
"Over-Tokenized Transformer: Vocabulary is Generally Worth Scaling"
Below podcast on this paper is generated with Google's Illuminate.

https://arxiv.org/abs/2501.16975
The paper addresses the challenge of tokenization in LLMs. Current tokenization methods might not fully leverage the scaling potential of LLMs.
This paper proposes "Over-Tokenized Transformers". It decouples input and output vocabularies by scaling up input vocabularies using multi-gram tokens to enhance performance without increasing computational cost.
-----
📌 Over-Encoding cleverly expands input vocabulary without increasing computational cost. It achieves better performance with similar sized models by using multi-gram embeddings. This method effectively decouples input tokenization from model size, enhancing scaling efficiency.
📌 Hierarchical n-gram embedding in Over-Encoding provides richer contextual input. By summing 1-gram to n-gram representations, the model captures multi-granularity information. This improves token representation quality and downstream task performance.
📌 Over-Tokenized Transformer offers a practical approach to improve LLMs. Tensor parallelism for embedding layers mitigates memory pressure from large vocabularies. This makes deploying larger input vocabularies feasible and efficient in practice.
----------
Methods Explored in this Paper 🔧:
→ The paper introduces "Over-Encoding" (OE). OE uses large hierarchical n-gram input vocabularies.
→ OE sums embeddings of 1-gram, 2-gram, and up to n-gram tokens to represent input. This captures multi-granularity information.
→ To manage large n-gram vocabularies, OE employs tiled matrix parameterization. This method approximates large embedding tables efficiently.
→ OE also uses sliced embedding tables for further performance gains. It splits embedding tables along the dimension and sums them after low-rank projection.
→ The paper also explores "Over-Decoding" (OD). OD uses larger output vocabularies for finer-grained supervision during training. Multi-Token Prediction (MTP) is considered an approximation of OD.
→ "Over-Tokenized Transformer" (OT) combines OE and OD for enhanced performance.
-----
Key Insights 💡:
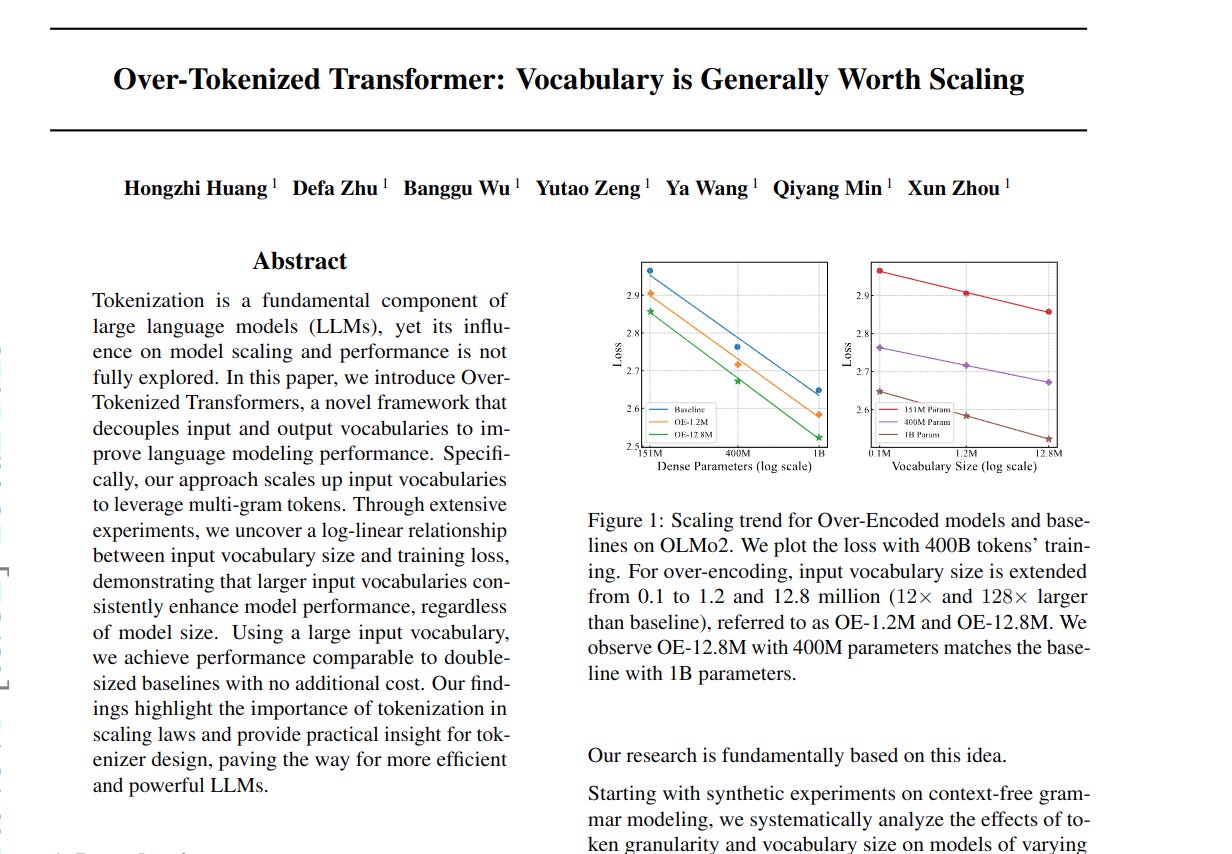
→ Larger input vocabularies consistently improve LLM performance, regardless of model size. This suggests a log-linear relationship between input vocabulary size and training loss.
→ Scaling up the input vocabulary via OE achieves performance comparable to doubling model size, without additional computational cost.
→ Decoupling input and output vocabularies is crucial. Scaling output vocabulary can be detrimental for smaller models, while input vocabulary scaling is generally beneficial.
→ Hierarchical n-gram encoding in OE effectively captures contextual information, improving model representation.
-----
Results 📊:
→ OE achieves 5.7× speedup in training loss convergence on OLMo2-1B compared to baseline.
→ Downstream task performance acceleration with OE on OLMo2-1B: MMLU-Var by 3.2×, Hellaswag by 3.0×, ARC-Challenge by 2.6×, ARC-Easy by 3.1×, and PIQA by 3.9×.
→ OLMoE-1.3B with OE-12.8M achieves a training loss of 2.472, a reduction of 0.082 compared to the baseline loss of 2.554.
→ Log-linear relationship observed: for every 4× increase in input vocabulary size, training loss decreases by approximately 0.015.