
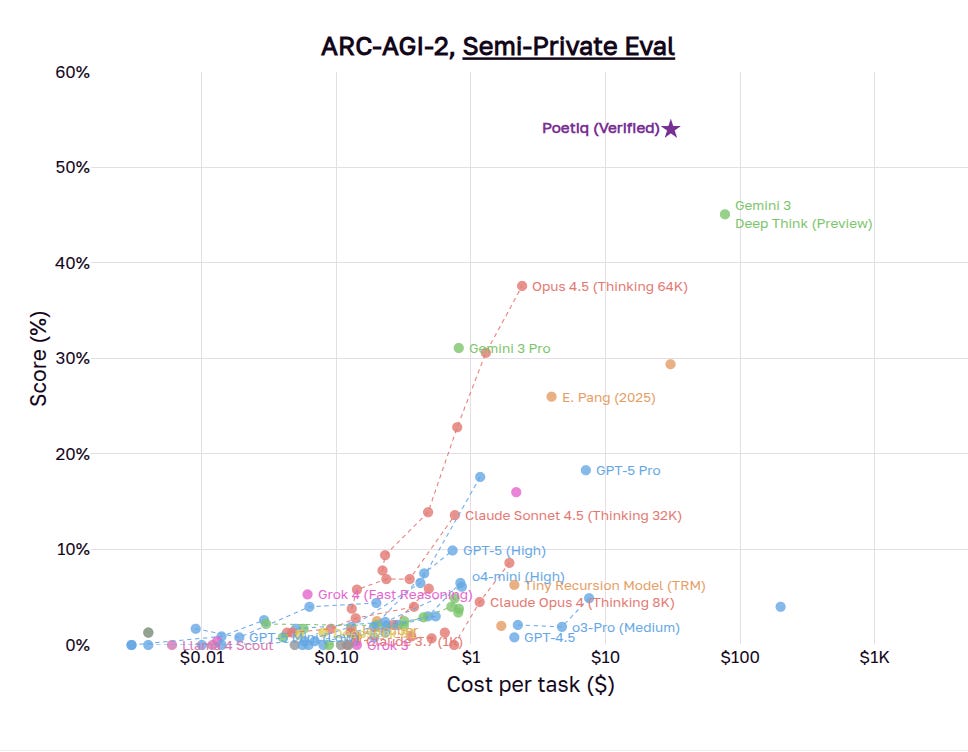
🧠 Poetiq, a startup barely 170 days old, has scored 54% on ARC-AGI-2, putting it ahead of Deep Think.
Poetiq beats Deep Think on ARC-AGI-2, Google says TPU FLOPS aren’t the limit, Qwen3-TTS gets 49+ voices, OpenAI invests in enterprise AI, and Instacart hits ChatGPT.
Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (8-Dec-2025):
🧠 Poetiq, a startup barely 170 days old, has scored 54% on ARC-AGI-2, putting it ahead of Deep Think.
🛠️ FLOPS are NOT the bottleneck anymore - A Google presentation on TPU
🏆 Alibaba’s Qwen3-TTS update adds 49+ voices, 10 languages, and 9 dialects, so apps get character-specific speech instead of 1 generic voice
📡 OpenAI acquires stake in Thrive Holdings to accelerate enterprise AI adoption
💳 Now, you can buy your Instacart groceries without leaving ChatGPT
🧠 Poetiq, a startup barely 170 days old, has scored 54% on ARC-AGI-2, putting it ahead of Deep Think.
The ARC Prize has confirmed Poetiq’s record-breaking ARC-AGI-2 score. It hit 61% on the public benchmark, then 54% on the semi-private dataset, keeping its lead over Gemini 3 Deep Think. The team built it using a mix of Gemini 3 Pro, GPT-5.1, and a custom scaffold setup.
This establish an entirely new Pareto frontier on the public ARC-AGI-2 set.
The interesting part is that no base model is retrained at all, and yet smart orchestration plus code execution moves scores in a range that people previously expected only from much bigger or more expensive models.
