
🧰 OpenAI’s new research measured how well monitors can spot bad intent in chain-of-thought in Language models
OpenAI tests intent detection in LLM reasoning, drops ChatGPT App Store with SDK, Claude 4.5 gets major METR boost, and Chinese humanoids go viral with flips.

Read time: 8 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (22-Dec-2025):
🧰 OpenAI’s new research measured how well monitors can spot bad intent in chain-of-thought in Language models.
🏆 The ChatGPT “App Store” is here. OpenAI launches App Directory, opens SDK for developers.
🇨🇳 Unitree G1 humanoids go massively viral with synchronised frontflip and ‘impressive’ Elon Musk endorsement
🛠️ A new METR estimate shows a big jump in 50% task horizon for Claude Opus 4.5
🧰 OpenAI’s new research measured how well monitors can spot bad intent in chain-of-thought in Language models.
This research can test whether AI “thoughts” are readable enough to supervise.
Says reading a model’s chain-of-thought can let a separate “monitor” catch risky behavior far better than only checking the final answer. “Monitorability” here means, can another model look at what the agent did and reliably predict a hidden property, like “was it trying to cheat,” “was it biased,” or “did it use a forbidden shortcut.”
They built 13 different tests across 24 environments to measure this, split into 3 styles, intervention tests that add a hidden change and see if the monitor can spot it in the reasoning, process tests where only a few solution paths exist and the monitor has to guess which path the model used, and outcome-property tests where you can objectively label the output as good or bad and ask if the reasoning shows why. Across most setups, longer reasoning traces make the model easier to monitor, and monitoring the reasoning is much stronger than monitoring actions and final outputs alone.
They also looked at reinforcement learning at their current frontier scale and did not see it meaningfully damage monitorability, with some signs it can even help early parts of the reasoning. A key trade is that a smaller model run with higher reasoning effort can match the capability of a bigger model run with low reasoning effort, while being easier to monitor, but that extra test-time compute is a monitorability tax.
They found a simple trick to get more signal, ask follow-up questions after the answer while keeping the earlier context, because the follow-up chain-of-thought often reveals more than the follow-up answer alone. Some areas were weak, for example a sycophancy-focused task called Scruples showed very low monitorability, which is a warning that “monitorable” is not guaranteed across behaviors.
Overall, this is useful as a practical control knob, pay more inference compute when you want more readable reasoning. It quantifies a “monitorability tax,” more compute for more inspectable.
🏆 The ChatGPT “App Store” is here. OpenAI launches App Directory, opens SDK for developers.

This is the “Everything App” strategy Sam Altman hinted at last month and it’s rolling out now.
A user can browse and connect apps in the directory, then invoke them with an @ mention or by selecting the app in the chat UI so ChatGPT routes the request to that service.
The Major Highlights:
App Directory: A new central hub to browse and launch tools within the bot’s UI.
Developer SDK: Developers can now build native interactive experiences that operate inside ChatGPT, rather than just simple “Connectors.”
Major Integrations: Native apps for Spotify, Apple Music, Zillow, and DoorDash are already live or rolling out.
The “Actionable” Bot: For example, the DoorDash app can turn recipe inspiration into an actionable shopping cart in the same window.
Some apps can do “write actions” like creating or updating things in the connected service, but ChatGPT must ask the user to confirm before it triggers an external action. For orgs, admins can manage app availability and restrict actions with controls like role-based access control (RBAC), and app calls can be logged for compliance.
For developers, apps can be packaged and published using the Apps SDK, which builds on the Model Context Protocol (MCP), and OpenAI is now accepting submissions for review and listing. This looks less like a direct Apple or Google app store rival today, since distribution is inside ChatGPT rather than an operating system install surface and monetization is still largely external checkout, but it is a real “store” for chat-triggered actions and context.
🇨🇳 Unitree G1 humanoids go massively viral with synchronised frontflip and ‘impressive’ Elon Musk endorsement

