
🌐 OpenAI's Realtime API with WebRTC
Use WebRTC to connect client-side applications to the Realtime API.


WebRTC powers OpenAI's latest Realtime API, enabling real-time voice interactions directly in web browsers
🌐 WebRTC: The Engine Behind Real-Time Communication
WebRTC stands for Web Real-Time Communication - an open-source project that enables real-time communication of audio, video, and data directly between browsers and devices. It strips away complex networking details, enabling direct peer-to-peer connections without specialized plugins or apps.
The core architecture revolves around WebRTC peer connections for handling audio streams and a data channel for exchanging events. This enables bidirectional communication between the client and AI model.
For OpenAI's Realtime API, WebRTC solves several critical technical challenges:
Network Resilience: WebRTC includes sophisticated algorithms for handling unstable network conditions. It automatically adapts to changing bandwidth, packet loss, and latency - critical for maintaining fluid AI conversations.
Media Pipeline Optimization: The framework provides native APIs for audio capture and playback. This means developers don't need to build complex audio handling logic:
// WebRTC handles complex audio setup with just a few lines
const ms = await navigator.mediaDevices.getUserMedia({audio: true});
pc.addTrack(ms.getTracks()[0]);
NAT Traversal: WebRTC handles the complexities of establishing peer connections across different networks and firewalls through ICE (Interactive Connectivity Establishment), STUN (Session Traversal Utilities for NAT), and TURN (Traversal Using Relays around NAT) protocols.
WebRTC's data channels provide a reliable way to exchange events and control messages alongside the audio stream. This enables features like real-time text transcripts, function calls, and interruption handling:
const dc = pc.createDataChannel("oai-events");
dc.send(JSON.stringify({
type: "response.create",
response: { modalities: ["text"] }
}));
The architecture uses Session Description Protocol (SDP) for negotiating connection parameters. This standardized approach ensures compatibility and optimal media configuration between the browser and OpenAI's servers.
By leveraging WebRTC, OpenAI's Realtime API inherits enterprise-grade real-time communication capabilities that have been battle-tested across video conferencing and online gaming applications. This provides a robust foundation for building responsive AI voice interfaces directly in web browsers.
Security is handled through ephemeral API keys that expire in 60 seconds. These temporary keys are generated server-side using your standard OpenAI API key, making client-side authentication secure. Here's a Node.js implementation:
app.get("/session", async (req, res) => {
const r = await fetch("https://api.openai.com/v1/realtime/sessions", {
method: "POST",
headers: {
"Authorization": `Bearer ${process.env.OPENAI_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
model: "gpt-4o-realtime-preview-2024-12-17",
voice: "verse",
}),
});
res.send(await r.json());
});
This endpoint handles ephemeral token generation. The server uses your OpenAI API key to request a temporary token, which is then safely passed to the client.
Below example shows how to initialize a WebRTC session
This code sets up a live audio connection between your browser and OpenAI’s model by using WebRTC and a data channel for events. The key idea is to start by retrieving a short-lived ephemeral key from your own server. Instead of embedding your main credentials directly into client-side code, you fetch a temporary token from a backend endpoint. This keeps your sensitive keys safe on the server side.
Once you have the ephemeral key, the code creates a RTCPeerConnection object, which is a special browser API that allows real-time communication. It sets up an audio element that plays back any incoming audio tracks from the model. By calling navigator.mediaDevices.getUserMedia with {audio: true}, the code accesses your microphone and adds its audio track to the connection. This lets the remote AI model hear what you say.
async function init() {
// Get an ephemeral key from your server - see server code below
const tokenResponse = await fetch("/session");
const data = await tokenResponse.json();
const EPHEMERAL_KEY = data.client_secret.value;
// Create a peer connection
const pc = new RTCPeerConnection();
// Set up to play remote audio from the model
const audioEl = document.createElement("audio");
audioEl.autoplay = true;
pc.ontrack = e => audioEl.srcObject = e.streams[0];
// Add local audio track for microphone input in the browser
const ms = await navigator.mediaDevices.getUserMedia({
audio: true
});
pc.addTrack(ms.getTracks()[0]);
// Set up data channel for sending and receiving events
const dc = pc.createDataChannel("oai-events");
dc.addEventListener("message", (e) => {
// Realtime server events appear here!
console.log(e);
});
// Start the session using the Session Description Protocol (SDP)
const offer = await pc.createOffer();
await pc.setLocalDescription(offer);
const baseUrl = "https://api.openai.com/v1/realtime";
const model = "gpt-4o-realtime-preview-2024-12-17";
const sdpResponse = await fetch(`${baseUrl}?model=${model}`, {
method: "POST",
body: offer.sdp,
headers: {
Authorization: `Bearer ${EPHEMERAL_KEY}`,
"Content-Type": "application/sdp"
},
});
const answer = {
type: "answer",
sdp: await sdpResponse.text(),
};
await pc.setRemoteDescription(answer);
}
init();It then creates a data channel named "oai-events". This data channel is a general-purpose communication line between your browser and the model’s servers. Here, it logs any incoming realtime events the server sends back. These might include text messages, function call requests, or notifications that the model is done speaking. Because the data channel is just a string-based messaging system, you can receive and send structured JSON messages easily.
