
🌍 OpenAI’s 2025 enterprise AI report
OpenAI drops new LLM usage reports, Devstral 2 targets coding, US clears NVIDIA H200 exports to China, and Google scales TPU production to 5M+ by 2027.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (9-Dec-2025):
🌍 OpenAI’s 2025 enterprise AI report
🏆 Mistral launched coding specialist model Devstral 2
🇺🇸 US TO ALLOW NVIDIA H200 CHIP EXPORTS TO CHINA 🇨🇳
🌍 OpenRouter and a16z published a hugely insightful State of AI report - an empirical report on how LLMs have been used on OpenRouter.
🛠️ Deep Dive: Google’s TPUs are on a serious winning streak and now they plan to produce over 5 million TPUs by 2027 to boost supply
🌍 OpenAI’s 2025 enterprise AI report

ChatGPT Enterprise seats up about 9x in 1 year,
weekly Enterprise message volume up around 8x since November 2024, and
average reasoning token use per customer up roughly 320x in 12 months, while nearly 200 organizations have already processed more than 1 trillion tokens.
AI is increasingly wired into systems, since around 20% of all Enterprise messages now go through Custom GPTs or Projects, some firms like BBVA run over 4,000 internal GPTs. Frontier workers send about 6x more messages than median workers, frontier firms send about 2x more messages per seat.
Coding messages alone about 17x higher for frontier users and similar 8 to 11x gaps for writing, analysis, and information gathering. On the impact side, about 75% of roughly 9,000 surveyed workers say AI improves the speed or quality of their work, typical ChatGPT Enterprise users report saving roughly 40 to 60 minutes per active day, and about 75% say they can now do tasks they previously could not like coding or spreadsheet automation. A 2025 BCG study reports AI leaders at roughly 1.7x revenue growth, 3.6x shareholder return, and 1.6x EBIT margin, real bottleneck now is disciplined engineering of connectors, reusable GPT workflows, evaluation, and change management that spread advanced tools from frontier users to everyone else in the firm.

Productivity gains from AI are not linear, they accelerate with depth of use.
Workers who use advanced ChatGPT capabilities like GPT-5 Thinking, Deep Research, and Image Generation, across multiple models and tools, report much bigger time savings.
OpenAI’s latest study shows that the group saving more than 10 hours per week is also using about 8x more AI credits than workers who report 0 hours saved.
So the story is not “give everyone a chatbot and you get a small uniform boost.” The story is: the more intensely people integrate powerful AI features into their workflow, the more their time savings compound, and heavy users turn AI into a core work assistant rather than a casual helper.
🏆 Mistral launched coding specialist model Devstral 2

