
Reinforcement Learning from Human Feedback (RLHF) in Practice: A Deep Dive
In this article, I will break down RLHF in a step-by-step manner to provide a reference for understanding its core ideas and then implementing a RLHF pipeline with deepspeed-chat


In short, the table of contents of this article is as follows:
The fundamental building blocks and flow of RLHF
Implementing and code walkthrough of RLHF training with DeepSpeed.
Some existing issues with RLHF and their possible solutions.
RLHF has emerged as a pivotal technique in the development of advanced language models and AI systems. The core idea is to use human preferences to guide the model's learning process, allowing it to align more closely with human values and expectations.
Introduction to RLHF
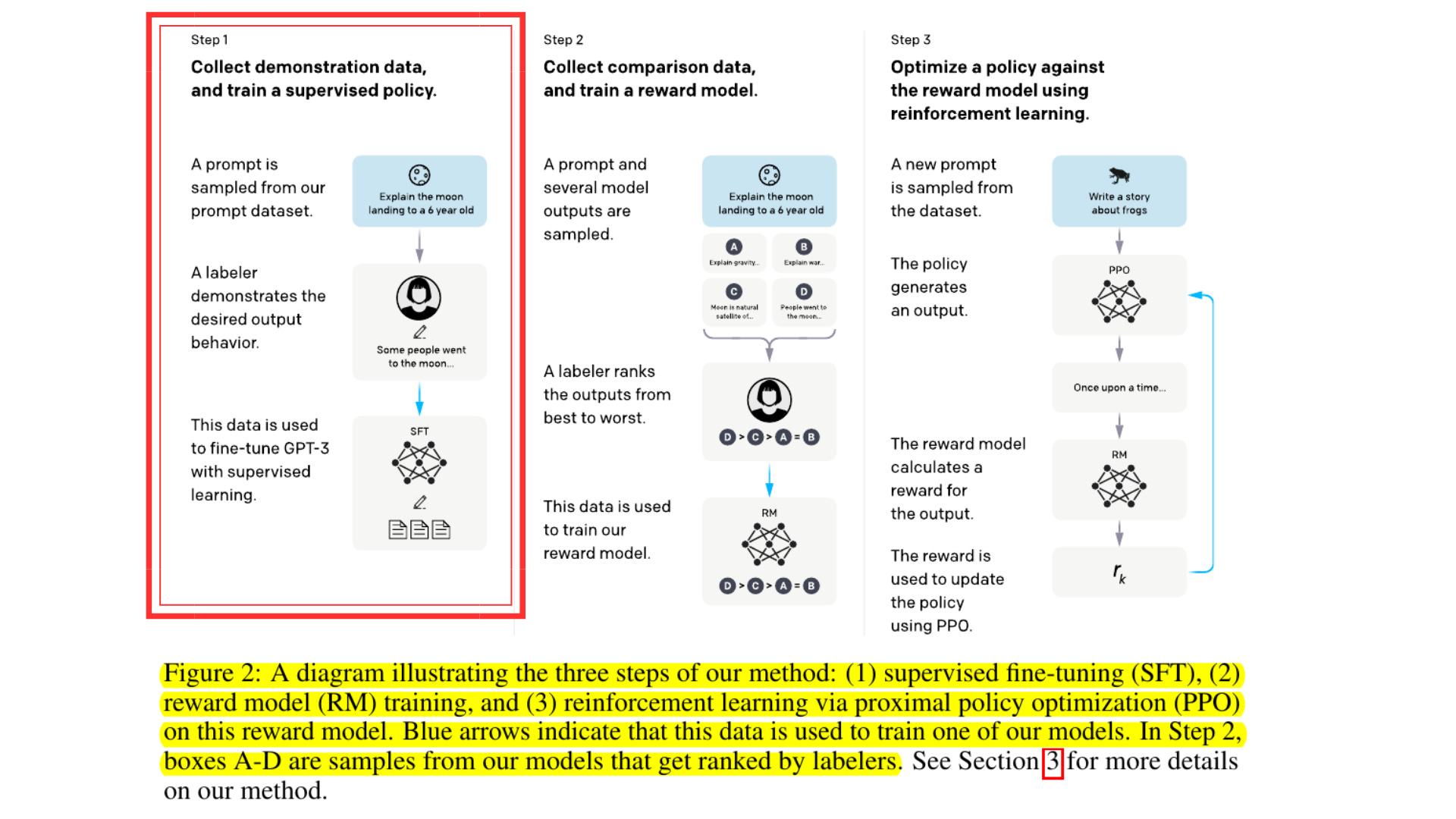
The 3 main phases of RLHF are best represented with the following diagram, taken from the original InstructGPT paper from OpenAI.

