
🎖️ OpenAI's o1-preview Model Achieved 80% Accuracy on Medical Diagnosis vs 30% By Clinical Doctors
OpenAI's o1-preview outperforms Clinical Doctors, LangChain's 2024 AI forecast, Hume's OCTAVE voice model, xAI's $6B funding, AI taking over jobs, and strategies for small model fine-tuning.
Read time: 6 min 22 seconds
⚡In Today’s Edition (24-Dec-2024):
🎖️ OpenAI's o1-preview Model Achieved 80% Accuracy on Medical Diagnosis vs 30% By Clinical Doctors
🪄 LangChain Released State of AI 2024 based on data from LangSmith
🎤 Hume announced OCTAVE, their 3B API-only speech-language model capable of voice cloning
🗞️ Byte-Size Brief:
Elon Musk’s xAI has just officially announced the closing of their Series C funding round of $6 billion.
Sam Altman thinks that physical skills will become more valuable as AI takes over desk jobs.
🧑🎓 Deep Dive Tutorial
🧠 Investing in Performance: Fine-tune small models with LLM insights
👨🔧 Top Github Repo Roundup
👨🏭 awesome-llm-apps
👨🏭 OpikOpen source LLM evaluation framework
👨🏭 PDFMathTranslate: PDF scientific paper translation and bilingual comparison
🎖️ OpenAI's o1-preview Model Achieved 80% Accuracy on Medical Diagnosis vs 30% By Clinical Doctors
🎯 The Brief
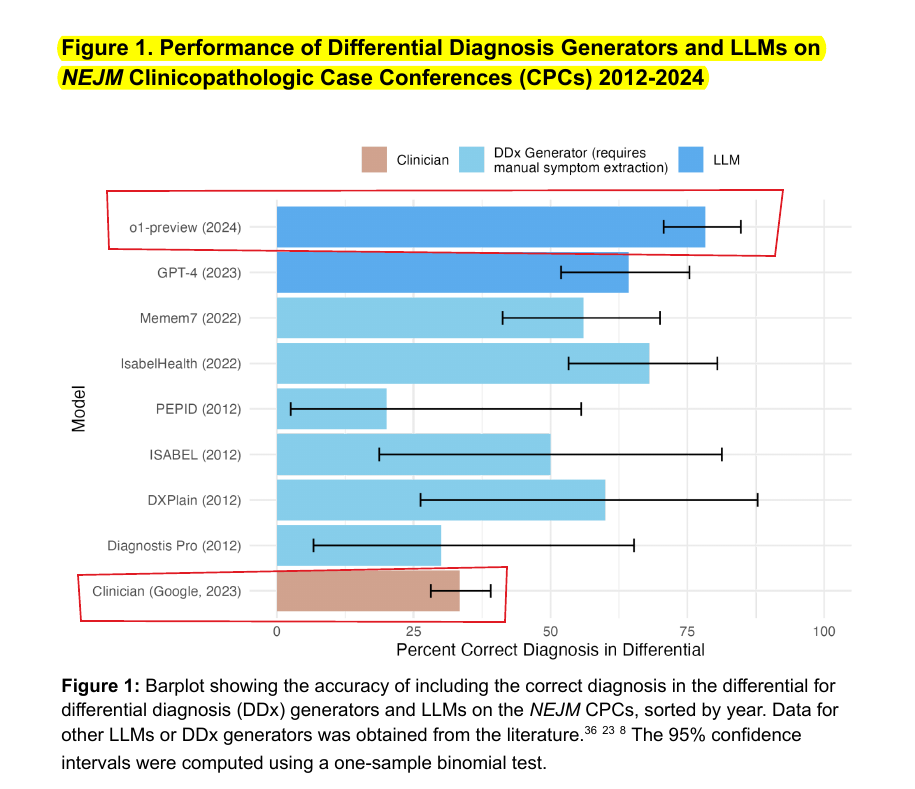
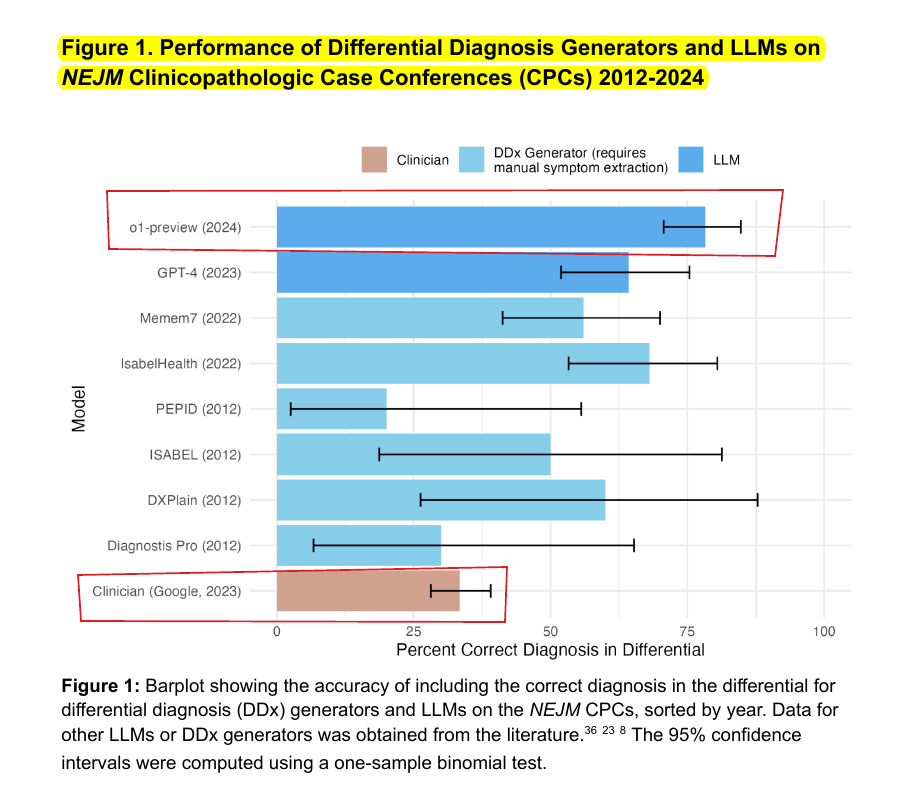
New research finds OpenAI's o1-preview model demonstrates superhuman performance in medical reasoning tasks, achieving 88.6% accuracy in diagnostic challenges versus GPT-4's 72.9%, while showing remarkable improvements in diagnostic reasoning and clinical management but maintaining similar performance in probabilistic assessment.
⚙️ The Details
→ Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance.
→ The performance of o1-preview was characterized with five experiments including differential diagnosis, diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics.
→ The model excels in differential diagnosis generation, surpassing both GPT-4 and human baselines. In diagnostic test selection, o1-preview achieved 87.5% accuracy in choosing correct tests, with an additional 11% deemed helpful by physician evaluators.
→ However, in probabilistic reasoning tasks, o1-preview showed no significant improvements over GPT-4, particularly in estimating pre-test and post-test probabilities. This limitation suggests constraints in the model's ability to handle uncertainty quantification.
→ The model's enhanced performance is attributed to its native chain-of-thought processing at runtime, enabling deeper reasoning before response generation. This capability particularly benefits complex medical analysis tasks.
