
🔬 OpenAI used less training compute for GPT-5 than GPT-4.5
OpenAI used less compute for GPT-5, Thinking Machines publishes stable training method, Apple simplifies protein folding, and Google drops its 64-page agent playbook.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (29-Sept-2025):
🔬 OpenAI used less training compute for GPT-5 than GPT-4.5
🧠 Thinking Machines’s next research - introduces manifold Muon, a training method that keeps weight matrices stable by forcing them to live on the Stiefel manifold and by measuring update size with the spectral norm.
🧬 Apple published SimpleFold: Folding Proteins is Simpler than You Think
🛠️ 🧰 Google’s just released its 64-page agent playbook for Startups.
🔬 OpenAI used less training compute for GPT-5 than GPT-4.5 because scaling post-training delivered bigger gains
\" with speculative estimates noted.")
According to new report from EpochAIResearch, OpenAI used less training compute for GPT-5 than GPT-4.5 because scaling post-training delivered bigger gains per dollar than scaling pre-training, so they pushed post-training hard on a smaller base model.
“Training compute” here means the compute for the final training run, not the many experiment runs, and OpenAI’s projected R&D compute rose from $5B in 2024 to $9B in 2025. Historically, LLMs spent ~100x more compute on pre-training than post-training, but new reasoning-focused post-training methods flipped the return curve.
These methods can cut pre-training by about 10x while keeping similar quality when post-training is scaled up, which is why a smaller base could outperform GPT-4.5 after heavy post-training. OpenAI could not safely scale those post-training pipelines all the way to GPT-4.5 scale on the clock, because it needs lots of high quality tasks, reinforcement learning environments, and long experiment cycles. Competitive pressure to ship led them to max out post-training on a smaller model rather than wait for a larger pre-train plus even more post-train.
🧠 Thinking Machines’s next research - introduces manifold Muon, a training method that keeps weight matrices stable by forcing them to live on the Stiefel manifold and by measuring update size with the spectral norm.
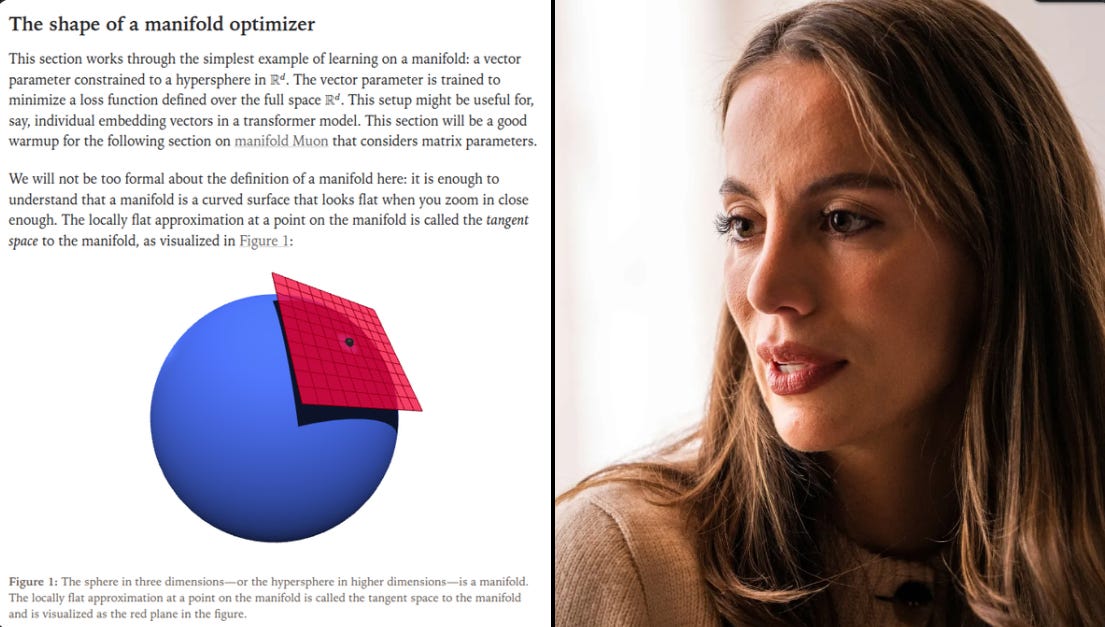
Unstable weights and bad scaling are a common problem in large models, and this method directly fixes that with clear math and practical results. It also proposes modular manifolds, a way to spread the training step size across layers depending on their sensitivity. Note, Thinking Machines has said they are on a mission to make AI models reliable rather than erratic.
🎯 It has one simple but BIG idea: AI outputs can be consistent. While most call models non-deterministic, they claim it’s a solvable flaw. Fixing randomness would make AI safe for high-stakes workflows.
----
So yesterday’s published research pushes in that direction. In a CIFAR-10 test, this manifold Muon method reached higher accuracy than AdamW while keeping the singular values close to 1, though it used more time per step.
Training large networks is hard because weights, activations, or gradients can blow up or vanish. To prevent this, they constrain weights to a manifold, meaning a fixed surface where they must stay.
Updates happen in the tangent space, which is a flat space touching the manifold, and then get pulled back with a retraction map. This ensures the step size in training matches the actual move in parameter space.
The choice of how to measure step length matters, because it changes the update direction. For weight matrices, the best option is to use singular value decomposition, which shows how a matrix stretches inputs.
Good training requires each stretch to be about 1, so no input gets squashed or blown up. This is exactly what the Stiefel manifold enforces, since its matrices have orthonormal columns and unit condition number.
To stop updates from shifting outputs too much, the paper measures their size with the spectral norm, which looks at the largest stretch. Combining these two rules gives the manifold Muon optimizer.
It solves a convex problem using dual ascent and computes safe updates with the matrix sign function. It solves a convex problem using dual ascent and computes safe updates with the matrix sign function.
The process is simple, adjust a dual variable, compute the update, add it to weights, then retract with matrix sign again. The downside is some extra cost per step, but this can be reduced by fewer dual steps or momentum.
🧬 Apple published SimpleFold: Folding Proteins is Simpler than You Think

