
💻 OpenAI's GPT-5.2-Codex is now live, raising the bar for pro-level software engineering by AI
GPT-5.2 Codex drops, Stanford pushes AGI coordination thesis, Mistral ships OCR 3, OpenAI eyes $840B, DeepMind teams with OpenAI, plus new taxonomy on LLM harms.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (19-Dec-2025):
💻 GPT-5.2-Codex is now live, raising the bar for pro-level software engineering and long, agent-style coding tasks.
🏆 New Stanford paper argues that LLMs already provide the raw skills for AGI, but they still need a coordination layer on top.
📡Mistral AI just released Mistral OCR 3, a model meant to turn PDFs and scans into text, embedded images, and structure.
🛠️OpenAI is talking to private investors about a new fundraise (from $10B to $100B) at a valuation of $750B to $840B, which would be one of the biggest private valuations ever.
👨🔧 LLM Harms: A Taxonomy and Discussion
🧠 In a move no one saw coming, the two biggest AI rival, Google DeepMind and OpenAI, are now on the same side.
💻 GPT-5.2-Codex is now live, raising the bar for pro-level software engineering and long, agent-style coding tasks.
An “agentic” coding model does more than write snippets, it can plan steps, run terminal commands, edit files, and keep iterating until builds and tests pass. Codex can take design mocks and quickly translate them to functional prototypes, and you can pair with Codex to take these prototypes to production.
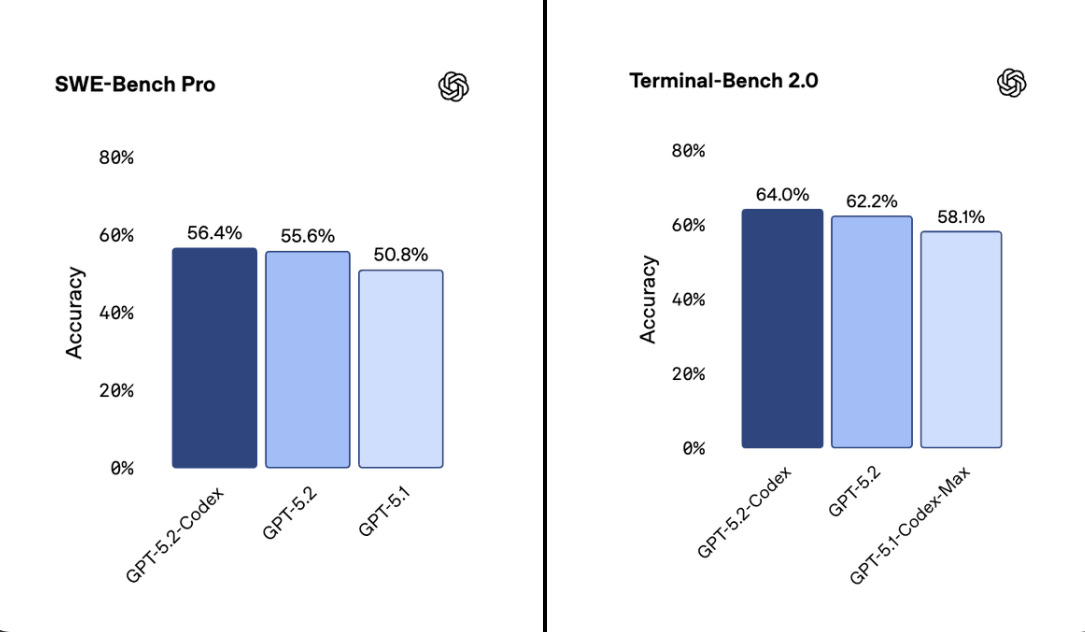
Context compaction shrinks a long session into a tighter summary so the model remembers key decisions with fewer tokens. A solid 56.4% on SWE-Bench Pro and 64.0% on Terminal-Bench 2.0.
SWE-Bench Pro checks whether the model can produce a correct patch in a real repository, and Terminal-Bench 2.0 checks whether an agent can reliably do terminal work like compiling and server setup. GPT-5.2-Codex is better at reading screenshots and technical diagrams, which helps when the only clue is a UI or a pasted error screen.
On cybersecurity, capability jumped again, but it is still below the High threshold in its Preparedness Framework, using a professional capture-the-flag style evaluation. Currently invite-only trusted access for vetted security professionals doing authorized defensive work, since these skills are dual-use.
🏆 New Stanford paper argues that LLMs already provide the raw skills for AGI, but they still need a coordination layer on top.

