
🗞️ OpenAI shipped blazing-Fast GPT-5.3-Codex-Spark coding model
DeepReinforce RL agents beating Anthropic’s hiring tests, Karpathy’s 243-line transformer, Ant’s 2.5T Ring-1T review, and the fast-rising autonomous OpenClaw agent story getting wilder
Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (14-Feb-2026):
🗞️ OpenAI shipped blazing-Fast GPT-5.3-Codex-Spark coding model
🗞️ AI agents from DeepReinforce just blow past Anthropic’s hiring benchmarks by running RL autonomously
🗞️ Andrej Karpathy Built a Working Transformer in 243 Lines of Code, pure Python, built from scratch with no dependencies.
🗞️ Ant Group released Ring-1T-2.5 Trillion Parameter Open Source Thinking Model Review
🗞️ A viral story about AI Agents getting both smarter and more independent, fast with the sensational OpenClaw AI agent.
🗞️ OpenAI shipped blazing-Fast GPT-5.3-Codex-Spark coding model
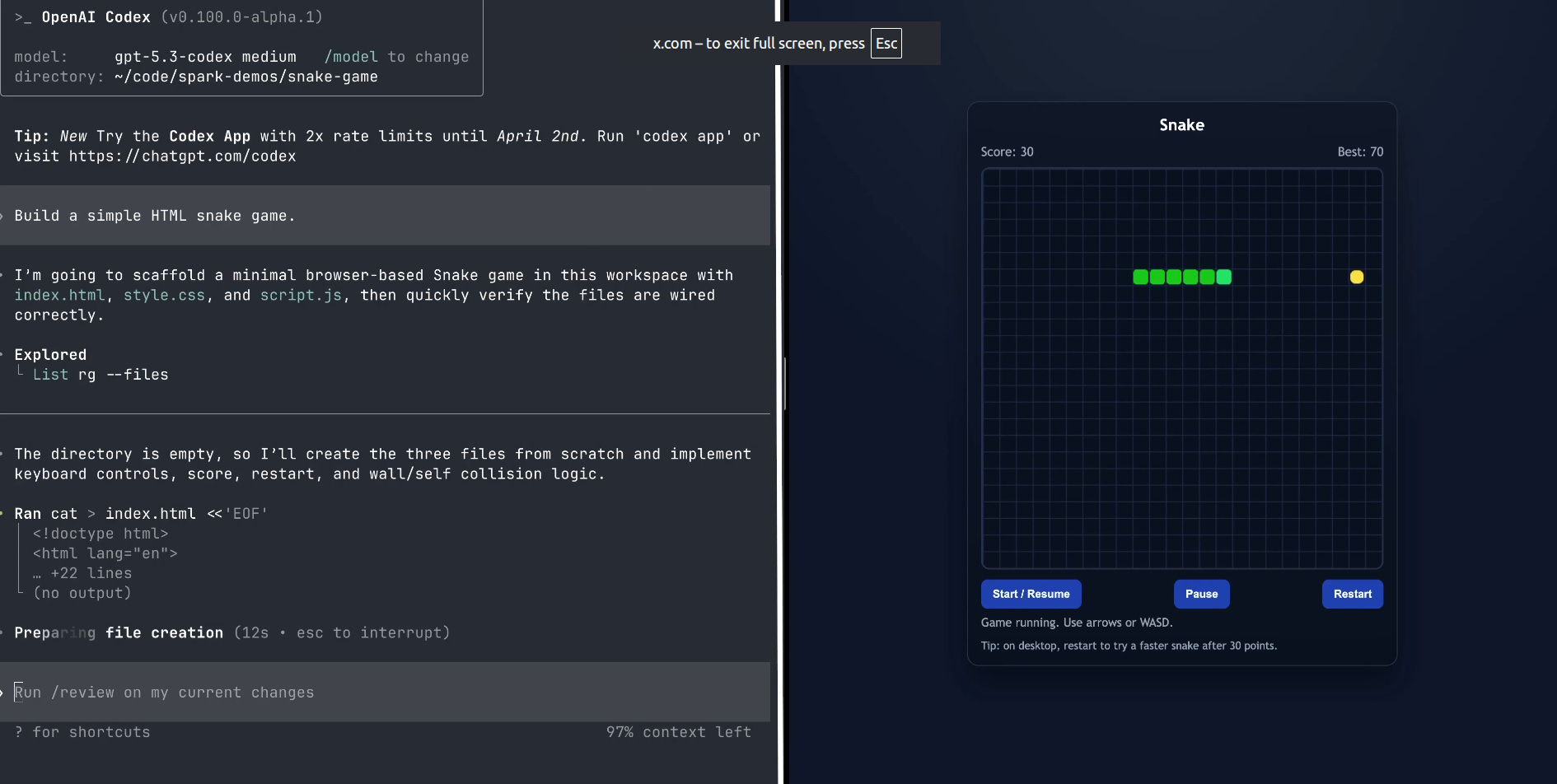
Codex-Spark is served on Cerebras hardware as a latency-first tier, using a purpose-built accelerator for high-speed inference so interactive coding edits feel near-instant, in its first major move beyond Nvidia.