After setting up both the audio track and the data channel, the code uses SDP (Session Description Protocol) to describe its capabilities. It calls pc.createOffer() to generate an offer, sets that as the local description, and then sends it to the OpenAI endpoint along with the ephemeral key. The server responds with an SDP answer, which the code sets as the remote description. At that point, the WebRTC handshake completes, and a live connection is established.
The code does not show responses playing yet, but once the connection is up, you will hear the AI’s voice through the audio element. Any realtime events or transcripts sent by the server will show up in the console through the data channel’s message event. This entire process happens in real time, allowing for low-latency, streaming interactions.
🔐 Why Ephemeral API Keys in Browser-Based AI is so important for Security?
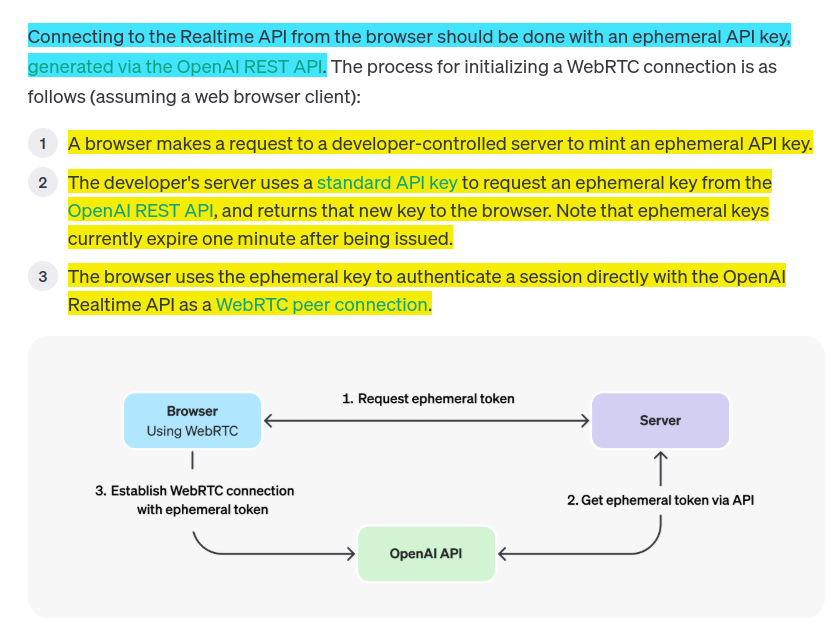
The most interesting aspect of the new WebRTC mechanism of OpenAI is its support for ephemeral tokens.
Standard API keys grant full access to your OpenAI account and resources. Exposing these in browser-based code would be catastrophic - anyone could extract them from your JavaScript and rack up massive API usage bills or misuse your account.
In order to connect to their endpoint you need to provide an API key, but that meant making that key visible to anyone who uses your application. The only secure way to handle this was to roll a full server-side proxy for their WebSocket API, just so you could hide your API key in your own server. cloudflare/openai-workers-relay is an example implementation of that pattern.
So the ephemeral key system solves this major security problem.
And the Ephemeral tokens solve that by letting you make a server-side call to request an ephemeral token which will only allow a connection to be initiated to their WebRTC endpoint for the next 60 seconds. The user's browser then starts the connection, which will last for up to 30 minutes.
// Server-side: Generate temporary key
app.get("/session", async (req, res) => {
const response = await fetch("https://api.openai.com/v1/realtime/sessions", {
headers: { "Authorization": `Bearer ${process.env.OPENAI_API_KEY}` },
// ... other config
});
const data = await response.json();
res.send(data.client_secret.value);
});
// Client-side: Use temporary key
const tokenResponse = await fetch("/session");
const EPHEMERAL_KEY = await tokenResponse.json();
These temporary tokens provide time-bounded access - they expire after 60 seconds. This tight time window minimizes potential damage even if tokens are compromised.
The system creates a security boundary between your sensitive API credentials and client-side code. Your main API key stays secure on your server while browsers only receive short-lived tokens with limited permissions.