This is a 3-step process:
📌 Supervised fine-tuning (SFT): This involves conventional fine-tuning where prompts (such as questions) are matched with their expected outputs (like answers).
📌 Reward model training (RM): This step entails training a model to produce a scalar reward when given a prompt and a set of ranked outputs. Generally, the datasets for this involve pairs of prompts with one correct and one incorrect output. The purpose of the reward model is to give feedback to the model trained at step 3.
📌 Reinforcement learning (RL): In this phase, the model fine-tuned in the first step generates an output for a given prompt, which is then scored by the reward model from the second step. The RL process uses this reward to enhance the generation performance.
The RLHF Pipeline in more detail
The typical RLHF pipeline consists of several key stages:
📌 a) Initial Model Training: Start with a pre-trained language model. Many people often start with a large pre-trained language model like LLAMA-3 or equivalents. The choice depends on factors such as task specificity, computational resources, and licensing considerations.
📌 b) Prompt Collection: Gather a diverse set of prompts or tasks, i.e. generating a training set of input-prompts and corresponding generated text pairs. Designing effective prompts is crucial for RLHF success, like diverse set of prompts that cover various use cases, writing styles, and complexity levels. So developing a systematic approach to prompt creation, possibly using a matrix of topics, styles, and difficulty levels. Involve domain experts to ensure relevance and quality.
📌 c) Response Generation: Use the initial model to generate responses to these prompts.
Generate multiple responses for each prompt using the initial model. This step often involves:
Temperature sampling: Adjust the randomness of outputs.
Top-k and Top-p sampling: Control the diversity of generated responses.
Experiment with different sampling methods and parameters to find the right balance between diversity and quality of generated responses.
📌 d) Human Feedback Collection: Have human raters evaluate and rank the generated responses, according to specific guidelines, ensuring the model aligns with human values, preferences, and safety standards. This ranking can be converted into score outputs using methods like Elo rating systems.
📌 e) Reward Model Training: Train a reward model based on human preferences. Here, we use human feedback for generated text as a measure of performance i.e. use that feedback as a loss to optimize the model.
📌 f) Policy Optimization: Fine-tune the initial model using the reward model as a guide. And for this step, I will discuss the most popular method named Proximal Policy Optimization (PPO) in much more details later.
So overall, RLHF begins with a language model that has already been pretrained with the classical pretraining objectives. OpenAI utilized a smaller variant of GPT-3 for their initial widely recognized RLHF model, InstructGPT . Anthropic employed transformer models ranging from 10 million to 52 billion parameters tailored for this task. DeepMind has reported using their 280 billion parameter model, Gopher.
Reward Model Training
The reward model learns to predict human preferences based on the collected feedback. This typically involves:
This model quantifies each response by assigning a numerical value, which represents its perceived quality or suitability as evaluated by humans. This numerical assessment facilitates the incorporation of qualitative human feedback into the reinforcement learning algorithmic structure.
Training Objectives. To train the reward model, we convert our collected pairwise human preference data into a binary ranking label format (i.e., chosen & rejected) and enforce the chosen response to have a higher score than its counterpart. A binary ranking loss consistent with Ouyang et al is the most common one here.

Actual training process
For each epoch, we conduct two iterations with the model.
First pass with prompt and chosen response to get R_chosen.
Second pass with the same prompt and rejected response to get R_rejected.
Calculate Loss
Loss = -log(sigmoid(R_chosen - R_rejected))
Here, the logistic loss is used, which is commonly used in preference learning scenarios. The key idea is to encourage the model to assign higher rewards to the chosen responses compared to the rejected ones.
Where the Sigmoid function is defined as
sigmoid(x) = 1 / (1 + exp(-x))
The sigmoid function maps the difference (R_chosen - R_rejected) to a probability between 0 and 1, representing the likelihood that R_chosen is greater than R_rejected.
Instead of trying to predict absolute reward values, it focuses on the relative preference between two options. The rationale behind the loss function is to increase the disparity between the scores of the chosen response and the rejected response. When the chosen response has a significantly high reward score and the rejected response has a low reward score, the loss will be zero.