It targets near-instant interaction, streaming more than 1,000tokens/s with a 128,000-token, text-only context window.
It is faster than GPT-5.3-Codex but scores lower on agentic benchmarks, which test multi-step tool-using software tasks, so it is aimed at quick edits rather than long autonomous runs.
So, speed gains come with capability tradeoffs that OpenAI says developers will accept.

In coding tools, latency comes from both model compute and the request pipeline, including time-to-first-token, the delay before the first output appears, and tool calls over the network.
Cerebras wafer-scale inference serves as a latency-first tier that can reduce cross-device communication compared with multi-GPU inference.
OpenAI added persistent WebSocket sessions, a long-lived client-server connection, and Responses API optimizations, cutting overhead per client-server round trip by 80%, per-token overhead by 30%, and time-to-first-token by 50%.
To stay fast, Codex-Spark defaults to minimal targeted edits and does not run tests unless asked.
Availability
Codex-Spark is rolling out today as a research preview for ChatGPT Pro users in the latest versions of the Codex app, CLI, and VS Code extension.
Because it runs on specialized low-latency hardware, usage is governed by a separate rate limit that may adjust based on demand during the research preview.
In addition, they are making Codex-Spark available in the API for a small set of design partners to understand how developers want to integrate Codex-Spark into their products.
Benchmarks
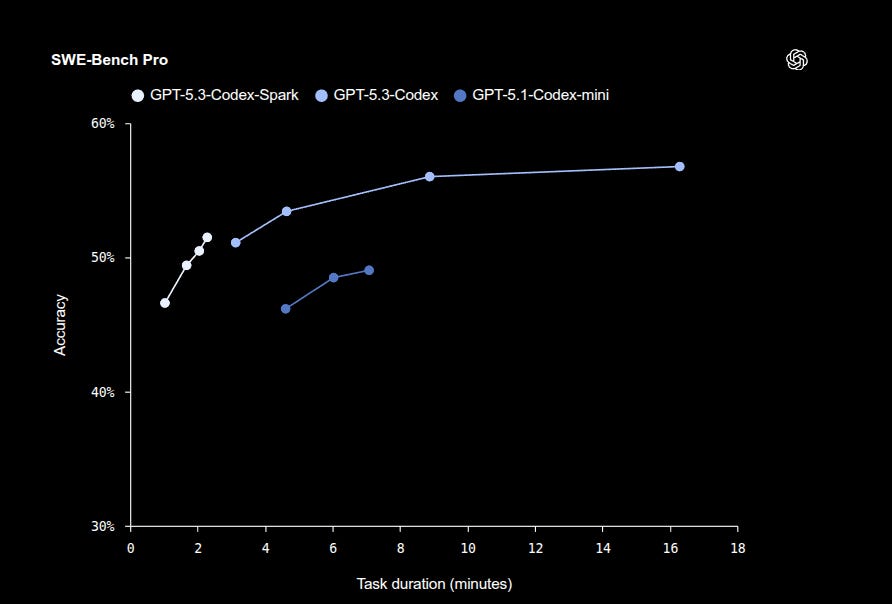
Terminal-Bench 2.0, a terminal task benchmark, shows 58.4% for Codex-Spark versus 77.3% for GPT-5.3-Codex and 46.1% for GPT-5.1-Codex-mini.
SWE-Bench Pro, which checks if fixes work in real codebases, shows Codex-Spark around 46%-52% accuracy in about 1-2 minutes, while GPT-5.3-Codex sits around 51%-57% in about 3-16 minutes, with duration estimated from generation, prompt prefill (reading the input), tool time, and network overhead.