Devstral 2 matches DeepSeek V3.2 on SWE Bench and human evals, yet uses 5x fewer parameters, needs significantly smaller GPUs, and delivers significantly lower per task cost.
Devstral Small 2 is just 24B and scores about 68% on SWE Bench Verified, and you can run it on a Laptop.
SWE Bench Verified uses real GitHub issues plus tests to check if model patches fully fix the bug.
On this benchmark Devstral 2 scores 72.2% and Devstral Small 2 scores 68.0%, putting them near the top of open and many closed models.
Devstral 2 is tuned as an agent that reads many files, tracks project structure, calls tools, and retries after failures for long refactors.
Human evaluations with the Cline framework prefer Devstral 2 over DeepSeek V3.2 but still favor Claude Sonnet 4.5, while Devstral can be about 7x cheaper per solved task.
Devstral Small 2 keeps the 256K context, adds image input, and runs on a single consumer GPU or CPU for private multimodal coding agents.
They also released the Mistral Vibe CLI - gives a repo aware terminal chat that scans projects, understands Git status, edits multiple files, runs commands, and prepares pull requests from natural language.
Mistral AI is leaning heavily on context awareness as its edge, especially for business tools. Like its AI assistant Le Chat, which remembers past chats and uses them to give smarter replies, Vibe CLI keeps a running history and even reads file setups and Git states to shape its responses.
The push toward real-world production workflows is also why Devstral 2 is quite heavy-duty—it needs at least 4 H100 GPUs or similar to run and packs 123 billion parameters. For lighter setups, there’s Devstral Small, which has 24 billion parameters and can even run locally on regular consumer machines.
Licensing differs too: Devstral 2 follows a modified MIT license, while Devstral Small uses Apache 2.0.
The below chart plots SWE Bench Verified accuracy against model size, so top left means strong performance with fewer parameters.
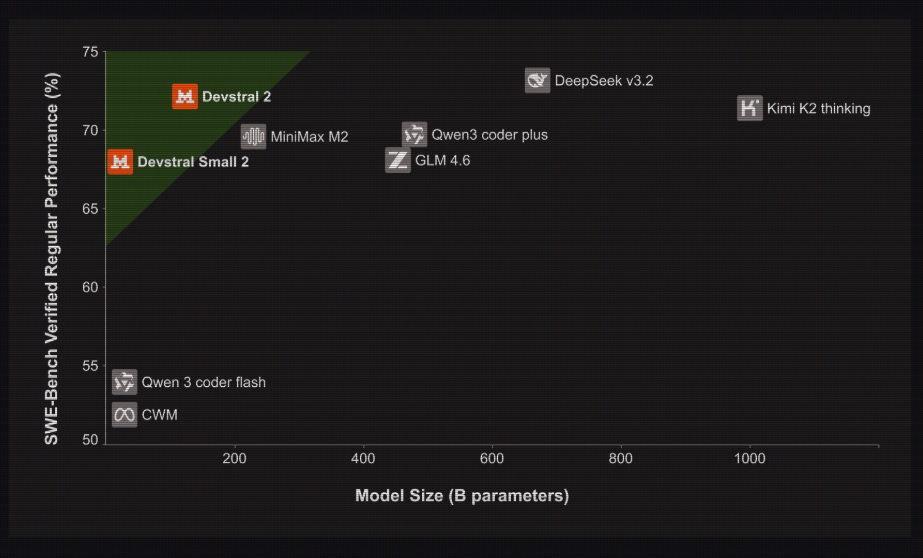
Devstral 2 and Devstral Small 2 sit in that top left green zone, close to or above much larger models like DeepSeek V3.2 and Kimi K2 thinking on accuracy while being many times smaller.
The significance is that Mistral is basically sitting on the efficiency frontier here, getting ~70%+ SWE Bench scores with models that are far cheaper to host, fine tune, and ship on normal hardware.
🇺🇸 US TO ALLOW NVIDIA H200 CHIP EXPORTS TO CHINA 🇨🇳

This is a compromise that allows high-end GPUs roughly 18 months behind the most frontier while keeping tighter parts off the table. The goal is to reopen a blocked market after China told buyers to avoid the weaker H20, which left US vendors sidelined and created space for Huawei’s homegrown accelerators.
The H200 carries larger HBM3e and higher memory bandwidth than H100, so Chinese labs can train and serve bigger models with fewer nodes, simpler parallelism, and faster checkpointing. Licenses will likely define volumes, buyers, and telemetry, so Washington keeps leverage while US products set de facto software and networking standards.
Supporters of strict controls point to compute scarcity, arguing that denying top chips slowed China and helped the US assemble the first mega-clusters. Skeptics say blanket bans pushed China to accelerate domestic silicon and that controlled access with clear guardrails can shape the market without ceding standards.
If shipments proceed, expect premium pricing that bakes in compliance costs and quota risk, plus priority allocations to hyperscalers and state-linked clouds. US supply remains tight because HBM stacks and advanced packaging are bottlenecks, so any licenses will still feel scarce on the ground.
Technical details on how H200 is ~18months behind the most frontier GPUs from Nvidia.

H200 is Hopper-generation where as Blackwell B200/GB200 are a full new generation, so H200 trails on compute formats, memory bandwidth, and interconnect scale.
H200 provides 141GB HBM3e, 4.8TB/s memory bandwidth, and 4 PFLOPS FP8 per GPU. B200 lifts a single GPU to 180GB HBM3e with 8TB/s memory bandwidth and roughly 4.5 PFLOPS FP8 or 9 PFLOPS with sparsity, so per-GPU memory and feed rate are both higher than H200.
Interconnect is a bigger gap, Hopper/H200 uses NVLink Gen4 900GB/s per GPU, while Blackwell uses NVLink Gen5 1.8TB/s, which doubles GPU-to-GPU bandwidth and reduces parallel efficiency loss on big models. Blackwell adds a second-generation Transformer Engine with FP4/FP6 support and micro-tensor scaling, so it pushes more tokens at lower precision without giving up accuracy, H200 only has first-gen FP8.
Blackwell also uses 2 reticle-limited dies fused by a 10TB/s on-package link, giving much higher on-chip bandwidth than Hopper’s monolithic H200. At the box level, DGX B200 with 8 B200s exposes 1.4TB GPU memory, 64TB/s HBM3e bandwidth, and 14.4TB/s NVLink via 2 NVSwitch ASICs, which is a step above Hopper-class nodes.
At rack scale, GB200 NVL72 bonds 72 Blackwell GPUs into one NVLink domain with ~130TB/s of low-latency GPU fabric, something H200 systems cannot match. Net, H200 sits roughly 1 generation back, with smaller per-GPU memory, ~2x lower NVLink bandwidth, and older tensor math, so it trains and serves large models less efficiently than B200/GB200 at the same cluster size.