This architecture follows the principle of least privilege - clients get only the minimum access needed for their immediate task. Combined with WebRTC's built-in security features, this creates a robust foundation for secure real-time AI interactions in browsers.
The ephemeral system also enables fine-grained access control and usage monitoring since each client session gets its own unique token. This helps track and manage API usage at a granular level.
The client-side implementation starts with establishing a WebRTC peer connection. This creates an audio pipeline between the browser and OpenAI's servers:
const pc = new RTCPeerConnection();
const audioEl = document.createElement("audio");
audioEl.autoplay = true;
pc.ontrack = e => audioEl.srcObject = e.streams[0];
Media handling is streamlined through WebRTC's built-in APIs. The code captures local microphone input and sets up automatic playback of the model's audio responses.
The data channel is crucial for event exchange:
const dc = pc.createDataChannel("oai-events");
dc.addEventListener("message", (e) => {
const realtimeEvent = JSON.parse(e.data);
});
This channel handles various event types including text responses, audio segments, function calls, and interruptions. Events are serialized as JSON strings for transmission.
The connection setup uses the Session Description Protocol (SDP) for negotiating media capabilities:
const offer = await pc.createOffer();
await pc.setLocalDescription(offer);
const sdpResponse = await fetch(`${baseUrl}?model=${model}`, {
method: "POST",
body: offer.sdp,
headers: {
Authorization: `Bearer ${EPHEMERAL_KEY}`,
},
});
This establishes the peer-to-peer connection between the browser and OpenAI's servers. The SDP exchange defines the media capabilities and connection parameters.
The entire system operates in real-time, with WebRTC handling network conditions, packet loss, and latency compensation automatically. This makes it ideal for building responsive AI voice interfaces that work directly in web browsers.
Implementations of OpenAI’s Realtime API so you can talk to GPT-4o through your browser's microphone
To write the below code, took a huge helpf from Claude, and I passed OpenAI’s smaller code examples and related docs to Claude.
This code sets up a browser-based audio session with an AI model over a WebRTC connection. It uses ephemeral keys to securely connect your browser to the AI service without exposing sensitive credentials. The idea is to stream audio from your microphone to an AI model and then receive real-time voice responses back, all directly within your browser.
In the beginning, the code reads an ephemeral key from local storage if one was previously saved. If not, you type it in. This key is a short-lived token that grants temporary permission to use the AI's real-time features without revealing your main API key to the browser environment. It forms the backbone of a secure session, ensuring that if someone tries to access your code, they cannot misuse your primary credentials.
When you press the start button, the code requests access to your microphone through the browser's built-in APIs. It sets up an AudioContext and an Analyser node to measure the audio levels, visually indicating that the microphone is active. By analyzing frequency data, it updates a small circle indicator to show you that the microphone is actually capturing sound.
To run the below code, save the code as index.html. Then run a local server using Python (`python -m http.server 8000`) or Node.js (`npx http-server`).
Then navigate to localhost:8000. Ensure you have a valid ephemeral key, and using s browser that supports microphone permissions, and with WebRTC support.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>Secure AI Voice Session</title>
</head>
<body>
<div class="outer-wrap">
<h1>
<span id="micIndicator" class="mic-level-indicator"></span>
Secure AI Voice Session
</h1>
<div class="ui-block">
<div class="input-row">
<label for="secretKeyField">Ephemeral Access Key</label>
<input type="password" id="secretKeyField" />
</div>
<div class="input-row">
<label for="voicePicker">Voice Profile</label>
<select id="voicePicker">
<option value="ash">Ash</option>
<option value="ballad">Ballad</option>
<option value="coral">Coral</option>
<option value="sage">Sage</option>
<option value="verse">Verse</option>
</select>
</div>
<button id="sessionToggleButton">Launch Conversation</button>
</div>
<div id="connectionFeedback" class="feedback"></div>
</div>
<script type="module">
async function initiateRealtimeConnection(inputAudio, ephemeralCredential, chosenVoice) {
const peerConn = new RTCPeerConnection();
peerConn.ontrack = eventObj => {
const remoteAudio = new Audio();
remoteAudio.srcObject = eventObj.streams[0];
remoteAudio.play();
};
peerConn.addTrack(inputAudio.getTracks()[0]);
const browserOffer = await peerConn.createOffer();
await peerConn.setLocalDescription(browserOffer);