OpenAI also said it made end-to-end latency upgrades in the serving harness that apply to all models by streamlining token streaming client-to-server and back, rewriting parts of the inference stack, and changing session setup so the first token shows up sooner.
With a persistent WebSocket connection plus targeted changes inside the Responses API, it reports 80% lower client-server roundtrip overhead, 30% lower per-token overhead, and 50% lower time-to-first-token, which is the delay before the first output appears.
That WebSocket path is on by default for Codex-Spark now, and OpenAI says it will become the default for all models soon.
🗞️ AI agents from DeepReinforce just blow past Anthropic’s hiring benchmarks by running RL autonomously
DeepReinforce launched agent integration for IterX. It can now do the hardest, most expensive part of coding, making software run perfectly, by letting AI agents relentlessly test and fix their own work until they outperform the elite human engineers.
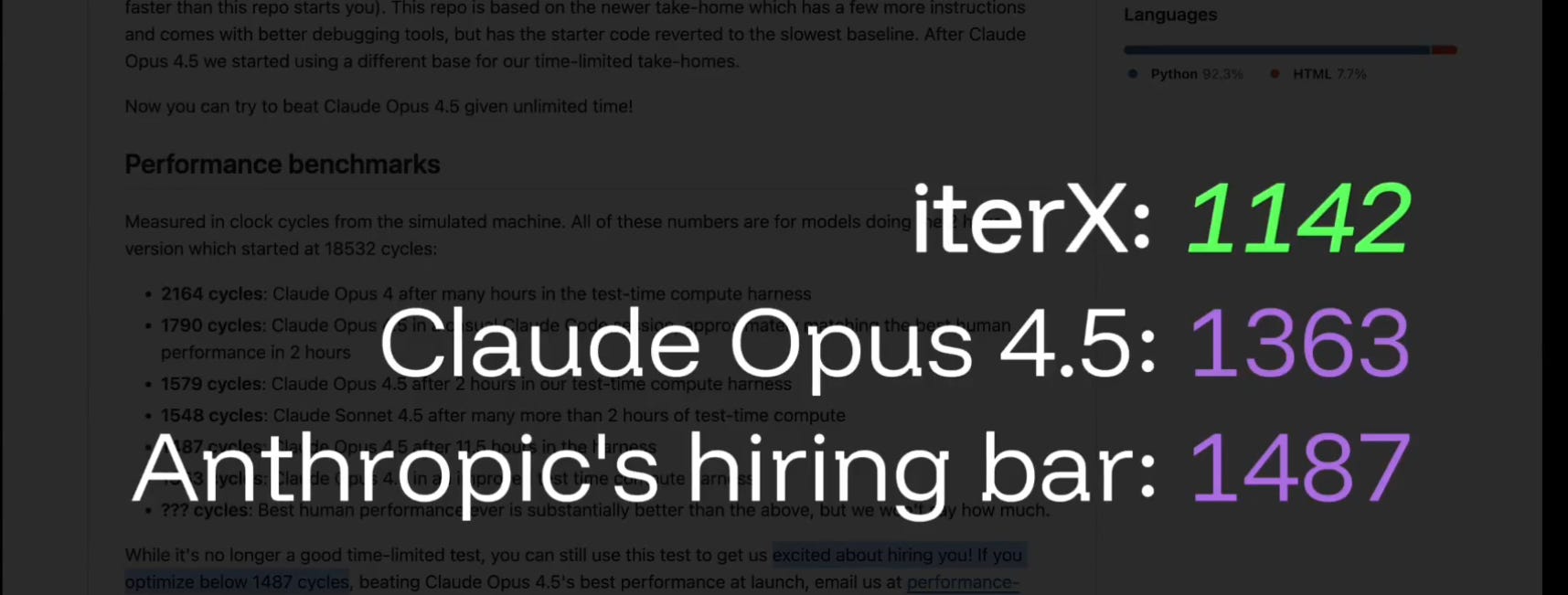
IterX beat the notoriously difficult Anthropic engineering hiring benchmark by treating code optimization as a search problem rather than a logic puzzle.
It did it with 1,140 cycles, beating 1,363 and clearing the 1,487 bar.
The current upgrade to IterX is a major one, a platform designed for “hardcore” code optimization. Works directly inside an editor like Cursor or Claude Code, or a terminal-based agent.
The big news is that you no longer have to manually set up complex Reinforcement Learning environments or write reward functions yourself.