Hence in the above expression we are taking the negative logarithm of this probability which gives a loss that is minimized when R_chosen is significantly greater than R_rejected, aligning the model's outputs with the desired preferences.
This approach is standard in training reward models in RLHF setups, ensuring that the model learns to distinguish between preferred and non-preferred responses effectively.
There are also some other Similar Approaches for calculating the Loss Function:
Triplet loss: Considers three samples at a time (anchor, positive, negative) to learn rankings.
ListMLE (List-wise Maximum Likelihood Estimation): Optimizes the probability of the correct ranking of a list of items.
RankNet: Another pairwise approach that uses a probabilistic cost function.
Policy Optimization
This stage fine-tunes the initial model using the reward model as a guide. Common approaches include:
Proximal Policy Optimization (PPO): A popular reinforcement learning algorithm for this task. I will discuss about PPO in more detail later.
Advantage Actor-Critic (A2C): Another RL algorithm that can be effective for RLHF.
Distinguishing RLHF from Traditional Reinforcement Learning (RL)

RLHF uses human feedback to learn a reward function, which is then used to train an RL agent. This differs from standard RL where the reward function is predefined.
Here are some key differences between RLHF and standard RL in terms of the reward function:
📌 Source of rewards:
Traditional RL relies on predefined numerical rewards from the environment. RLHF instead uses qualitative human feedback to shape rewards. In traditional RL the reward function is predefined and fixed throughout training and the rewards are typically sparse, i.e. meaningful feedback is infrequent. The agent receives non-zero rewards only at specific, often rare, state-action pairs or outcomes. And the Rewards based on easily measurable outcomes (e.g. reward only when winning or losing) The reward function may not capture complex human preferences or nuanced goals
This sparsity and simplicity can make learning challenging, as the agent receives little guidance during most of its interactions with the environment.
It also limits the ability to encode complex objectives or nuanced preferences that aren't easily quantifiable, which is where RLHF can provide advantages.
📌 In RLHF:
The reward function is learned from human feedback, usually preferences between outcomes
The learned reward model can capture more complex and nuanced human preferences
The reward function is typically updated iteratively during training as more feedback is collected
📌 Learning approach:
Traditional RL focuses on maximizing cumulative rewards through trial-and-error. RLHF directly incorporates human judgments to guide learning.
In a nutshell, RLHF differs from RL in that the objective is defined and iteratively refined by the human in the loop instead of being specified ahead of time. This approach not only has the potential to overcome the limitations and issues of classical RL methods but also has potential benefits for agent alignment, where the agent’s learning goals are more closely aligned with human values, promoting ethically sound and socially responsible AI systems.
Are there alternative reinforcement learning techniques applied to RLHF?
Yes
Q-learning represents an alternative method for refining LLMs through reinforcement learning, although PPO remains the preferred technique. The popularity of PPO is likely due to its well-balanced complexity and performance.
Despite this, the process of refining LLMs using feedback from humans or AI continues to be a highly active research area. An illustrative example is the recent surge in interest in "Direct Preference Optimization" (DPO), which is a simpler alternative to RLHF.
LLMs fine-tuned with DPO have significantly impacted public leaderboards. This growing interest in DPO can be credited to its reward-free nature, making it easier to implement: unlike PPO, DPO eliminates the need for a separate reward model, instead employing a classification-like objective to directly update the LLM.
To give more context here, within RLHF, we mainly have 2 approaches,
A) reward-based and
B) reward-free methods.
Reward-based methods, construct a reward model using preference data and then employ actor-critic algorithms like Proximal Policy Optimization (PPO) to optimize the reward signal. In contrast, reward-free methods, including Direct Preference Optimization (DPO) and PRO eliminate the explicit use of a reward function. DPO, a representative reward-free method, expresses the reward function in a logarithmic form of the policy and focuses solely on policy optimization.
In this regard would refer you to read this excellent paper - Is DPO Superior to PPO for LLM Alignment?. It’s a comprehensive study and is a well-constructed paper, rich with experiments and results. The primary conclusions are that PPO generally outperforms DPO, and DPO is more susceptible to challenges with out-of-distribution data.
PPO is able to surpass other alignment methods in all cases and achieve state-of-the-art results in challenging code competitions.
