RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation
RAGCache slashes LLM response times by remembering previously retrieved document states across multiple user queries


RAGCache slashes LLM response times by remembering previously retrieved document states across multiple user queries
Stop computing twice: RAGCache remembers document states to make RAG lightning quick
Original Problem 🎯:
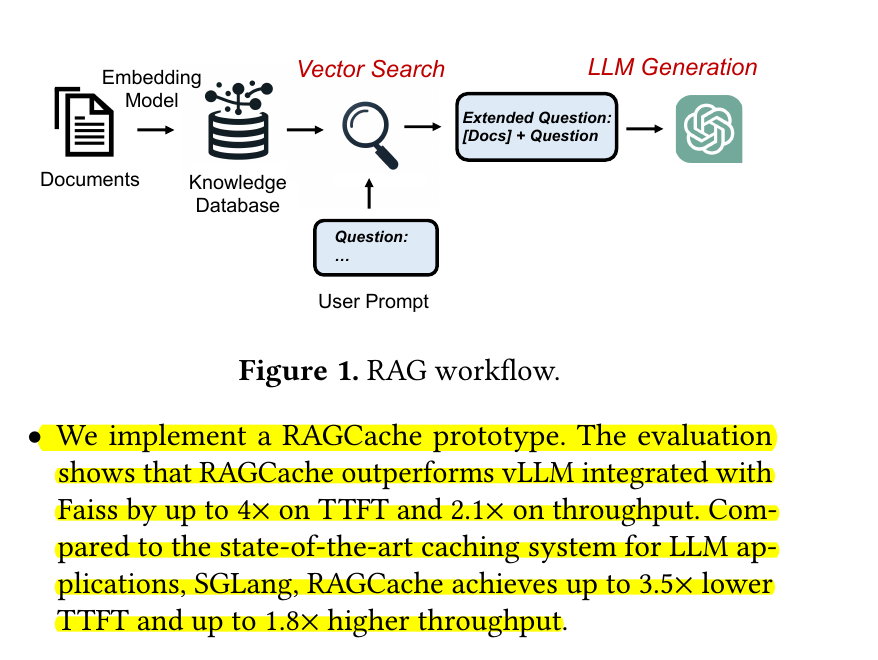
RAG systems face performance bottlenecks due to long sequence generation when injecting retrieved documents into requests. This causes high computation and memory costs, as retrieved documents can add 1000+ tokens to a 100-token request.
Solution in this Paper 🔧:
• RAGCache introduces a multilevel dynamic caching system that caches intermediate states of retrieved documents across multiple requests
• Uses a knowledge tree structure to organize cached states in GPU and host memory hierarchy
• Implements prefix-aware Greedy-Dual-Size-Frequency (PGDSF) replacement policy considering document order, size, frequency and recency
• Features dynamic speculative pipelining to overlap retrieval and inference steps
• Includes cache-aware request scheduling to improve hit rates under high load
Key Insights 💡:
• A small fraction of documents (3%) accounts for majority (60%) of retrieval requests
• Caching intermediate states can reduce prefill latency by up to 11.5x
• Document order sensitivity in RAG requires special handling in caching
• GPU-host memory hierarchy can be effectively leveraged for caching
• Vector retrieval and LLM inference can be overlapped for better latency
Results 📊:
• Reduces time to first token (TTFT) by up to 4x compared to vLLM with Faiss
• Improves throughput by up to 2.1x over vLLM with Faiss
• Achieves up to 3.5x lower TTFT compared to SGLang
• Delivers up to 1.8x higher throughput than SGLang
• Maintains performance gains across different models and retrieval settings
🚀 How does RAGCache achieve performance improvements?
RAGCache organizes intermediate states of retrieved documents in a knowledge tree and caches them in GPU and host memory hierarchy.
It uses a prefix-aware Greedy-Dual-Size-Frequency (PGDSF) replacement policy that considers document order, size, frequency and recency. It also implements dynamic speculative pipelining to overlap retrieval and inference steps.
This design reduces time to first token by up to 4x and improves throughput by up to 2.1x compared to vLLM with Faiss.