
Programming Every Example: Lifting Pre-training Data Quality like Experts at Scale
Method proposed in this paper uses tiny LLMs to clean massive datasets, making big LLMs smarter while using 20x less data.


Method proposed in this paper uses tiny LLMs to clean massive datasets, making big LLMs smarter while using 20x less data.
Small LLMs write Python code to refine training data.
Basically, Mini AI plays data detective, catches bad examples before they confuse larger models
Original Problem 🤔:
Pre-training data for LLMs often relies on human-crafted heuristics, which are inflexible and hard to scale for individual data examples.
Solution in this Paper 🛠️:
Introduces Programming Every Example (ProX), a framework using small language models (0.3 billion parameters) for data refinement.
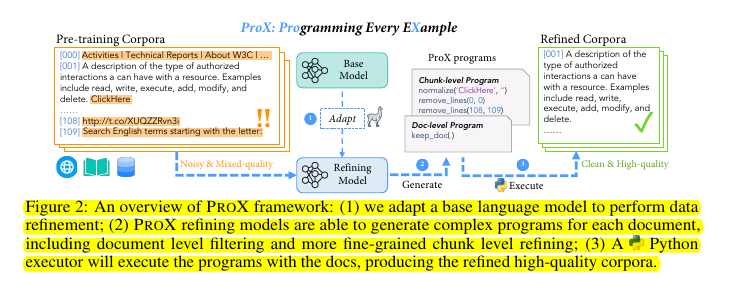
Treats data refinement as a programming task, allowing models to generate and execute operations like filtering and string normalization.
ProX adapts small base models to refining tasks through fine-tuning, generating programs for each example in the corpus.
Executes these programs using a Python executor to produce refined data ready for pre-training.
Key Insights from this Paper 💡:
Small models can refine data effectively, comparable to human experts.
ProX improves pre-training efficiency by reducing computational costs.
The framework is flexible across different model sizes and corpora.
Results 📊:
ProX-curated data improves model performance by over 2% on various benchmarks.
In domain-specific continual pre-training, ProX improves accuracy by 7.6% for MISTRAL-7B, 14.6% for LLAMA-2-7B, and 20.3% for CODELLAMA-7B.
Achieves similar performance with up to 20 times fewer tokens compared to traditional methods.
ProX leverages small language models to generate and execute fine-grained operations like filtering and string normalization for each example in the pre-training corpus. This method improves data quality with less computational cost compared to rule-based systems.
Essential Questions and Answers
🧠 The central theme or argument of the research paper
The paper introduces "Programming Every Example" (ProX), a framework that uses small language models to autonomously refine pre-training data at scale, treating data refinement as a programming task. This approach aims to improve data quality more efficiently than traditional heuristic-based methods.
🔍 Key supporting ideas of the research
📈 Important facts or evidence presented in the research
ProX-curated data leads to an average performance improvement of over 2% across various benchmarks.
It shows significant gains in domain-specific continual pre-training, outperforming human-crafted methods by a substantial margin.
ProX achieves these improvements while using significantly fewer tokens and computational resources compared to traditional models.
🎯 The author's purpose or perspective
The authors aim to demonstrate that even small language models can effectively refine large-scale pre-training data, offering a scalable and efficient alternative to manual rule-based data processing. They propose that this method can significantly enhance the efficiency and effectiveness of large language model pre-training.