
👨🔧 OpenAI’s newest product lets you vibe your way through coding science
SuperAgent, a new AI agents for science and complex projects, a frontier U.S. open-weight model, LLM failure maps, and smarter training paths to cut compute and engineering costs.
Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (28-Jan-2026):
👨🔧 OpenAI’s newest product lets you vibe your way through coding science. Will be a huge time saver for scientific work.
🧮 Superagent from Airtable is launched, an entirely new class of AI-agent for deeper thinking and complex projects.
🏆 New SOTA U.S. frontier open-weight model.
📡 The paper shows why LLM agents fail, then uses that failure map to guide strict answer verification.
🛠️ This paper uncovers a common map for weights, so future training can follow known routes, saving compute, storage, and engineering time.
👨🔧 Today’s Sponsor: SciSpace, the first AI Agent built exclusively for the scientific community, has released major upgrade
👨🔧 OpenAI’s newest product lets you vibe your way through coding science. Will be a huge time saver for scientific work.

The workflow starts with creating a project, then writing your paper in LaTeX with an always-on compile and PDF preview, so you see errors and formatting as you go. GPT-5.2 works in the context of your project, which means it can read your section structure, your equations, and your bibliography entries, then propose edits that match what is already there.
It aims to replace scattered writing, compile, citation, and chat tools with 1 project view. Old workflows bounce files across editors, LaTeX compilers, PDFs, and manual merges, then context gets lost.
Prism makes GPT-5.2 project-aware by reading structure, equations, references, and revisions inside the manuscript. That enables linked edits, like updating citations and sections together, instead of copy-paste drift.
It supports real-time coauthor edits with instant preview, plus proofreading, literature search, Zotero sync, and image-to-code. A typical loop could be, you paste reviewer comments into the project, ask GPT-5.2 to draft responses, then have it implement the edits in the right sections while keeping citations consistent.
Another loop is, you ask it to rewrite a paragraph for clarity, and it can keep your notation stable because it sees the surrounding definitions and equation labels. For references, the benefit is that it can help insert and fix citations in a way that compiles, instead of hallucinating random BibTeX keys that do not exist.
For LaTeX pain points, it can explain compile errors, suggest the minimal code change, and keep the fix local so you do not break the rest of the document. Prism is available now on the web to anyone with a ChatGPT personal account. OpenAI claims that around 1.3 million scientists around the world submit more than 8 million queries a week to ChatGPT on advanced topics in science and math.
🧮 Superagent from Airtable is launched, an entirely new class of AI-agent for deeper thinking and complex projects.
Superagent from Airtable is a new AI product that solves a fundamental problem with current AI: chatbots are great for quick answers, but they struggle with complex, multi-stage projects.
This tool moves away from the “chat” paradigm entirely and functions as an asynchronous research engine that can plan, execute, and build entire websites to present its findings.
🧱 Here is how it works: The system is designed to handle high-level, ambiguous business requests, such as “evaluate the competitive landscape of GPUs coming from Nvidia vs from China”
Instead of trying to answer this in a single shot, Superagent uses a many sub-agents. It then spins up independent sub-agents to execute these tasks in parallel.
For a single request, the system might deploy as many as 20 different sub-agents, each with different tools and capabilities. One agent might research market share, while another analyzes user engagement strategies, and a third looks into specific competitor technology stacks.
🔄 The Execution Loop: Once deployed, these agents perform distributed research using web browsing, code generation, and data analysis. They don’t just fetch data; they evaluate their own findings and can ask for guidance or reflect on whether they have solved their specific piece of the puzzle.
