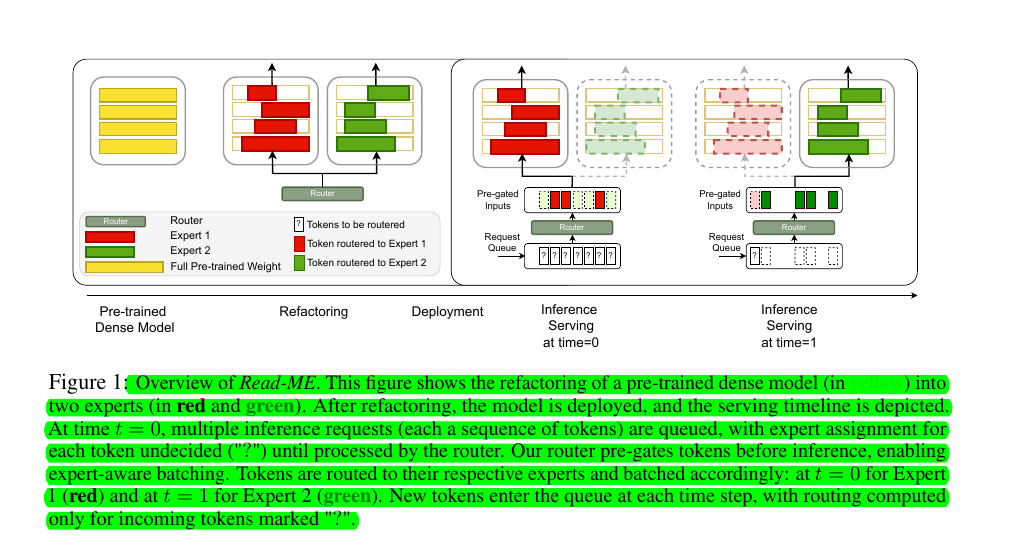
Read-ME: Refactorizing LLMs as Router-Decoupled Mixture of Experts with System Co-Design
Single router replaces redundant layer-wise routing for faster LLM inference


Why use many routers when one smart router does the trick?
Single router replaces redundant layer-wise routing for faster LLM inference
This Paper's method, Read-ME transforms large LLMs into efficient MoEs by decoupling routing from model backbone
• Achieves 10.1% improvement on MMLU benchmark vs similar-scale models
🤖 Original Problem:
Current Mixture-of-Experts (MoE) LLMs face two major challenges: inefficient memory management and suboptimal batching during inference, plus prohibitively expensive training costs. Layer-wise routing in MoEs complicates efficient prefetching and expert caching.
🔧 Solution in this Paper:
• Introduces Read-ME: transforms pre-trained dense LLMs into smaller MoE models using activation sparsity
• Implements pre-gating router decoupled from MoE backbone, enabling expert pre-computing
• Uses single router instead of layer-wise routers to reduce redundancy
• Implements Belady-inspired caching strategy for optimal expert management
• Requires only 1B tokens for training vs trillions needed traditionally
• Enables expert-aware batching through pre-gating mechanism
💡 Key Insights:
• Layer-wise routing decisions in MoEs are highly redundant
• Expert selections between adjacent layers show strong correlation
• Pre-gating enables system-level optimizations previously impossible
• Temporal locality in token routing can be leveraged for efficient caching
📊 Results:
• Reduces mean latency by 6.1% and improves tail latency by 10%
• Achieves 88.03% cache hit ratio with 5 expert cache capacity
• Outperforms other compression techniques with only 1B training tokens
💡 The way Read-ME enables efficient inference:
Pre-gates tokens before inference to enable expert-aware batching
Uses a single router instead of layer-wise routers to reduce redundancy
Implements optimal expert caching strategy inspired by Belady's algorithm
Enables pre-fetching of exact expert layers needed for tokens