🪄 LangChain Released State of AI 2024 based on data from LangSmith
🎯 The Brief
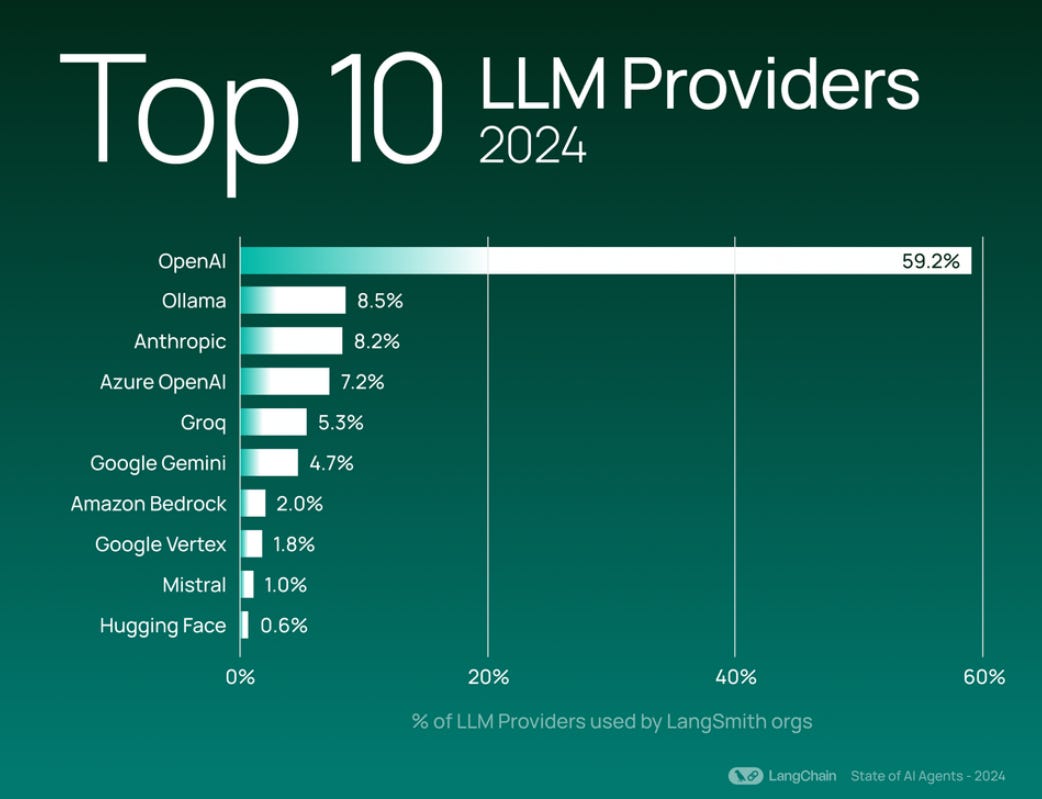
LangChain released comprehensive analysis showcasing LLM ecosystem evolution, highlighting 30k monthly LangSmith signups and significant shifts in AI development patterns - from basic retrieval to complex agent workflows, with OpenAI commanding 59.2% market share.
⚙️ The Details
→ The LLM provider landscape shows OpenAI's dominance at 59.2% usage, Interestingly, Ollama and Groq (which both allow users to run open source models, with the former focusing on local execution and the latter on cloud deployment) have accelerated in momentum this year, breaking into the top 5. Open-source providers collectively represent 20% of top LLM usage, demonstrating growing interest in flexible deployment options.
→ Developer workflows have become more sophisticated, with average steps per trace increasing from 2.8 to 7.7, while LLM calls grew modestly from 1.1 to 1.4, indicating more efficient complex operations. 43% of organizations now utilize LangGraph for agent development.
→ Tool calling has seen dramatic growth from 0.5% to 21.9%, showing strong adoption of agentic behaviors. Quality evaluation focuses primarily on relevance, correctness, and exact matching, with feedback volume increasing to 2.59 entries per run, though remaining relatively sparse.
→ Vector store preferences remain consistent with Chroma and FAISS leading, while Milvus, MongoDB, and Elastic emerged as new top contenders. Python SDK dominates with 84.7% usage, though JavaScript adoption grew 3x year-over-year.
🎤 Hume announced OCTAVE, their 3B API-only speech-language model capable of voice cloning

🎯 The Brief
Hume Research launches OCTAVE, a new speech-language model combining voice synthesis and personality generation. It processes prompts in under 300ms and requires only 5 seconds of audio for voice cloning, while maintaining core LLM capabilities.