ARC-AGI-2 is a benchmark made of tiny colored-grid puzzles where the model must spot a pattern from a few examples, then generate the correct output grid, so it checks true pattern reasoning rather than recall of facts.
Frontier models usually fail here because they jump to 1 or 2 shallow guesses, do not systematically test alternatives, and do not really incorporate feedback from failed attempts into a better next step.
Poetiq treats each puzzle like debugging a tricky bug in code where the system proposes a hypothesis, runs it, checks if the output fits all examples, criticizes the failure mode, then updates the plan.
Poetiq trains a meta system on many practice tasks so it learns when to think, when to write code, which model to use, and how to update after failures.
This separate meta-system sits on top and calls existing APIs like Gemini 3 Pro, GPT-5.1, Grok 4 Fast, and GPT-OSS, and it keeps the loop tight so it uses fewer than 2 calls per task on average to keep costs low.
For each ARC problem the controller picks a model, asks for a candidate program, runs it on the examples, has the model explain mismatches, and retries with a refined program.
This controller can also write small programs when that helps, execute them, and then audit the outputs for consistency with all the provided examples, which pushes the grid puzzles closer to classical automated program synthesis.
Self auditing lets the controller stop once grids look consistent, which keeps usage near 2 model calls per problem and still costs less than half of Gemini 3 Deep Think.
Because the controller is model agnostic and can plug in new frontier models within hours, learned orchestration plus code execution now looks as important as backbone size for hard reasoning benchmarks.
🛠️ FLOPS are NOT the bottleneck anymore - A Google presentation on TPU

For large LLMs, the main limit in inference is no longer how many FLOPs the chip can do, it is how fast it can move data in and out of memory.
Several recent profiling studies show that during LLM inference the GPU is often waiting on memory rather than saturating its peak FLOPs. A recent paper titled “Mind the Memory Gap” finds that even at large batch sizes, LLM inference remains memory‑bound, with DRAM bandwidth saturation the primary bottleneck and a large fraction of cycles stalled on memory access instead of math units doing work.
If you add more FLOPs, that means you add more raw math capability. But if the memory is already the bottleneck and cannot deliver data any faster, those extra FLOPs do not help much.
Google has been increasingly focusing that memory is the main constraint. Google’s Ironwood TPU (the inference‑focused v7) was introduced with 192 GB of HBM3e per chip, 7.2–7.3 TB/s of memory bandwidth, and a 9,216‑chip pod that exposes 1.77 PB of shared HBM. Google’s own marketing and Hot Chips presentations leaned heavily on those memory numbers as the headline feature rather than just FLOPs.
This is why the current generation of AI accelerators is built around HBM. NVIDIA’s Blackwell B100 and B200 use a dual die GB100 design with 192GB of HBM3e and up to 8 TB/s of memory bandwidth, and system boards pack over 1TB of HBM per node.
NVIDIA’s own material and independent breakdowns highlight this memory subsystem first, then talk about FLOPs. The goal is simple, keep the tensor cores constantly fed instead of stalled on memory.
If inference is structurally HBM bound, more of the value in the stack flows to advanced memory. SK hynix, Samsung and Micron dominate HBM supply, with SK hynix holding about 70% share of HBM shipments, and all 3 are investing billions into new HBM fabs as AI demand accelerates.
That benefits memory vendors, but it also strengthens NVIDIA’s moat because it is the anchor customer that shapes HBM roadmaps and secures the earliest, fastest parts. In a world where bandwidth is the bottleneck, whoever sits closest to the HBM supply chain and builds the best memory centric systems, gains a durable advantage, and today that is still NVIDIA.