const connectionRequestHeaders = {
Authorization: `Bearer ${ephemeralCredential}`,
'Content-Type': 'application/sdp'
};
const connectionRequestParams = {
method: 'POST',
body: browserOffer.sdp,
headers: connectionRequestHeaders
};
const chosenModel = 'gpt-4o-realtime-preview-2024-12-17';
const remoteResponse = await fetch(`https://api.openai.com/v1/realtime?model=${chosenModel}&voice=${chosenVoice}`, connectionRequestParams);
const remoteAnswer = await remoteResponse.text();
await peerConn.setRemoteDescription({
type: 'answer',
sdp: remoteAnswer
});
return peerConn;
}
const sessionToggleButton = document.getElementById('sessionToggleButton');
const secretKeyField = document.getElementById('secretKeyField');
const voicePicker = document.getElementById('voicePicker');
const connectionFeedback = document.getElementById('connectionFeedback');
const micIndicator = document.getElementById('micIndicator');
let activePeer = null;
let soundCtx = null;
let micStream = null;
document.addEventListener('DOMContentLoaded', () => {
const savedKey = localStorage.getItem('ephemeral_credentials');
if (savedKey) {
secretKeyField.value = savedKey;
}
});
function monitorMicLevel(inputFlow) {
soundCtx = new AudioContext();
const micSource = soundCtx.createMediaStreamSource(inputFlow);
const freqAnalyzer = soundCtx.createAnalyser();
freqAnalyzer.fftSize = 256;
micSource.connect(freqAnalyzer);
const dataLen = freqAnalyzer.frequencyBinCount;
const freqData = new Uint8Array(dataLen);
function visualize() {
if (!soundCtx) return;
freqAnalyzer.getByteFrequencyData(freqData);
const sumLevels = freqData.reduce((sum, val) => sum + val, 0);
const avgLevel = sumLevels / dataLen;
micIndicator.classList.toggle('active', avgLevel > 30);
requestAnimationFrame(visualize);
}
visualize();
}
async function startConversation() {
try {
localStorage.setItem('ephemeral_credentials', secretKeyField.value);
connectionFeedback.className = 'feedback';
connectionFeedback.textContent = 'Requesting audio capture';
micStream = await navigator.mediaDevices.getUserMedia({
audio: true,
video: false
});
monitorMicLevel(micStream);
connectionFeedback.textContent = 'Establishing peer link';
activePeer = await initiateRealtimeConnection(
micStream,
secretKeyField.value,
voicePicker.value
);
connectionFeedback.className = 'feedback success';
connectionFeedback.textContent = 'Session active';
sessionToggleButton.textContent = 'End Session';
} catch (errorObj) {
connectionFeedback.className = 'feedback error';
connectionFeedback.textContent = `Error: ${errorObj.message}`;
console.error('Error during session setup:', errorObj);
endConversation();
}
}
function endConversation() {
if (activePeer) {
activePeer.close();
activePeer = null;
}
if (soundCtx) {
soundCtx.close();
soundCtx = null;
}
if (micStream) {
micStream.getTracks().forEach(track => track.stop());
micStream = null;
}
micIndicator.classList.remove('active');
sessionToggleButton.textContent = 'Launch Conversation';
}
sessionToggleButton.addEventListener('click', () => {
if (activePeer) {
endConversation();
} else {
if (!secretKeyField.value) {
connectionFeedback.className = 'feedback error';
connectionFeedback.textContent = 'Please provide a valid ephemeral key';
return;
}
startConversation();
}
});
window.addEventListener('beforeunload', endConversation);
</script>
</body>
</html>
The code then creates a RTCPeerConnection, which is the essential WebRTC object for enabling two-way audio communication. It adds your microphone track to this connection so that remote servers can receive your audio. Using WebRTC means the browser handles all the complexity of audio routing, buffering, and sending data efficiently over the network.
The code uses Session Description Protocol (SDP) to describe its media capabilities and receive matching parameters from the remote AI service. It creates an offer with pc.createOffer() and sets that offer as its local description. Then it sends this offer, along with your ephemeral key, to the AI endpoint. The server responds with an SDP answer, which the code sets as its remote description. At this point, the peer connection knows how to send your microphone input out and how to receive synthesized speech back from the server.
Because the code handles audio streams through WebRTC, it automatically plays back the AI’s voice through a standard HTMLAudioElement. Once the connection is established, any incoming audio track from the AI model is simply piped into that audio element. The code also manages a data pipeline for events by relying on WebRTC's internal mechanisms, so the entire voice response process is real-time and feels immediate.
If something goes wrong, the code prints an error message. It also provides a stop function that gracefully closes the peer connection, halts the audio analysis, and stops the microphone tracks. By doing this, the code ensures it leaves no lingering resources running in your browser after you end the session.