🌍 OpenRouter and a16z published a hugely insightful State of AI report - an empirical report on how LLMs have been used on OpenRouter.

The dataset aggregates billions of anonymized generations across hundreds of models and regions without reading user text, so it tracks real behavior rather than benchmarks. Open source share climbed through 2025 with Chinese OSS averaging ~13.0% weekly usage and peaking near ~30%, led by DeepSeek, Qwen, and Kimi.
Reasoning oriented models now process >50% of tokens as tool calling rises, average prompts grew ~4x to >6,000 tokens, and mean sequence length passed ~5,400 tokens. Model size dynamics favor mediums, where 15B–70B models found strong fit, small models lost share, and large models diversified instead of converging on one winner.
Geography shifted too, with Asia’s spend share rising from ~13% to ~31%, and language mix staying English 82.87% with Simplified Chinese 4.95%. Retention surfaces a “Glass Slipper” effect, where early Claude 4 Sonnet and Gemini 2.5 Pro cohorts kept ~40% at month 5, while DeepSeek shows a boomerang return pattern. Cost vs usage is price inelastic, closed models cluster at high cost and high usage, open models drive low cost and high volume, and prices range from $0.147 per 1M tokens for Gemini 2.0 Flash to ~$34.965 for GPT-5 Pro.
Open vs. Closed Source Models

🛠️ Deep Dive: Google’s TPUs are on a serious winning streak and now they plan to produce over 5 million TPUs by 2027 to boost supply
")
A few days back SemiAnalysis reported that, for large buyers Google TPU can deliver roughly 20%–50% lower total cost per useful FLOP compared to Nvidia’s top GB200 or GB300 while staying very close on raw performance.
Which is why Anthropic signed up for access to about 1M TPUs and more than 1GW of capacity with Google by 2026.
The basic cost story starts with margins, since Nvidia sells full GPU servers with high gross margins on the chips and the networking whereas Google buys TPU dies from Broadcom at a lower margin and then integrates its own boards, racks and optical fabric, so the internal cost to Google for a full Ironwood pod is significantly lower than a comparable GB300 class pod even when the peak FLOPs numbers are similar.
On the cloud side, public list pricing already hints at the gap because on demand TPU v6e is posted around 2.7 dollars per chip hour while independent trackers place Nvidia B200 around 5.5 dollars per GPU hour, and multiple analyses find up to 4x better performance per dollar for some workloads once you measure tokens per second rather than just theoretical FLOPs.
A big part of this advantage comes from effective FLOPs instead of headline FLOPs because GPU vendors often quote peak numbers that assume very high clocks and ideal matrix shapes, while real training jobs tend to land closer to 30% utilization, but TPUs advertise more realistic peaks and Google plus customers like Anthropic invest in compilers and custom kernels to push model FLOP utilization toward 40% on their own stack.
Ironwood’s system design also cuts cost because a single TPU pod can connect up to 9,216 chips on one fabric, which is far larger than typical Nvidia Blackwell deployments that top out at about 72 GPUs per NVL72 style system, so more traffic stays on the fast ICI fabric and less spills to expensive Ethernet or InfiniBand tiers.
Google pairs that fabric with dense HBM3E on each TPU and a specialized SparseCore for embeddings, which improves dollars per unit of bandwidth on decode heavy inference and lets them run big mixture of experts and retrieval heavy models at a lower cost per served token than a similar Nvidia stack.
These economics do not show up for every user because TPUs still demand more engineering effort in compiler tuning, kernel work and tooling compared to Nvidia’s mature CUDA ecosystem, but for frontier labs with in house systems teams the extra work is small compared to the savings at gigawatt scale.
Even when a lab keeps most training on GPUs, simply having a credible TPU path lets it negotiate down Nvidia pricing, and that is already visible in the way large customers quietly hedge with Google and other custom silicon and talk publicly about escaping what many call the Nvidia tax.
That’s a wrap for today, see you all tomorrow.