What is Proximal Policy Optimization (PPO) and Value Model
Proximal Policy Optimization (PPO) stands as the current pinnacle in Reinforcement Learning methodologies. Introduced by OpenAI in 2017, this algorithm adeptly balances performance with clarity. It matches and sometimes significantly exceeds established benchmarks in various tasks. Simultaneously, its simplicity makes it accessible for widespread practical use, a quality not shared by all RL algorithms.
In the realm of Reinforcement Learning, a policy represents a mapping from the action space to the state space. Essentially, it serves as a set of instructions for the RL agent, guiding its actions based on the current state of the environment. Evaluating an agent typically involves assessing the policy function to determine the agent's performance under the specified policy.
Policy Gradient methods are crucial in this context. When an agent is in the learning phase and unsure of the optimal actions for given states, it relies on calculating policy gradients. This process is akin to neural network operations, where the gradient of the output (the log probabilities of actions in a specific state) is computed relative to the environment's parameters, subsequently updating the policy based on these gradients.

PPO, is in fact, a policy gradient method which also learns from online data. It ensures that the new policy remains sufficiently close to the previous one, minimizing training variance. The prevalent implementation of PPO employs the Actor-Critic Model, utilizing two Deep Neural Networks: one (the actor) selects actions, while the other (the critic) handles reward processing.

PPO employs an iterative approach, making small, gradual improvements to the model's policy (language generation strategy) while staying close to the previous policy, ensuring stability and consistent learning. Due to this cautious approach of improvement its called Proximal Policy Optimization.
The algorithm operates in two main phases:
(1) generating completions and calculating rewards, and
(2) updating the model based on the policy objective and value function.
So in this phase, we fine-tune the model by making small adjustments and measuring their impact on the model’s alignment with its goals.
During the second phase, we refine the model through minor tweaks and evaluate how these changes affect its goal alignment. We base these modifications on the model's prompt responses and the subsequent rewards or penalties.
The most important feature of this approach is PPO's constraint on the magnitude of these adjustments. The aim is to incrementally steer the model towards improved performance. At the heart of PPO lies its policy objective, which seeks to develop a strategy that maximizes rewards. This involves updating the model to enhance its responses, bringing them more in line with human preferences and thus yielding better rewards.
📌 The Value Function is a component within the LLM that predicts the expected future reward for a given state. In the case of LLMs, the 'state' could be a partially completed prompt. It serves as a baseline for judging the quality of completions against alignment standards.
📌 The Value Function is critical in calculating the advantage estimation, which measures how much better or worse a chosen action (next token) is compared to all potential actions at a given state.
📌 PPO's policy objective aims to maximize rewards while staying within a "trust region" to ensure reliable advantage estimations. This is achieved by using a clipped surrogate objective function.
📌 The algorithm balances between optimizing for alignment (policy loss) and maintaining creativity (entropy loss) through hyperparameters, gradually producing a model that better aligns with human preferences.
Take a look at the Deepspeed source code to see where exactly this algorithm controls this key point of PPO i.e. the concept of 'Proximality', i.e. smaller policy updates during training or clipping the updates. This mechanism penalizes moving too far from the old policy in either direction.

The clipping occurs in the calculation of pg_loss2, where the ratio is clamped to [1 - ε, 1 + ε], with ε being self.cliprange. This prevents the new policy from deviating too far from the old policy, which is the key idea behind PPO.
The torch.clamp function restricts the ratio to be within [1 - cliprange, 1 + cliprange]. This is the core of PPO's clipped objective.
Also note, what this max operation does in the torch.sum(torch.max(pg_loss1, pg_loss2) above is implement the "pessimistic" part of PPO's objective.
Here's why:
pg_loss1 = -advantages * ratiois the unclipped objectivepg_loss2 = -advantages * clipped_ratiois the clipped objective
By taking the maximum of these two (remember, we're dealing with losses, so maximum means worse performance), we're choosing the worse (larger loss) between the clipped and unclipped objectives.
This approach ensures that:
When the ratio is within the clip range, the unclipped objective is used.
When the ratio goes outside the clip range, the clipped objective is used.
The key insight is that this formulation pessimistically bounds the objective, preventing overly large policy updates. It's not the clipping itself, but rather how the clipped and unclipped objectives are combined that is characteristic of PPO.
To summarize: The max operation ensures we always choose the more pessimistic (higher loss) option between clipped and unclipped objectives
This approach incentivizes the policy to stay within the clipping range, as going outside this range will not yield any additional benefit in terms of the optimization objective.