A Stanford University paper on the missing AGI layer just turned the whole “LLMs are only pattern matchers” idea upside down. This is not about scaling tricks or some new architecture. It is about a coordination layer that actually lets models think.
They show hallucination versus reasoning is not random at all. It behaves like a phase transition you can predict using a physics-style anchoring score.
Adding a small amount of structure, like examples, retrieval, or constraints, can push a model from drifting on priors into fully goal-driven behavior.
This switch is formalized with UCCT, using effective support, mismatch penalty, and an anchoring budget that decides when reasoning actually turns on.
They then introduce MACI, a multi-agent coordination stack with debate, Socratic judging, and transactional memory to keep long-horizon reasoning stable.
CRIT, their judge system, removes ill-posed arguments before they can corrupt the reasoning loop.
Here the LLM is a fast pattern store, while a slower controller should choose which patterns to use, enforce constraints, and keep track of state. To describe this, the author defines an anchoring strength score that grows when evidence clearly supports an answer, stays stable under small prompt changes, and avoids bloated, noisy context.
When anchoring is weak the model mostly parrots generic patterns and hallucinates, but past a threshold it switches into more reliable, goal directed reasoning, as small arithmetic and concept learning tests show. MACI then runs several LLM agents in debate, tunes how stubborn they are from anchoring feedback, inserts a judge to block weak arguments, and uses memory to track and revise decisions on longer tasks. The main claim is that most LLM failures come from missing anchoring, oversight, and memory instead of a bad pattern substrate, so progress should focus on building this coordination layer rather than discarding LLMs.
📡Mistral AI just released Mistral OCR 3, a model meant to turn PDFs and scans into text, embedded images, and structure.

$2 per 1,000 pages, or $1 per 1,000 pages via batch.
meant to handle harder inputs. Targets forms, cursive notes, low quality scans, and complex tables, so invoices and compliance forms keep their fields.
Output can be Markdown with HTML table reconstruction, including colspan and rowspan signals for merged cells.
The model name for the API is mistral-ocr-2512. Mistral says it built tougher internal tests from customer like documents and scored accuracy with fuzzy matching that treats small text differences as close, not fully wrong.
Backward compatibility with OCR 2. Cheaper structured table output is the main practical upgrade, since downstream automation often fails first when a column shifts.
🛠️OpenAI is talking to private investors about a new fundraise (from $10B to $100B) at a valuation of $750B to $840B, which would be one of the biggest private valuations ever.

The Information reported this story first.
This is a massive 50% jump in valuation from Oct--25, when OpenAI let current and former employees sell $6.6B of shares at a $500B valuation. OpenAI was also preparing for a possible IPO, with a filing window talked about as roughly Jul-26 to Dec-26, and a valuation that could reach $1T.
Separately, just yesterday, Bloomberg reported Amazon is in initial talks to invest at least $10 billion in OpenAI and sell the company its chips. So the valuations surge across the AI sector continues.
Anthropic’s valuation has jumped to roughly $350B after investments from Microsoft and Nvidia, up sharply from about $183B back in September. Elsewhere, Perplexity hit around $20B after a funding round in September 2025, while Elon Musk’s xAI has reportedly been in talks to raise $15B at a $230B valuation.
CB Insights says more than 1,300 AI startups are now valued above $100M, including 498 unicorns worth $1B+. UBS estimates global AI spending will reach $375B this year and climb to $500B in 2026, explaining why investors keep piling in despite rising doubts about long-term returns.
👨🔧 LLM Harms: A Taxonomy and Discussion

This new study builds a simple map of all the main ways large language models can cause harm.
Using about 200 research papers and incident reports, it groups harms into 5 stages of a model’s life. Before the model is released, it highlights issues like scraped personal data, training on text without people’s consent, heavy energy use, and low paid annotation work.
In what the model writes out, it focuses on biased or stereotyped language, toxic or false content, and hallucinations that look trustworthy. For intentional misuse, it shows how people can generate scams, targeted abuse, propaganda, and even prompt based attacks on connected systems.
At the broader social level, it describes job disruption, political manipulation, concentration of computing power, and unequal access to advanced models across regions and languages. When models are built into tools for healthcare, finance, education, or creative work, it explains how errors and bias can quietly shape real decisions. Across all stages, the authors line up existing technical and policy defenses and argue that only many layered safeguards together can keep risks manageable.
🧠 In a move no one saw coming, the two biggest AI rival, Google DeepMind and OpenAI, are now on the same side.

Instead of competing over chatbots, these top labs are teaming up with the government’s 17 national laboratories and supercomputers to double America’s scientific output by 2030. DeepMind will use Gemini 3’s reasoning power for fusion plasma simulations, climate models, and new material discovery, while OpenAI is merging its models with massive federal datasets to automate complex research and test scientific ideas faster.
The shared goal: major leaps in sustainable fusion power, quantum computing, and national security through one unified AI platform. Google DeepMind says it has already suggested drug repurposing ideas for liver scarring that got checked in lab work, and it predicted antibiotic resistance mechanisms that later matched experiments.
In early 2026, the program is expected to add AlphaEvolve for better algorithms, AlphaGenome for understanding non-coding DNA, and WeatherNext for weather forecasting, plus Gemini for Government. Genesis Mission is DOE’s plan to pair frontier AI with national-lab supercomputers, simulations, and datasets so researchers can iterate faster on hard science problems. OpenAI says it has already run a 1,000-scientist “AI Jam” across 9 labs and deployed reasoning models on Los Alamos’s Venado supercomputer as a shared resource across National Nuclear Security Administration labs.
That’s a wrap for today, see you all tomorrow.