🏆 Alibaba’s Qwen3-TTS update adds 49+ voices, 10 languages, and 9 dialects, so apps get character-specific speech instead of 1 generic voice
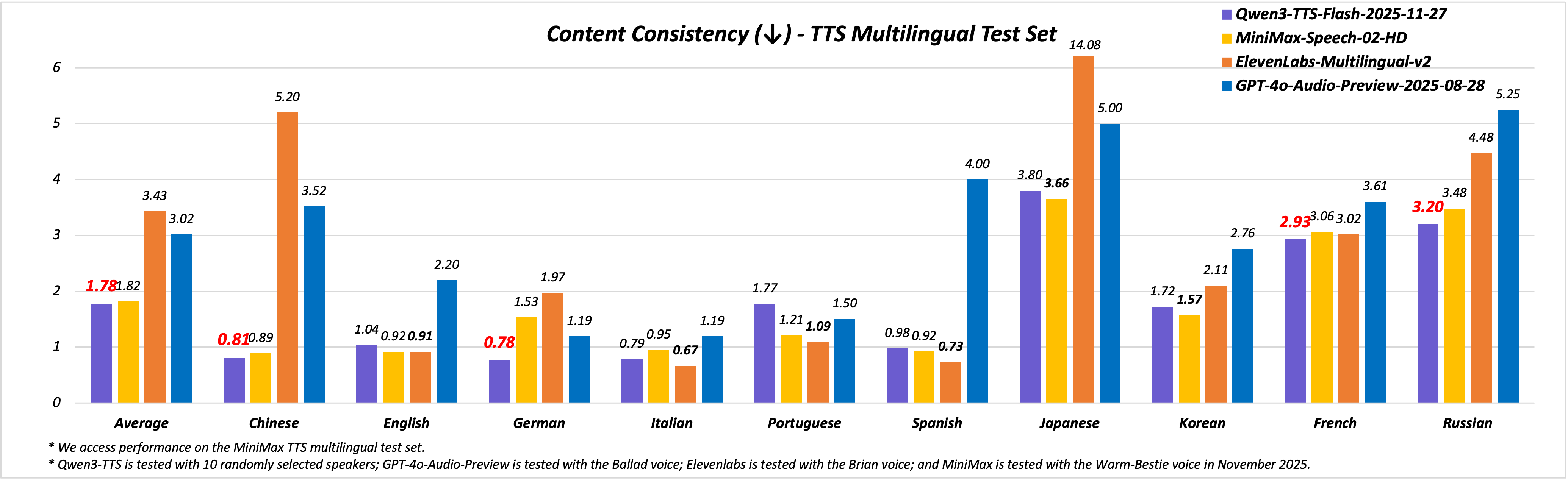
Qwen3-TTS-Flash takes text plus a timbre token and directly generates waveform audio for that voice.
Those 49+ timbres cover gender, age, accent, and attitude, which lets products keep a game hero, tutor, or narrator sounding consistent without recording every line.
Training on 10 languages and 9 Chinese dialects bakes pronunciation and local rhythm into the model, so multilingual or regional Chinese content does not need phoneme hacks or stitched vendors.
Alibaba reports lower WER than MiniMax, ElevenLabs, and GPT-4o-Audio-Preview and better prosody control, so speech usually matches the script while pacing and emphasis follow text cues.
Qwen3-TTS gives Alibaba a practical speech stack upgrade that leans on more speakers, better accents, and better rhythm instead of just scaling base model size.
Overall this feels like an engineering-first upgrade for teams that want controllable multilingual voices without juggling many TTS products.
📡 OpenAI acquires stake in Thrive Holdings to accelerate enterprise AI adoption

OpenAI is taking an equity stake in Thrive Holdings, a new platform built by one of its own major investors, focusing on accounting and IT services.
This is OpenAI stepping beyond APIs into full-on operating mode - part consulting, part product lab, part model-training partner.
OpenAI is not putting cash into Thrive Holdings, instead it is getting equity in exchange for access to its models and for embedding its own people into Thrive’s portfolio companies to rebuild workflows like accounting, tax, IT support, and back-office operations using custom enterprise models.
This means OpenAI is moving from just selling API access to acting almost like an operator, where its engineers help redesign entire processes, capture the upside through ownership, and potentially generate data and deployment patterns that make its models more attractive for other enterprises.