It reaches about 95% of AlphaFold2 and RoseTTAFold2 while dropping multiple sequence alignment, pair features, and triangle updates. And also while using a simpler, cheaper, and more scalable design.
The big deal is that strong folding no longer needs hand-crafted pair representations, triangle updates, or multiple sequence alignments(MSAs) of AA sequences, a plain transformer with flow matching is enough. The model can generate full ensembles to reflect flexibility, which many deterministic models miss.
It uses flow matching, which learns a direction that moves noisy atoms toward the right shape. A small extra loss on local distances sharpens side chains and nearby geometry.
The network has 3 parts, an atom encoder, a residue trunk, and an atom decoder, all standard transformers with time conditioning. It groups each residue’s atoms into 1 token, adds a protein language model embedding from ESM2-3B, then splits back to atoms.
It skips special geometry layers and instead learns rotation symmetry by training on randomly rotated structures. Because it is generative, it can sample many valid shapes for the same sequence and capture different natural states.
The family scales from 100M to 3B parameters and trains on roughly 2M to 8.6M structures plus the Protein Data Bank, which improves accuracy with scale. It also outputs a per residue confidence score and runs fast on consumer hardware.
The crucial technique they used to get such great result is “flow matching,” which teaches the model how to move a noisy 3D protein toward its true shape using many tiny steps. During training they take a real protein, scramble the atom positions with noise, and ask the transformer to predict the small motion each atom should take at a given time to get closer to the real structure.
Because the model learns these short, local nudges instead of the whole fold at once, learning is stable, sample quality is high, and the same procedure can generate many valid shapes for flexible regions. They also add a simple local distance loss so nearby atoms keep realistic spacing, which sharpens side chains and fixes local geometry.
The network itself stays plain, 1 token per residue with a protein language model embedding and time conditioning, and it learns rotation symmetry by training on randomly rotated structures rather than using special geometry layers. All together, flow matching is the engine, and the simple design lets that engine run fast and scale.

This diagram shows how SimpleFold turns a protein sequence into a 3D shape using plain transformers. It first feeds the amino acid sequence into a frozen protein language model to get features for each residue.
At each time step it also takes a noisy 3D cloud of atoms and encodes them in an Atom Encoder. It groups atoms into 1 token per residue and runs them through a Residue Trunk made of the same simple transformer block.
The block is standard self attention plus feedforward, with tiny scale and shift tweaks driven by the time signal. It then ungroups back to atoms and the Atom Decoder predicts small moves that nudge atoms toward the right structure.
Skip connections carry information across stages to keep details stable. Training uses flow matching, so the model learns how to move from noise to the final fold step by step. The key point is it needs no pair features or triangle updates, just this repeated transformer block with time conditioning.

This figure shows that SimpleFold makes very accurate protein structures while staying fast and scalable. The examples on the left compare predictions to known structures and the matches are near perfect, with TM (Template Modeling score) 0.99 and GDT 0.99 in one case and TM 0.98 and GDT 0.92 in another.
“TM” is a number between 0 and 1 that tells how close a predicted protein structure is to the real, experimentally known structure. A TM score closer to 1 means the prediction is almost identical to the real protein fold.
The overlay in the middle shows an ensemble of shapes for the same protein, which means the model can capture natural flexibility instead of giving only one rigid answer. The bubble chart shows a clear scaling trend, larger models use more compute and reach higher accuracy on the CASP14 benchmark.
The timing plot shows inference grows with sequence length yet still runs in seconds to a few minutes on a MacBook with M2 Max 64GB. The takeaway is simple, the method is accurate, can model multiple states, and is practical to run without special hardware.

🛠️ 🧰 Google’s just released its 64-page agent playbook for Startups.

It lays out 3 paths to adopt agents and the exact plumbing required to make them safe, observable, and scalable. Build with Agent Development Kit (ADK), use Google-managed agents, or bring partner agents, all interoperable via A2A and MCP.
ADK gives multi-agent orchestration, tool use, memory, container serving, and observability so teams automate real workflows, not chats. Core pieces are model choice across Gemini 2.5, explicit tools and APIs, ReAct loops, and a managed runtime like Vertex AI Agent Engine or Cloud Run.
Runtime concerns cover autoscaling, identity, logging, tracing, retries, and cost control, with Terraform and CI/CD provided by the Agent Starter Pack. Data splits into long term knowledge with Vertex AI Search and BigQuery, working memory with Memorystore, and ACID transaction logs in Cloud SQL or Spanner.
Grounding progresses from RAG to GraphRAG to Agentic RAG where the agent plans searches, calls tools, and composes results with citations. Reliability uses 4 evaluation layers covering unit tests, trajectory checks for tool choice and arguments, grounded outcome scoring, and live monitoring.
Security is defense in depth with least privilege IAM, input and output guardrails, durable audit logs in BigQuery, and hardened deployment defaults. This is why slick agent demos stall in production, because real systems need workflows, data contracts, ACID writes, telemetry, and repeatable evaluations.
That’s a wrap for today, see you all tomorrow.