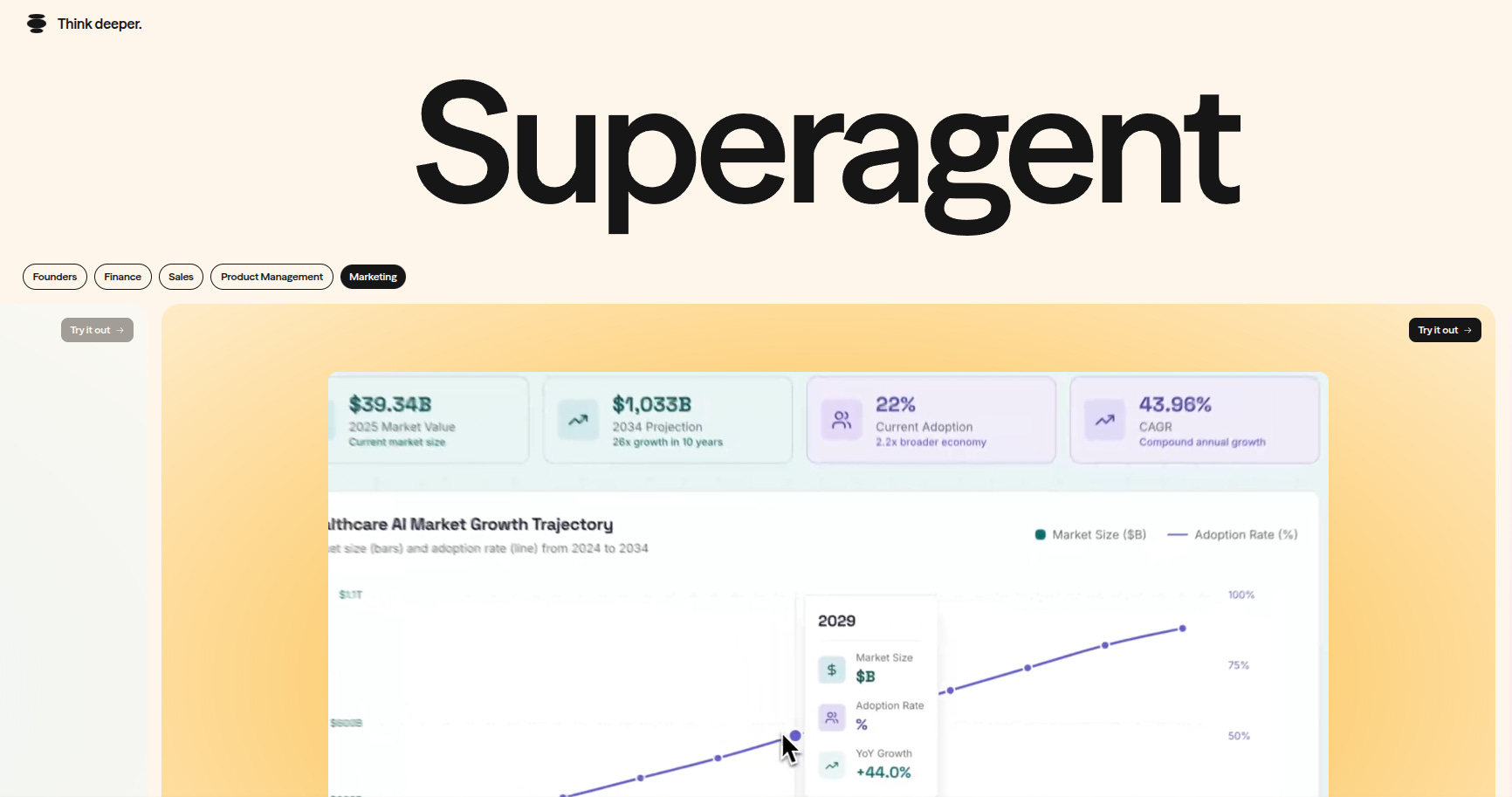
📊 The SuperReport: The primary output of Superagent is not a text summary, but what they call a SuperReport. This is a rich, fully interactive, aesthetically designed website generated on the fly.
It uses code generation to build interactive graphics, charts, and layout elements that explain complex concepts visually. The user receives a functional web page where they can interact with the data, rather than just reading a static PDF or a wall of text.
For those who need to verify the AI’s work, the system also provides a “long-form text report” view that includes direct citations for every claim.
⚡ Mass Concurrency and Custom Context: Because these tasks take time, the system is architected to handle massive concurrency. Users are encouraged to run multiple complex tasks simultaneously, treating the AI like a team of specialists working in parallel rather than a single conversational partner.
Beyond reports, the system can output its findings as slide decks, documents, or even prototype applications.
🏆 New SOTA U.S. frontier open-weight model.

They designed their own architecture from the ground up and training from scratch. Performance roughly in line with open Llama4 Maverick Instruct, while staying cheap to run by activating only 13B parameters per token via a very sparse 4-of-256 Mixture of Experts router, and it reports roughly 2-3x faster inference than peers in the same weight class on the same hardware.