Thrive, which invested in OpenAI at valuations around $27B and then $157B, has set up Thrive Holdings as a kind of private-equity style roll-up that buys or builds service businesses and then tries to scale them, and those are exactly the kinds of high-headcount, rule-heavy environments where LLM-based automation can remove a lot of manual work.
Critics worry this adds to a pattern of circular deals in AI, where capital, equity, chips, and cloud contracts move inside a tight loop among the same players, which can make growth and demand look stronger than it really is, even while genuine technical value is being created.
From a technical and strategic angle, the interesting part is that OpenAI is treating “AI in the enterprise” less like a generic platform sale and more like a full-stack intervention, where model design, fine-tuning, integration, and process redesign are all done together and the upside is partly paid in ownership.
My view is that this is a serious escalation of how deeply a model developer can get into an industry’s plumbing, and if it works at scale it will push other labs to choose between staying a neutral infrastructure provider or becoming operators with real skin in the game.
⚖️ New York Times sues Perplexity AI for ‘illegal’ copying of millions of articles

New York Times has sued Perplexity AI, saying the startup built and runs its chatbot on millions of NYT articles including paywalled stories and then shows NYT branding next to made up outputs, turning this into a combined copyright and trademark fight.
NYT claims Perplexity copied, stored, and reused full news stories at scale to answer user questions, so Perplexity is not just summarizing links but competing directly with the newspaper’s own site and apps.
On the trademark side, NYT says Perplexity sometimes fabricates facts yet still shows the NYT name and logo, which can make users believe the hallucinated text is real NYT reporting, and that is the core Lanham Act argument.
Perplexity answers that it only indexes public web pages, does not train its base models on scraped news in the way critics claim, and that legacy publishers are using lawsuits as a way to slow new search products.
At the same time Perplexity is already being sued by Dow Jones, New York Post, Chicago Tribune, Encyclopedia Britannica, Reddit, and Amazon over similar patterns of scraping, repackaging, or accessing data in ways those companies say break their rules.
For anyone building AI search or assistants, the real risk is that courts may treat large scale reuse of full text news, especially paywalled content plus logos, as infringement rather than fair use, which would push the ecosystem toward explicit licenses and tighter technical blocks.
In my view this case is one of the clearest tests so far of whether generative answer engines can lean on unlicensed premium journalism, and a strong ruling either way will quickly reshape how serious players handle training data and output branding.
Courts are basically being asked to decide whether AI search is closer to a traditional search index or closer to an unlicensed syndication service, and that answer will decide who pays whom in the next generation of news aware models.
💳 Now, you can buy your Instacart groceries without leaving ChatGPT

OpenAI and Instacart are turning ChatGPT into a grocery shopping agent that goes from recipe idea to completed order inside 1 chat.
A user talks about meals, diet rules, budget, or timing, and ChatGPT turns that free form text into a structured Instacart cart.
Under the hood, the model calls Instacart search and pricing APIs, matches real products, suggests substitutions, and keeps a consistent shopping list state as the user edits.
This sits inside OpenAI’s broader agentic commerce push, where ChatGPT talks to partner apps and can also earn a small fee per Instacart sale for each completed order.
ChatGPT will act like a grocery planning and checkout agent, where someone types what they want to eat or their diet rules, and it quietly turns that into a live Instacart order behind the scenes.
A user might say something like “plan 5 simple vegetarian dinners for 2 people this week under $80”, and ChatGPT will propose meals, then translate that text into structured product picks on Instacart such as brands, sizes, and quantities.
Under the hood, the model keeps an internal shopping session state, calls Instacart search and pricing APIs, maps ingredients to store items, and updates that state every time the user says things like “swap the tofu brand” or “make that gluten free”.
When the user is happy, ChatGPT hands off the built cart to Instacart checkout, using the user’s saved address and payment, so what looked like free form chat is actually a sequence of tool calls that end in a real transaction.
For OpenAI, this fits into a larger pattern where agents inside ChatGPT orchestrate multi step workflows across external apps and earn a small fee on each completed sale.
That’s a wrap for today, see you all tomorrow.