In summary, the code uses a short-lived token (ephemeral key), WebRTC for real-time audio streaming, and the browser's audio APIs to create a secure, responsive voice session with an AI model. This architecture abstracts away the complexities of handling media and network conditions while ensuring that your primary credentials remain safe on the server side.
And below example shows how you could replicate a similar idea from the browser-based code using Python in a Google Colab environment.
First note that Colab does not have a native WebRTC client built-in like a browser. We must rely on Python libraries like aiortc.
We will use aiortc (a Python library for WebRTC) to establish a WebRTC connection. Instead of capturing live mic input from your computer’s microphone (which is easy in browser JavaScript), we might simulate it by using a pre-recorded audio file or generating silent audio frames.
Likewise, playing back received audio is not straightforward in a pure Colab environment.
However, this code demonstrates the underlying signaling steps and connection establishment logic that you could adapt.
# Before running this, you need to:
# → Ensure you have aiortc installed
# → Have a valid ephemeral key retrieval endpoint or a known ephemeral key
# → Understand that real-time audio I/O may not fully work in Colab as it would in a browser
# In Colab, run:
# !pip install aiortc requests
import asyncio
import json
import uuid
import requests
from aiortc import RTCPeerConnection, RTCSessionDescription, MediaStreamTrack
from aiortc.contrib.media import MediaBlackhole, MediaRecorder
from aiortc.contrib.signaling import BYE
# Replace with your actual OpenAI API Key
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY"
# This function simulates retrieving a short-lived (ephemeral) token. In a real scenario,
# you would run a server-side endpoint that uses your main API key to get a temporary token
# and then return it to the client (in this case, the Colab environment).
def get_ephemeral_key(model, voice):
# Just an example of requesting a realtime session token.
# This POST request returns a temporary session object containing ephemeral credentials.
url = "https://api.openai.com/v1/realtime/sessions"
headers = {
"Authorization": f"Bearer {OPENAI_API_KEY}",
"Content-Type": "application/json",
}
body = {
"model": model,
"voice": voice
}
resp = requests.post(url, headers=headers, json=body)
data = resp.json()
# In reality, you’d parse the response for the ephemeral key or client_secret
# Here we assume data["client_secret"]["value"] contains the ephemeral token.
ephemeral_token = data["client_secret"]["value"]
return ephemeral_token
class SilentAudioTrack(MediaStreamTrack):
"""
A dummy audio track that generates silence. This is just a placeholder,
since we are not capturing a real microphone in Colab.
"""
kind = "audio"
def __init__(self):
super().__init__()
async def recv(self):
# Generate a silent frame
frame = None
# You would need to create an empty audio frame here if needed.
# For demonstration, we won't produce actual audio frames.
await asyncio.sleep(0.02)
return frame
async def main():
# Choose a model and voice that the realtime API supports
chosen_model = "gpt-4o-realtime-preview-2024-12-17"
chosen_voice = "verse"
ephemeral_token = get_ephemeral_key(chosen_model, chosen_voice)
# Create RTCPeerConnection for WebRTC
pc = RTCPeerConnection()
# Add a dummy audio track (silence or pre-recorded file) to simulate sending audio.
# In a real scenario, you would use a real microphone input.
audio_track = SilentAudioTrack()
pc.addTrack(audio_track)
# Create an SDP offer
offer = await pc.createOffer()
await pc.setLocalDescription(offer)
# Send the offer to the OpenAI realtime endpoint along with ephemeral token
headers = {
"Authorization": f"Bearer {ephemeral_token}",
"Content-Type": "application/sdp"
}
# Note: In a real scenario, you'd fetch from
# `https://api.openai.com/v1/realtime?model={chosen_model}&voice={chosen_voice}`
# Here we assume direct connectivity and that OpenAI responds with a valid SDP answer.
response = requests.post(
f"https://api.openai.com/v1/realtime?model={chosen_model}&voice={chosen_voice}",
headers=headers,
data=offer.sdp
)
if response.status_code != 200:
print("Failed to get remote SDP answer:", response.text)
return
answer_sdp = response.text
# Set remote description
await pc.setRemoteDescription(
RTCSessionDescription(answer_sdp, type="answer")
)
# At this point, we have a live WebRTC connection. The AI model should be sending
# audio back. Without a browser environment or a real media sink, we can just print
# that the connection is established.
print("WebRTC connection established with AI model.")
# Since we cannot easily play audio in Colab from a live WebRTC connection,
# we just wait here. In a real environment, you would process incoming tracks,
# listen for data channel messages, etc.
await asyncio.sleep(10) # Wait a bit before hanging up.
# Close connection
await pc.close()
print("Connection closed.")
# Run the asyncio main function
asyncio.run(main())