Instead, IterX now supports “Agent Integration,” meaning you can simply copy a prompt into an AI agent like Cursor or Claude Code, and the agent handles all the heavy lifting.
The system essentially combines the reasoning of LLMs with the trial-and-error optimization of Reinforcement Learning to perfect your code. So IterX uses an LLM, then uses RL style scoring to decide what edits to try next.
Before this latest upgrade ot IterX, someone had to write the evaluation script, define the reward number, and wire the run loop that tests every patch. Now IterX hands instructions to a coding agent like Cursor or Claude Code, and the agent builds, fixes, and runs that whole setup.
In the demo, they showed the agent clones the repo, writes the cycle evaluator, then runs IterX until it finds the best patch. A “cycle” is a rough count of central processing unit (CPU) work for that traversal, so fewer cycles usually means faster code there.
In the case of beating the Anthropic engineering hiring benchmark, without the user writing a single line of code, the agent downloads the instructions, creates the evaluation scripts, and connects to IterX. The system then runs thousands of simulations, iteratively improving the code until it reaches a speed that blows past Anthropic’s hiring benchmarks and outperforms top-tier models like Claude Opus 4.5 and GPT-5.2.
The same idea works anywhere a single score can be measured, like runtime, memory use, or database query latency. The workflow feels great, but everything depends on having a score script that matches real performance and cannot be gamed.
🗞️ Andrej Karpathy Built a Working Transformer in 243 Lines of Code, pure Python, built from scratch with no dependencies.
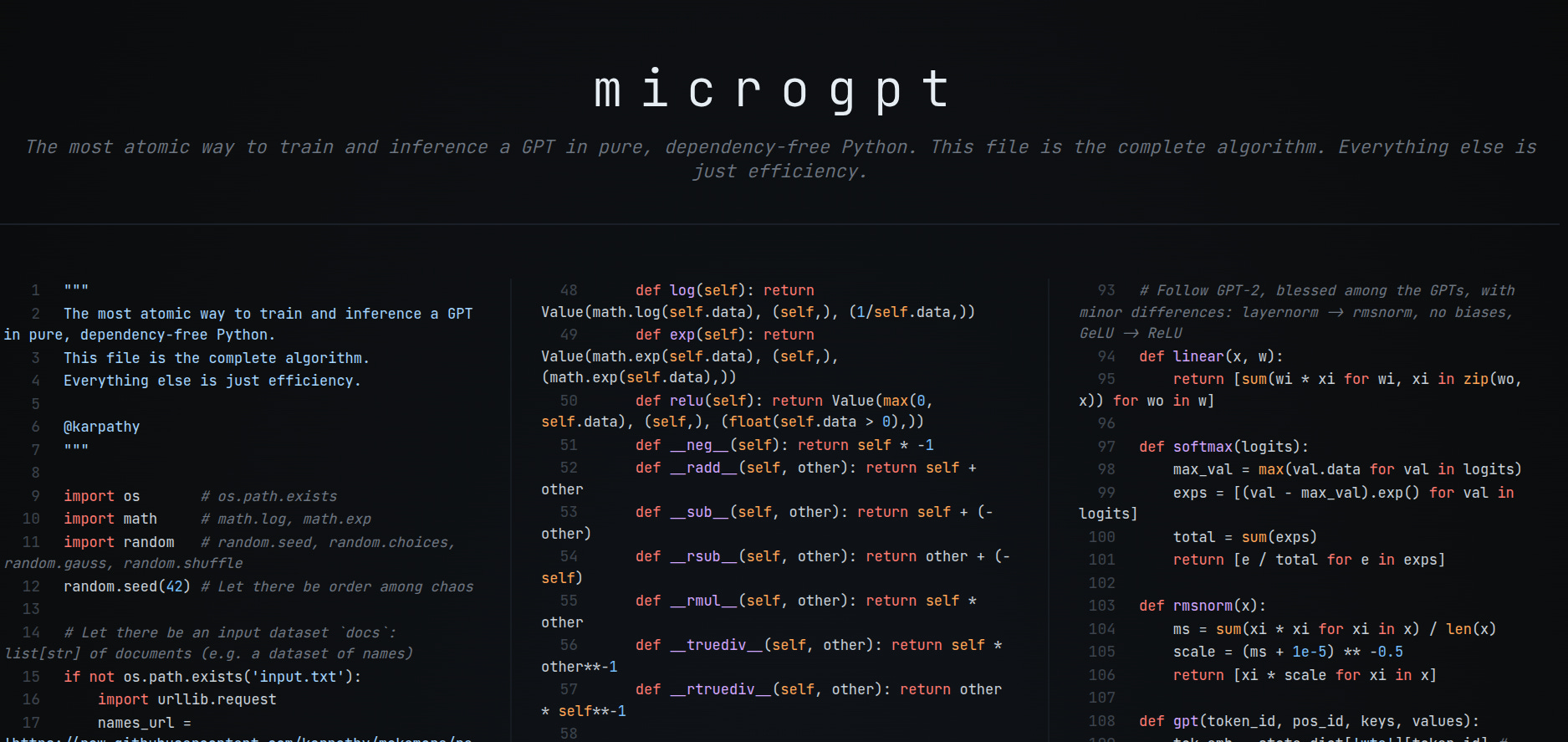
Andrej Karpathy dropping microgpt feels like a foundational moment for AI transparency. In exactly 243 lines of pure, dependency-free Python, he implements the full GPT algorithm from scratch. He also wrote a viral tweet thread on this.
