
🧠 OpenAI’s new LLM exposes the secrets of how AI really works.
From OpenAI’s LLM transparency to DeepMind’s SIMA 2, live RAG-trading, Nvidia’s MoE boost, Mira’s $50B AI play, and a tight new RAG framework.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (14-Nov-2025):
🧠 OpenAI’s new LLM exposes the secrets of how AI really works.
🌐 Google DeepMind introduces SIMA 2, a Gemini-powered agent that moves from command following to goal-directed reasoning, conversation, and action in 3D worlds.
📈 A great opensource platform showing a solid usecase of how LLMs, RAG+memory can be leveraged for live financial trading.
🔌 NVIDIA says Blackwell GB200 NVL72 gives10x better efficiency and revenue from Mixture-of-Experts models.
💰: Thinking Machines Lab, Mira Murati’s AI startup, is in talks to raise money at about $50B valuation, which would more than 4x its $12B price tag from July-25.
👨🔧 Github: RAG-Anything: All-in-One RAG Framework
🧮 Weibo’s new open source AI model VibeThinker-1.5B outperforms DeepSeek-R1 on $7,800 post-training budget.
OpenAI’s new LLM exposes the secrets of how AI really works.

They built an experimental large language model that’s much easier to interpret than typical ones.
Thats such a big deal because most LLMs operate like black boxes, with even experts unsure exactly how they make their decisions. A more transparent model helps reveal why LLMs hallucinate, behave unpredictably, or make unreliable judgments in critical situations.
The new model, a weight-sparse transformer, is much smaller and less advanced than major models like GPT-5, Claude, or Gemini. Gao said it performs roughly at the level of GPT-1 from 2018, though no direct comparison has been made.
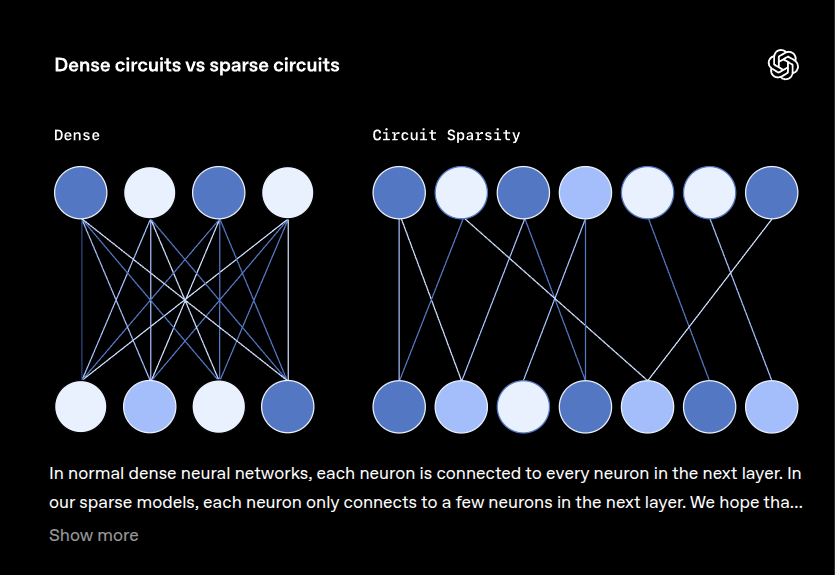
They train language models so their internals form sparse circuits, making the steps the model uses simple to read and test while still solving real tasks on code. Dense models wire each neuron to 1000s of others so features overlap and explanations tangle, which makes reverse engineering hard compared with reading a reasoning trace.
This work keeps the usual transformer shape but forces most weights to 0, so each neuron keeps only 10s of connections and different skills separate into cleaner paths. For each behavior, the team isolates a tiny circuit that is sufficient because it performs the behavior alone and necessary because deleting those edges breaks it.
The goal isn’t to rival those flagship systems but to study this simpler model’s workings to uncover what drives more complex ones. Interpretability is measured by how small the pruned circuit is, capability is measured by pretraining loss, and with higher sparsity capability dips a bit while circuit size shrinks a lot.
Training bigger but sparser models improves both axes at once in this setup, giving stronger models whose mechanisms are still simple to map. For harder skills like variable binding in code, full stories are not finished yet, but partial circuits still predict when the model reads or writes the right type.
The main contribution is a training recipe that yields mechanisms analysts can name, draw, and falsify with ablations, rather than trying to untangle mixed features after the fact. Scope is narrow because these are small models and simple behaviors, and a lot of computation remains outside the mapped circuits.
🌐 Google DeepMind introduces SIMA 2, a Gemini-powered agent that moves from command following to goal-directed reasoning, conversation, and action in 3D worlds.

SIMA 2 is its most capable AI agent for virtual 3D worlds.
It handles unseen games, understands text, voice, images, and even emojis, transfers ideas like “mining” to “harvesting,” and improves through trial-and-error with Gemini feedback. SIMA 2 is trained on human demonstration videos paired with language plus Gemini-generated labels, so it can explain its plan and the steps it will take to reach a goal.
Performance is closer to human play across many tasks, with higher success on long and detailed instructions and better reliability in new titles such as ASKA and MineDojo. The agent accepts multimodal prompts, including rough sketches on the screen, and turns them into multi-step actions that respect the game’s context.
It also operates inside synthetic worlds produced by Genie 3, orienting itself and executing goals despite never seeing those environments before. A self-improvement loop lets it switch from learning by watching to learning by playing, then use its own experience to train the next version without new human data.
Current limits include very long-horizon tasks, short interaction memory, precise low-level mouse-keyboard control, and robust visual understanding in complex scenes. SIMA 2 is a research preview with early access for a small group of academics and developers.
📈 A great opensource platform showing a solid usecase of how LLMs, RAG+memory can be leveraged for live financial trading.