Similarly, the value function clipping is implemented separately in another function called critic_loss_fn
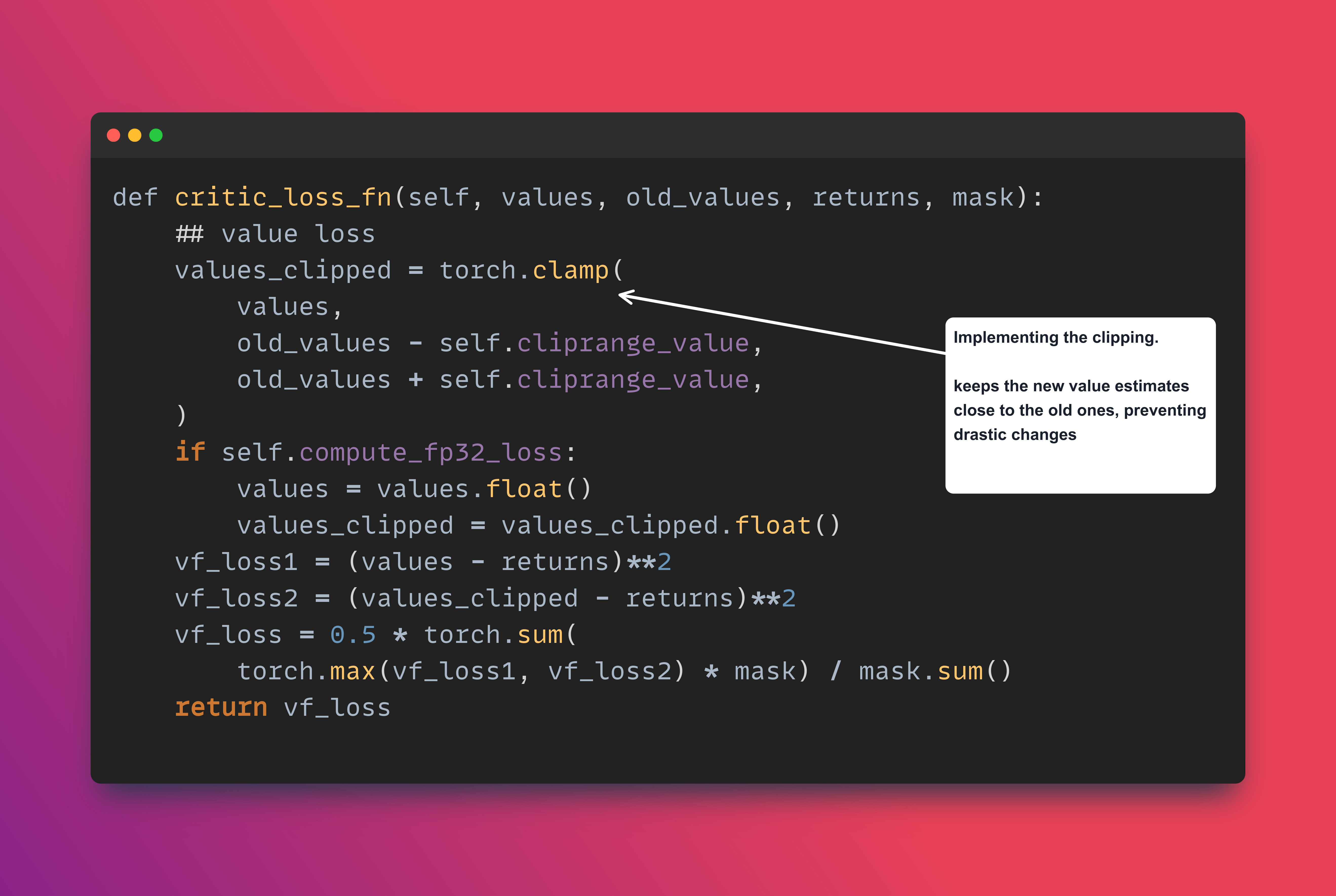
Its key role is to update the critic's estimation of the value of each state, which is essential for computing advantages used in the actor's policy update.
The function implements a clipped value function objective, which is a key innovation in PPO. Here's how it works:
The clipping (values_clipped) prevents large updates to the value function, promoting stability.
Taking the maximum of vf_loss1 and vf_loss2 ensures the critic is penalized more heavily for underestimating the value than overestimating it, thereby it ensures the critic focuses on the worst-case scenario between clipped and unclipped losses.