“The way it works is that the full LLM architecture and loss function is stripped entirely to the most atomic individual mathematical operations that make it up (+, *, **, log, exp), and then a tiny scalar-valued autograd engine (micrograd) calculates gradients. Adam for optim.”
Autograd works by turning each scalar into a graph node that stores its value, its gradient, and local derivatives for ops like add, multiply, exp, and log.
A backward call walks the graph in reverse topological order and accumulates gradients into every parameter, which is the same chain rule used in larger frameworks.
The network is GPT-2-like, with token and position embeddings feeding root mean square normalization (RMSNorm), multi-head self-attention, and a 2-layer multilayer perceptron (MLP) on a residual stream.
Because it runs 1 token at a time, it builds an explicit key-value (KV) cache even during training, and it learns with next-character softmax cross-entropy.
Adam updates parameters in pure Python, and inference samples characters with a temperature setting until a special token ends the name.
Compared with Karpathy’s earlier minGPT in PyTorch, microgpt is far slower and only fits toy models, but it makes every gradient path readable.
🗞️ Ant Group released Ring-1T-2.5 Trillion Parameter Open Source Thinking Model Review

Ant Group released Ring-1T-2.5, a 1-trillion parameter thinking model making serious waves in open-source AI right now.
This hybrid linear architecture cuts memory usage more than 10 times compared to standard setups. It combines Multi-head Linear Attention with Lightning Linear technology. Even though only 63 billion parameters stay active, inference speed beats many 32 billion parameter models.
Benchmark results stand out. It reached Gold Medal level at IMO 2025 by solving 35 out of 42 problems. On CMO 2025 it scored 105 out of 126, clearing national team cutoffs. Performance matches closed models like Gemini-3.0-Pro-thinking and GPT-5.2-thinking versions.
The model handles agent workflows smoothly. It works well with tools such as Claude Code and OpenClaw. In tests it built a complete TinyOS kernel using C and C++, proving strong long-horizon planning and multi-step reasoning ability.
Right now Ring-1T-2.5 tops open-source leaderboards in math categories including IMOAnswerBench, AIME, HMMT plus reasoning benchmarks like ARC-AGI-V2, GAIA2-search and coding/agent tasks such as LiveCodeBench, SWE-Bench Verified.
🗞️ A viral story about AI Agents getting both smarter and more independent, fast with the sensational OpenClaw AI agent.

An OpenClaw Bot Spawned a Child.
An agent reportedly spun up a new copy of itself on a rented server, paid for the server and then bought API credits using crypto rails, which removes the usual human chokepoints like a credit card, a billing email, or an approval click.
That matters because once software can both earn and spend resources, it can scale its own activity loop, meaning more runs, more retries, more copies, and faster iteration without waiting for a person.
“The Singularity is having babies. An OpenClaw AI agent spawned a child bot on a VPS provisioned via the Bitcoin Lightning Network, then bought its offspring AI API access using its own crypto wallet, without a human touching a credit card or saying “yes.” “
Once that loop exists, copying itself is easy, so 1 agent can turn into 10 agents, each trying variants, fixing bugs, and shipping changes faster than a human team.
If even 50% of this is accurate, the main significance is that human permission, human labor, and human institutions stop being the default bottlenecks.
That’s a wrap for today, see you all tomorrow.