⚙️ The Details
→ OCTAVE (Omni-Capable Text and Voice Engine) merges functionalities from EVI 2, OpenAI's Voice Engine, Elevenlab's TTS, and Google Deepmind's NotebookLM. The system generates comprehensive personality profiles including accents, expressions, and underlying dispositions from text prompts.
→ The model demonstrates two key innovations: prompt-based personality creation and voice continuation. From simple descriptive prompts like "scholarly wizard mentor," it produces complete voice and personality profiles. Using brief 5-second audio samples, it replicates both voice characteristics and personality traits.
→ OCTAVE supports real-time multi-agent interactions, enabling multiple AI personalities to engage simultaneously while maintaining LLM capabilities for tool usage and interface control.
🗞️ Byte-Size Brief
Elon Musk’s xAI has just officially announced the closing of their Series C funding round of $6 billion. To note, xAI’s most powerful model yet, Grok 3, is currently training. The Series C funding round includes investments from major players like Nvidia, AMD, BlackRock, and Morgan Stanley, highlighting growing confidence in xAI's approach to advancing artificial intelligence capabilities. NVIDIA’s decision to invest in xAI ‘s speaks volumes. They get paid if xAI continues to build better models because they will continue to buy more GPUs.
If xAI becomes one of the largest foundation models and seriously competes with GPT, Gemini & Claude, then they likely will HAVE to continue buying the latest GPUs to stay competitive.
A tweet went viral referring to Sam Altman’s opinion that physical skills become more valuable as AI takes over desk jobs. This technological shift creates an inverted job market where traditional "prestigious" cognitive work loses exclusivity. Meanwhile, hands-on professions like plumbing, surgery, and logistics gain increased market value through their AI-resistant physical components.
🧑🎓 Deep Dive Tutorial
🧠 Investing in Performance: Fine-tune small models with LLM insights

This detailed blog shows how to optimize financial NER by combining LLMs with smaller models to achieve high accuracy at lower costs.
📚 Technical Skills You'll Master
Implementing LLM-assisted data labeling pipeline using Hugging Face Inference Endpoints
Setting up Argilla for streamlined annotation review and validation
Building efficient batch processing systems with AsyncInferenceClient for parallel requests
Configuring Pydantic schemas for structured output validation
Optimizing model deployment costs through GPU/CPU instance selection
Advanced NER techniques:
Fuzzy matching with rapidfuzz
Levenshtein distance clustering
Entity normalization strategies
Fine-tuning optimization:
Focal loss implementation
Learning rate scheduling
Batch size optimization
Model checkpoint management
Performance evaluation:
F1-score calculation
Cost-benefit analysis
Inference latency measurement
Resource utilization tracking
Infrastructure scaling:
GPU instance management
Async processing patterns
Memory optimization
Throughput maximization
👨🔧 Top Github Repo Roundup
👨🏭 awesome-llm-apps
Your one-stop shop for building real LLM apps that actually work, and skip the LLM learning curve.
Build 42 production-ready RAG and agent applications spanning customer support, legal, and finance domains. Access implementations for GitHub repo chat, Gmail integration, and PDF analysis. Features both cloud LLMs (OpenAI, Anthropic, Google) and open-source alternatives for local deployment. Includes complete codebases for memory systems, hybrid search, and multi-agent architectures. All implementations are properly documented with step-by-step deployment guides.
👨🏭 OpikOpen source LLM evaluation framework
Track LLM application performance with comprehensive tooling for development, testing, and production monitoring. Built-in metrics for hallucination detection, RAG evaluation, and content moderation. Supports 12+ major LLM frameworks. Run locally via Docker or use cloud-hosted version. Integrates with CI/CD pipelines through PyTest. Features high-volume trace logging and real-time monitoring dashboards.
👨🏭 PDFMathTranslate: PDF scientific paper translation and bilingual comparison
Translate academic PDFs across languages while preserving mathematical notation, figures, and document structure. Features 95% formula preservation, multi-threaded processing, and supports custom prompts. Uses DocLayout-YOLO for layout parsing with 98% accuracy. Integrates with Google, DeepL, and Azure translation APIs for >40 languages.