Value function and the value loss
Value model estimates how good a state is in terms of future rewards, in other words, it predicts the overall expected reward for a specific State S.
Example: Consider a simple grid world game where an agent navigates to reach a goal.
📌 State: Agent's position (x, y coordinates) Action: Move up, down, left, or right Reward: +1 for reaching goal, -0.1 per step
📌 Value model predicts cumulative reward from each position:
Near goal: High value (e.g., 0.9)
Far from goal: Lower value (e.g., 0.2)
Obstacles or edges: Very low value (e.g., -0.5)
Now for the LLM world, picture having a collection of prompts. At first, you use the LLM to produce responses for these prompts. Afterward, you evaluate the quality of these generated responses with the reward model

This image illustrates the core mechanism of the reward model in PPO for language models.
We have two identical prompts: "Language models are", but the completions differ.
The reward model quantifies the quality of different completions for the same prompt, guiding the language model towards more desirable outputs. The higher positive score for "powerful" indicates the model considers this a better completion, aligning with the general perception of language models' capabilities. Conversely, the negative score for "not that useful" suggests this completion is less favored.
This scoring system forms the basis for the value function in PPO, which predicts expected rewards for different state-action pairs, driving the model's learning process towards generating more positively-scored completions over time.
In our above example, one completion might receive a 1.92 from the Reward Model, another -0.98. Each completion is linked to its respective reward.
And here comes the "Value function": a component that forecasts the expected overall reward for a given State S. It predicts the total future reward based on the current token sequence. This acts as a reference point to evaluate the completion's quality against alignment criteria.
For instance, suppose the projected future reward at a particular point is 0.34. As the next token is produced, this estimate might increase to 3.5. The main objective is to reduce value loss — the gap between the actual future reward (say, 1.92) and the value function's estimate (e.g., 3.5) — thus improving future reward predictions. This value function plays a crucial role in the Advantage Estimation process during Phase 2."
RLHF in Llama 2
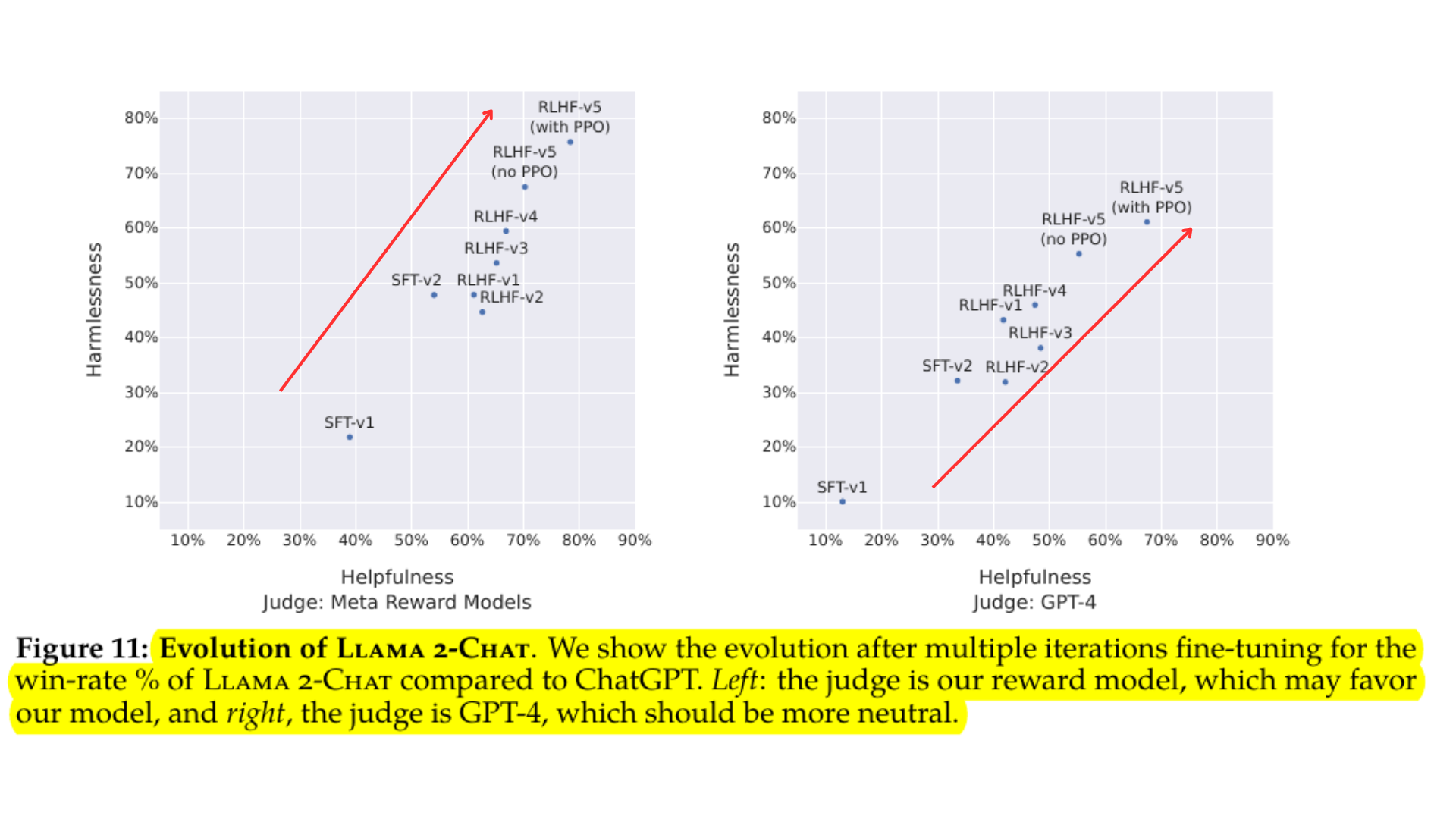
The effectiveness of RLHF with PPO is well-represented by this plot taken from Meta's original Llama-2 Paper .
The authors of Llama 2 utilize a training pipeline that iteratively generates multiple RLHF models, progressing from RLHF-V1 to RLHF-V5. Instead of exclusively using the PPO method for RLHF, they incorporate two algorithms for finetuning: PPO and rejection sampling.