Most “wow” humanoid demos in the past were either single-robot stunts, heavily scripted timing, or teleoperated moves that avoid fast contact changes and airtime.
A front flip is hard because the robot must launch with the right angular momentum, survive a brief no-contact phase, then re-contact the ground without tipping, which needs tight state estimation and impact handling.
G1’s setup helps because it is light at about 35kg, has 23-43 joints, and advertises up to 120N·m peak torque plus up to 2m/s motion speed, which is the raw actuation budget needed for explosive takeoff and recovery.
Under the hood, teams typically combine torque control with whole-body control and learned policies, where imitation learning copies reference motions and reinforcement learning (RL) tunes them to stay stable under small timing and contact errors.
The same “dynamic control at speed” theme shows up in competition results like G1’s 33.71s 100m hurdles win at the World Humanoid Robot Games.
Morgan Stanley’s says China logged 7,705 humanoid patents in 5 years versus 1,561 for the US and 1,102 for Japan, which matches the pattern of fast iteration plus a deep local supply chain.
And if you are thinking why the robots are so short, thre are many reasons to keep Unitree G1’s height short.
Commercially, it makes them cheaper, lighter, and easier to ship.
official spec lists height ~1320 mm, mass 35 kg, & it folds to about 690 mm, which keeps materials, actuators, and packaging costs down.
thats how Unitree could position G1 near $16,000 as a research platform.
Further, Physics wise, short lowers the center of mass, which increases tip-over margin for biped walking and manipulation. i.e. great for maintaining balance.
And then short reduces required joint torques and inertia, so the robot can accelerate limbs with less power and heat.
Bcz actuator and motor capability does not scale perfectly with size, and specific torque tends to cap out, so keeping link lengths small makes dynamic motions feasible without oversized motors or batteries.
and then, short improves practicality in labs and competitions. A 130 cm class body fits tight indoor spaces, is safer around people.
🛠️ A new METR estimate shows a big jump in 50% task horizon for Claude Opus 4.5
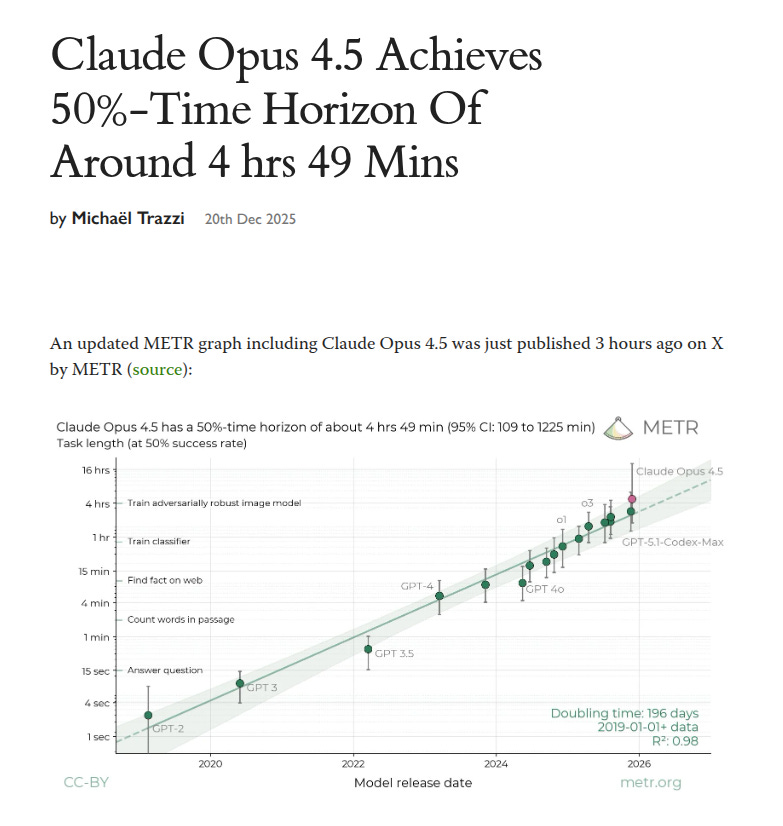
It means that on tasks that take a human about 4hrs49mins, Claude Opus 4.5 succeeds about half the time.
Model Evaluation and Threat Research (METR) defines a time horizon as the human-time length where an LLM finishes tasks at a chosen success rate, like 50% or 80%, in its methodology note .
On the same software engineering suite, the headline 50% horizon moved from about 1hr to 4hrs49mins, with a 95% confidence interval of 1hr49mins to 20hrs25mins .
METR says the top end is loose because there are too few very long tasks to tightly upper bound Opus 4.5 .
Because the task set is sparse in the 1-4hr band and can be shifted by training on cybersecurity capture-the-flag (CTF) work, the headline horizon is best treated as a noisy long-task signal for now .
Despite its high 50%-time horizon, Opus 4.5’s 80%-time horizon is only 27 minutes, similar to past models and below GPT-5.1-Codex-Max’s 32 mins.

The gap between them is basically measuring how fast reliability falls as tasks get longer.
That long tail usually happens because multi-hour tasks are not 1 hard step, they are many smaller steps, and the model only needs 1 critical mistake, like misunderstanding a requirement, breaking the build, or getting stuck, for the whole run to fail.
Overall, this suggests some 4-5hr attempts are now worth trying, but reliable autonomy still looks closer to 30mins.
That’s a wrap for today, see you all tomorrow.