Their open source repo has 5.8K Github stars ⭐️
ValueCell is an open source multi agent platform for financial applications where a group of specialized AI agents can research markets, monitor portfolios, and execute trades inside 1 unified system that users run on their own machines.
⚙️ The Core Concepts are that ValueCell separates a user facing orchestrator from the individual agents, so planning, memory, storage, and routing live in a central controller while each agent process focuses only on its own financial job.
The orchestrator receives the query from the user, streams partial responses back to the browser, supports human in the loop corrections, and can push notifications later when an agent finishes a long running task.
Under that controller, an Agent Clients layer speaks a common A2A protocol to external agent frameworks such as LangChain and Agno.
Means the same ValueCell core can host agents written with different toolkits without adding new plumbing every time. Out of the box the platform ships with 3 main agents, a DeepResearch Agent for fundamental and document analysis, a Strategy Agent for multi asset trading strategies, and a News Retrieval Agent that can track topics and send scheduled news updates.
The DeepResearch Agent automatically retrieves filings and other fundamental documents, analyzes them into structured insights, and then uses large language models to produce interpretable summaries instead of raw dumps of text, which is where the project leans on retrieval augmented generation ideas backed by an embedding powered memory store.
The Strategy Agent is wired for multiple crypto assets and multiple strategies at once, so it can translate natural language trading logic into executable orders and run them continuously while logging every decision and trade.
The News Retrieval Agent behaves like a lightweight scheduler, for example a user can say they want Tesla news every 5 minutes, confirm the schedule, and then see a stream of timestamped headlines and summaries arrive in the chat panel with the option to cancel the job later.
Underneath these agents, ValueCell normalizes access to several LLM providers, right now OpenRouter, SiliconFlow, Google, and OpenAI, so the same agent code can run against different model backends simply by changing environment variables in the `.env` configuration.
You can configure OpenRouter together with any provider that exposes embedding models, because that combination gives fast model switching plus RAG+Memory features for storing vector representations of documents and conversations that agents can recall later. Official Site and Github.
🔌 NVIDIA just published that Blackwell GB200 NVL72 plus its Dynamo software as a way to get about 10x better efficiency and revenue from Mixture-of-Experts models like DeepSeek-R1.

MoE models are costly because several experts can fire per token so NVIDIA promotes disaggregated serving where prefill runs on one pool and decode on another. i.e. input processing runs on one set of GPUs and output generation runs on another set to use hardware more efficiently.
That split lets each pool be sized and tuned for its own pattern, raising overall throughput without adding more racks. Dynamo coordinates these phases across nodes and, together with Kubernetes and Grove, lets cloud providers expose the rack as one multi-node inference service.
💰: Thinking Machines Lab, Mira Murati’s AI startup, is in talks to raise money at about $50B valuation, which would more than 4x its $12B price tag from July-25
The team is stacked with ex OpenAI leadership, including Mira Murati as founder, John Schulman as cofounder, and Barret Zoph leading research, so investors are effectively paying for the concentration of frontier-talent plus a fresh cap table. Tinker is an API and workflow layer that lets teams fine tune frontier and strong open models with much less infra work, so instead of training a giant model from scratch, users push their own data and get a specialized version back.
Universities like Princeton and Stanford and several research groups use Tinker for theorem proving, chemistry, and control experiments, which signals that the stack is already good enough for real research workloads, not just toy demos. There are already paying enterprise customers on Tinker, so revenue exists, but the current valuation is clearly driven far more by expectations around being the “go to” customization layer rather than current cash flow. At the same time, Thinking Machines is in the same alumni wave as Ilya Sutskever’s Safe Superintelligence at $32B and Liam Fedus’s Periodic Labs at $1.3B, showing how aggressively capital is chasing ex OpenAI founders.
👨🔧 Github: RAG-Anything: All-in-One RAG Framework

RAG-Anything eliminates the need for multiple specialized tools. 7.6k Stars ⭐️
All-in-One Multimodal Document Processing RAG system built on LightRAG. You can query documents containing interleaved text, visual diagrams, structured tables, and mathematical formulations through one interface.
Document Parsing
Content Analysis
Knowledge Graph
Intelligent Retrieval
🧮 Weibo’s new open source AI model VibeThinker-1.5B outperforms DeepSeek-R1 on $7,800 post-training budget.

Training follows the Spectrum-to-Signal Principle, where SFT first maximizes solution diversity to boost Pass@K, then RL with MaxEnt-Guided Policy Optimization amplifies the most reliable paths by weighting high-uncertainty samples. This diversity-first pipeline lets a small dense model explore many candidate traces, then focus updates where entropy is highest, which is how it closes the gap with giant models on structured reasoning.
On public benchmarks the model reports AIME25 74.4, LiveCodeBench v6 51.1, and GPQA-Diamond 46.7, which lands near or above much larger open and closed baselines in math and coding, while trailing on broad general knowledge. The compute note lists about 3,900 GPU hours on Nvidia H800, and recommended inference settings temperature 0.6, top_p 0.95, max tokens 40960, which makes local and edge deployment practical and cheap.
That’s a wrap for today, see you all tomorrow.