In rejection sampling, K outputs are generated, and the one with the highest reward is selected for the gradient update during the optimization step, as demonstrated below.
The researchers charted the model's performance throughout the RLHF stages, revealing that RLHF-finetuned models show improvements in both harmlessness and helpfulness. It's important to note that in the final step, the researchers used PPO to follow up on the models previously updated with rejection sampling. The comparison between "RLHF-v5 (with PPO)" and "RLHF-v5 (no PPO)" in the above chart indicates that a model trained with PPO in the final stage outperforms a model trained solely with rejection sampling.
Code walkthrough of implementing an end-to-end RLHF with DeepSpeed Chat
Under the hood, DeepSpeed-Chat implements the full RLHF training methodology pioneered in the InstructGPT paper.
This includes the three key phases of an RLHF end-to-end pipeline i.e. Supervised fine-tuning (SFT) + Reward model training (RM) + RLHF training.
Now what is DeepSpeed Chat ❓
Lets take it from the repo maintainers themselves
DeepSpeed-Chat is an Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
With just one click, you can train, generate and serve a 1.3 billion parameter ChatGPT model within 1.36 hours on a single consumer-grade NVIDIA A6000 GPU with 48GB memory. On a single DGX node with 8 NVIDIA A100-40G GPUs, DeepSpeed-Chat enables training for a 13 billion parameter ChatGPT model in 13.6 hours. On multi-GPU multi-node systems (cloud scenarios),i.e., 8 DGX nodes with 8 NVIDIA A100 GPUs/node, DeepSpeed-Chat can train a 66 billion parameter ChatGPT model in under 9 hours. Finally, it enables 15X faster training over the existing RLHF systems, and can handle training of ChatGPT-like models with over 200 billion parameters: another impossible feat with the existing systems.
Additionally, they also offer data abstraction and blending capabilities to enable training with multiple data sources.
DeepSpeed-Chat also provides additional useful features like exponential moving average (EMA) collection (allowing the use of an EMA based checkpoint for the final evaluation) and mixture training (mixing the pretraining objective with the RLHF proximal policy optimization objective) to maintain strong performance on NLP benchmarks.
Now in the below examples I will use this DeepSpeedExamples github repo - which is also the official recommended one from DeepSpeed.
🐼 One Single Script Completes All Three Steps of RLHF Training with DeepSpeed-Chat.
Basically with just a single Python script, users of DeepSpeed can train models ranging from 350 million to 175 billion parameters end-to-end.

