflow practical for everyday teams. Give it the context and let it cook.
📣 Mistral’s first reasoning model, Magistral, launches with large and small Apache 2.0
⚙️ The Details
→ Mistral just released Magistral, its first family of reasoning-focused LLMs. It comes in two variants: Magistral Small (24B parameters, open-sourced under Apache 2.0) and Magistral Medium (proprietary, enterprise-grade).
→ Magistral Small is freely downloadable and usable for any purpose.
→ Magistral Medium targets enterprise use cases and is accessible via Le Chat, La Plateforme API, and soon on major cloud services. It’s priced at $2 per million input tokens and $5 for output, which is cheaper than Claude Opus 4 and Gemini 2.5 Pro for outputs, but more expensive than Mistral Medium 3.
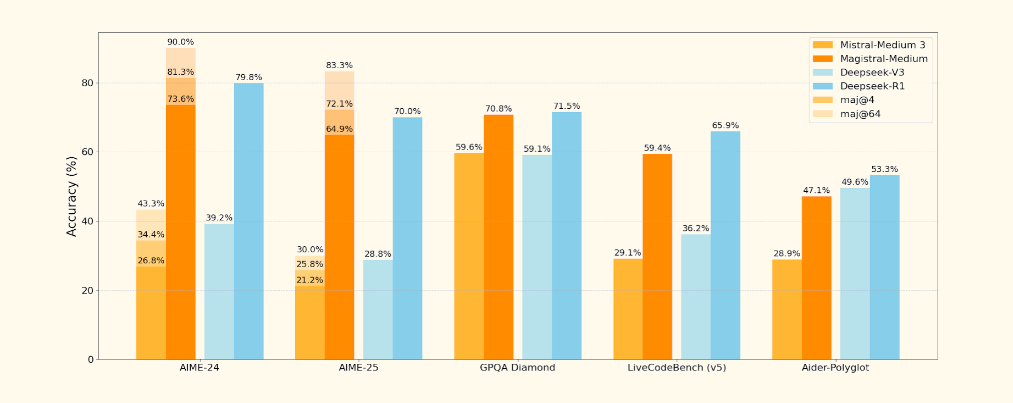
→ On benchmarks, Magistral Medium scores 73.6% on AIME-24, rising to 90% with majority voting. Magistral Small scores 70.7% and 83.3% respectively. It performs competitively but doesn’t top the charts on all tasks — Gemini and Claude still lead in some benchmarks like GPQA and LiveCodeBench.
→ Key differentiators include traceable chain-of-thought, multilingual reasoning in 8+ languages, and 10x faster responses in Le Chat due to its new Flash Answers and Think Mode.
→ Applications range from code generation, legal and financial reasoning to creative writing. Mistral is also pitching Magistral for regulated sectors where verifiable, auditable reasoning is essential.
Availability
→ Magistral Small is fully open-source and available under the Apache 2.0 license. You can download it from Hugging Face and run it locally or on your infrastructure without restrictions — including for commercial use.
→ Magistral Medium is proprietary. You can try out a preview version of Magistral Medium in Le Chat or via API on La Plateforme. Also available on Amazon SageMaker now. Support for Azure AI, Google Cloud Marketplace, and IBM WatsonX is coming soon. For on-prem or enterprise deployment, Mistral offers direct sales support.
Associated Research Paper
The official launch is supported by a detailed research paper. Magistral trains a base LLM with pure on-policy reinforcement learning on text, enforcing reasoning tags and achieving significant accuracy gains without trace distillation.
⚙️ The Core Concepts: Magistral uses a group relative policy optimization that compares multiple outputs per prompt. It removes divergence penalties, normalizes token losses and advantages, and raises the upper clipping threshold to reinforce rare but important reasoning steps.
🏗️ Scalable Reinforcement Learning Pipeline: Generators continuously produce completions and send them to verifiers that score formatting, correctness, length and language consistency. Trainers update model weights without pausing generators by broadcasting new weights asynchronously, ensuring that generations remain on policy.
🗂️ Data Curation: Magistral filters math problems through format checks and a two-stage difficulty assessment, and selects code tasks with reliable test suites. As the model improves, the data pipeline increases problem difficulty to maintain a learning challenge.
🛠️ AI agents from Yutori now watch the web for you, conditionally
→ Scouts is a new tool from Yutori that lets users deploy persistent AI agents to monitor public web pages and APIs. These agents spot changes, compare versions, and trigger alerts only when conditions are met. Everything runs via simple prompts.
→ A plain-language prompt spins up a Scout agent. For example: “Notify me when Sony WH-1000XM4 drops below $200 on Amazon.” The system handles pagination, scraping, DOM diffs, rate-limiting, and layout churn automatically.
→ Scouts provide deterministic triggers (e.g. "daily at 10am" or "only if price < $800"), traceable crawl histories, and automatic unsubscribe features. They’re built to handle real-world noise like A/B testing and frontend changes.
→ Example use-cases include price drop trackers, ticket availability, new Kaggle competitions, GitHub repo rankings, class slots, and crypto alerts—all with precise control on timing and filtering. Try it out here: yutori.com
That’s a wrap for today, see you all tomorrow.