400B total parameters
13B active parameters per token
256 experts with 4 active per token
High-sparsity architecture optimized for fast inference
On 8xH200 with FP8 in vLLM0.14.0, Trinity shows 8,717tok/s output throughput vs 3,624 for DeepSeek-V3 at 1,024/512, and 469,147ms end-to-end latency vs 1,648,371ms at 8,192/4,096.
They released 3 variants from the same training run:
• Trinity-Large-Preview – lightly post-trained and chat-ready
• Trinity-Large-Base – our full 17T-token pretraining checkpoint
• Trinity-Large-TrueBase – a 10T-token checkpoint with no instruction data or LR annealing
It also ships a rare research-grade checkpoint, Trinity-Large-TrueBase, that has 10T tokens of pure pretraining, before any instruction tuning that teaches chat behavior, and no learning-rate annealing. This will be very useful if someone wants a clean baseline before post-training.
Architecture
The engineering story is mostly about making high sparsity stable, using more dense layers plus momentum-based expert load balancing and z-loss to prevent routing collapse and runaway logit scale.
📡 The paper shows why LLM agents fail, then uses that failure map to guide strict answer verification.

Deep research agents, meaning LLMs that browse and use tools, often fail because 1 early mistake can snowball across many steps. The authors use 1 idea: checking an answer is often easier than producing it, so the agent should spend extra effort verifying.
DeepVerifier turns that into a workflow that flags likely failure types, asks up to 3 targeted follow up questions, then gives written feedback for a retry. They first study common agent mistakes to build the checklist, then test the verifier and retry loop on GAIA and other hard benchmarks.
DeepVerifier is a stronger checker than common LLM judges, and its feedback loop raises agent accuracy by about 8% to 11% on hard tasks. Because it works at inference time, meaning while the agent is answering, it can improve without extra training, and DeepVerifier-4K with 4,646 examples trains open models to self check.
🛠️ This paper uncovers a common map for weights, so future training can follow known routes, saving compute, storage, and engineering time.

Such a brilliant claim in this paper.
Says that many separately trained neural networks end up using the same small set of weight directions. Across about 1100 models, they find about 16 directions per layer that capture most weight variation.
A weight is just a number inside the model that controls how strongly a feature pushes another. They treat training as moving these numbers, and they say most movement stays inside a small shared subspace.
A subspace here means a short list of basis directions, so each task update is just a mix of them. They collect many models with the same blueprint, then break each layer’s weights into main directions and keep the shared ones.
They test this on Low Rank Adaptation (LoRA) adapters, which are small add on weights, and they even merge 500 Vision Transformers into 1 compact form. With the basis fixed, new tasks can be trained by learning only a few coefficients, which can save a lot of storage and compute.
👨🔧 Today’s Sponsor: SciSpace, the first AI Agent built exclusively for the scientific community, has released major upgrade
SciSpace just rolled out an Agent upgrade that cuts out a ton of hidden friction in research workflows.
This is the AI Agent that can use 150+ tools, 59 databases, and 280M+ papers
A few weeks back they launched BioMed Agent - It can design entire molecular biology workflows and even create publication-ready illustrations in a single prompt.
This is its new domain-specialized AI co-scientist that sits on top of the existing SciSpace Agent and automates full biomedical workflows, from raw data and papers to analysis, decisions, and the final production-grade illustrations. You just need to give it 1 prompt.
And today the added the following
Library Search, so it can search and analyze the PDFs already sitting in My Library, letting people ask questions across their own paper pile while keeping it private.
Now connects directly to Zotero, so the Agent can pull and work with the papers you already saved there without manual uploads.
For bigger prompts, it auto-triggers a Report Writing Sub-Agent that turns the chat into a structured research-style report, which is way cleaner for literature reviews and long summaries.
And when you get something worth keeping, Save to Notebook lets you store the output as .md notes with citations in My notebooks, so the work becomes reusable research notes instead of disappearing into chat.
Behind the scenes, it indexes the PDF text, pulls a few relevant chunks for the question, then writes an answer grounded on those chunks.
That’s a wrap for today, see you all tomorrow.