QA-MDT: Quality-aware Masked Diffusion Transformer for Enhanced Music Generation
Newly released Opensource Text-to-music. Diffusion Transformer for Enhanced Music Generation 🎹


Newly released Opensource Text-to-music.
Diffusion Transformer for Enhanced Music Generation 🎹
Original Problem 😕:
Text-to-music (TTM) generation faces challenges due to limited high-quality paired data. Open-source datasets suffer from low-quality music waveforms, mislabeling, weak labeling, and unlabeled data, hindering the development of music generation models.
Solution in this Paper 🔧:
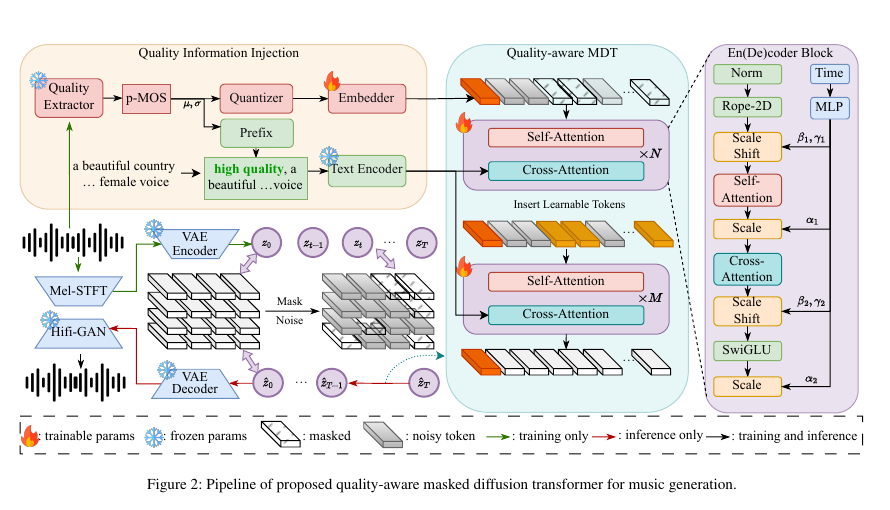
• Introduced Quality-aware Masked Diffusion Transformer (QA-MDT). That is, their training approach can distinguish between high-quality and low-quality music inputs, which is crucial for generating better music.
Injects quantified pseudo-MOS scores into denoising stage
Integrates coarse-level quality info into text encoder
Embeds fine-level details into transformer-based diffusion architecture
Uses masking strategy to enhance spatial correlation of music spectrum
• Implemented caption refinement approach:
Utilizes LLMs and CLAP model to improve text-audio correlation
Filters and fuses captions to enhance dataset quality
Key Insights from this Paper 💡:
• Quality-aware training enables models to discern input music quality during training
• Masked diffusion transformer (MDT) improves quality control and musicality in TTM
• Caption refinement addresses low-quality captions in TTM datasets
• Combining quality awareness and MDT enhances generation quality and text alignment
Results 📊:
• Outperformed previous methods on MusicCaps and Song-Describer Dataset
• Achieved lower FAD (1.65) and KL divergence (1.31) scores on MusicCaps
• Improved human ratings for overall quality (3.69) and text relevance (4.19) from professional music producers
The 2 key points
Quality-aware training strategy: The researchers developed a new approach that allows the AI model to understand and consider the quality of the music it's learning from during the training process. This means the model can distinguish between high-quality and low-quality music inputs, which is crucial for generating better music.
Masked Diffusion Transformer (MDT) for Text-to-Music (TTM): They adapted an existing AI architecture called a Masked Diffusion Transformer specifically for the task of turning text descriptions into music. This model type is well-suited for understanding the unique patterns and structures found in music.