
"Optimizing LLM Training Using FP4 Quantization"
Below podcast on this paper is generated with Google's Illuminate.

https://arxiv.org/abs/2501.17116
Leveraging FP4 quantization for training LLMs is difficult due to accuracy loss from quantization errors and limited data representation.
This paper introduces a novel FP4 training framework for LLMs. It addresses the challenges using a differentiable quantization estimator and outlier management techniques.
-----
📌 FP4 training is amazing because what it signifies is that, if you can achieve "almost" the same results as FP16 by FP4, there is a high chance that you can scale your model by 4 times in training. Meaning your next generation "small model" would be 4x larger than right now, which is basically the current "medium model".
📌 And if you are greedy enough (which you should), your "large model" would also be 4x larger than the current large model. This is in algorithm/code training level, meaning that you don't need to have more money to buy more gpus. Just BANG! Directly 4x larger. So yeah, the scaling of LLM is not stopping any time soon IMO.
📌 Differentiable Gradient Estimator (DGE) is a key contribution. It tackles gradient inaccuracies inherent in low-bit quantization by using a differentiable approximation, leading to more precise weight updates in FP4 training.
📌 Outlier Clamping and Compensation (OCC) is crucial for activation quantization in FP4. By managing outliers and compensating for clamped values, OCC prevents accuracy degradation and stabilizes FP4 training of LLMs.
📌 Vector-wise quantization is essential for FP4's success. Token-wise activation and channel-wise weight quantization, unlike tensor-wise, minimizes quantization error accumulation specific to FP4 precision.
----------
Methods Explored in this Paper 🔧:
→ The paper proposes a FP4 training framework for LLMs. It uses E2M1 format for FP4 representation.
→ The framework incorporates a Differentiable Gradient Estimator (DGE) for weight updates. DGE approximates the non-differentiable quantization function to improve gradient estimation during backpropagation. This involves a correction term in gradient calculation to account for quantization.
→ For activations, the framework uses Outlier Clamping and Compensation (OCC). OCC clamps outlier activation values to a threshold determined by a quantile. A sparse auxiliary matrix compensates for the error introduced by clamping, preserving accuracy.
→ Vector-wise quantization is used for stability. Token-wise quantization is applied to activations and channel-wise quantization to weights. Mixed-precision training is employed to maintain accuracy for non-GeMM operations.
-----
Key Insights 💡:
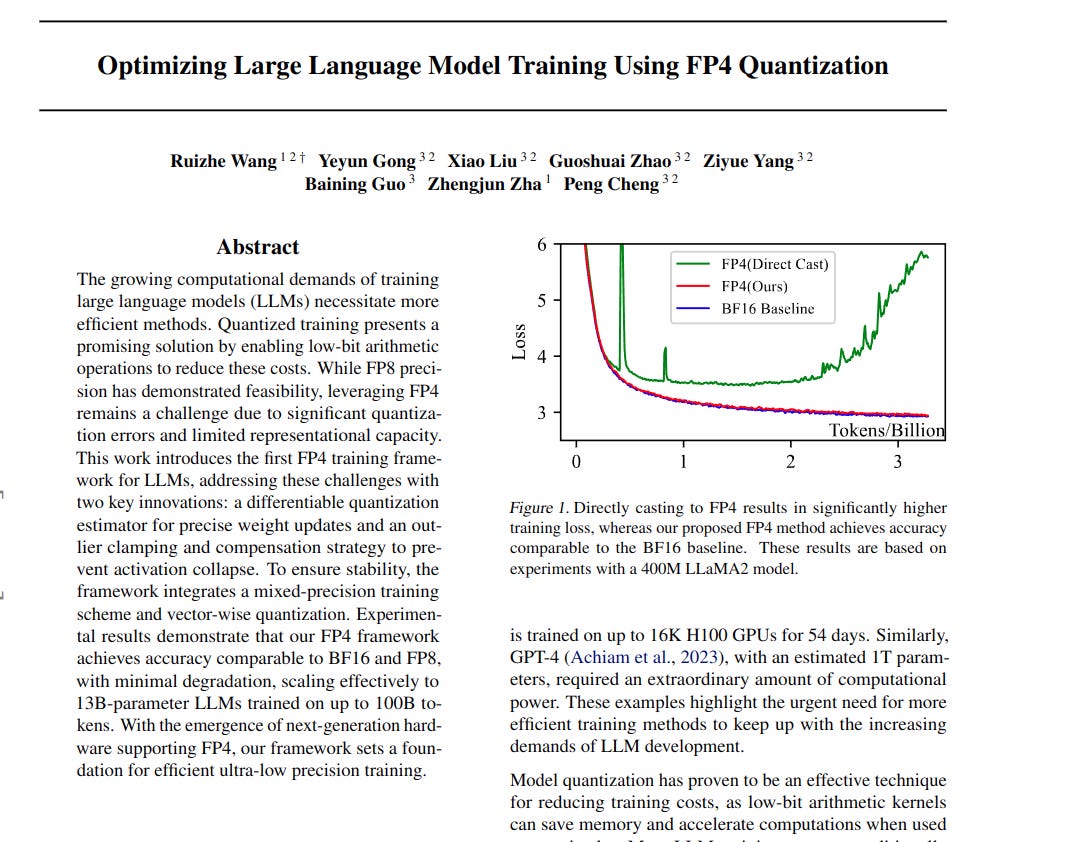
→ Direct FP4 quantization leads to significant accuracy degradation in LLM training.
→ The Differentiable Gradient Estimator (DGE) method improves gradient updates in FP4 training by providing a more accurate gradient estimation than Straight-Through Estimator (STE).
→ The OCC method effectively handles activation outliers, preventing performance collapse during FP4 training. Activation quantization is more challenging than weight quantization due to outliers and wider dynamic range.
→ Vector-wise quantization is crucial for FP4 training compared to tensor-wise quantization used in FP8.
-----
Results 📊:
→ FP4 training achieves comparable performance to BF16 training on LLaMA models up to 13B parameters. Training loss of FP4 is slightly higher than BF16, for 13B model loss is 1.97 (FP4) vs 1.88 (BF16) after 100B tokens.
→ Zero-shot evaluation shows FP4-trained models achieve average accuracy comparable to BF16-trained models across downstream tasks. For 13B model, average accuracy is 54.95% (FP4) vs 54.44% (BF16).
→ Ablation studies confirm the effectiveness of DGE and OCC. Direct FP4 quantization diverges, while DGE and OCC stabilize training and maintain accuracy.