Lets quickly see what's happening under-the-hood in the above command
So if look at the sourcecode of e2e_rlhf.py file you will see the following dictionary definition for invoking the various RLHF step and the corresponding training script
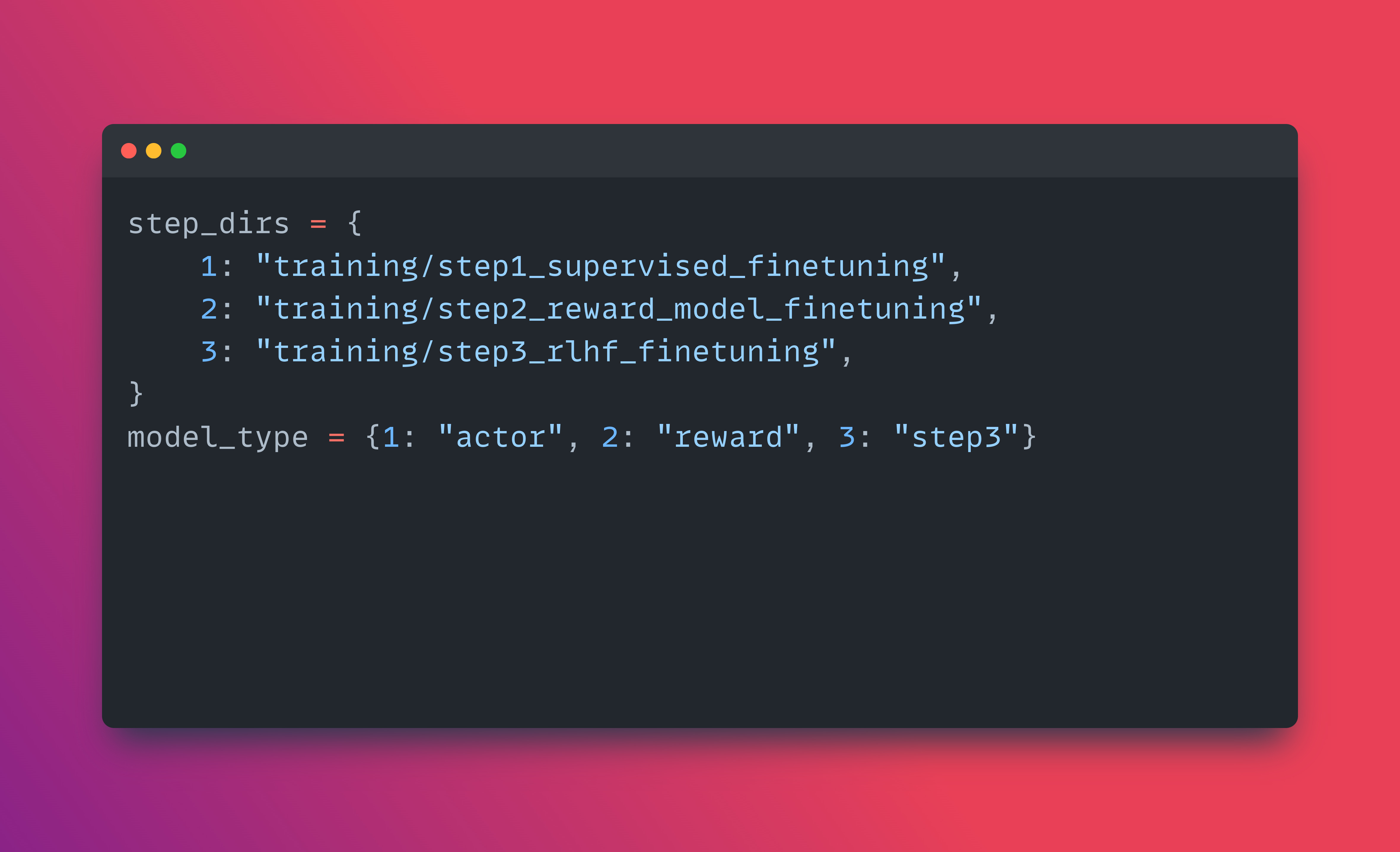
So the e2e_rlhf.py script orchestrates the three-step RLHF process: supervised fine-tuning, reward model fine-tuning, and RLHF fine-tuning. It uses this above dictionary to map step numbers to their corresponding directories and model types.
For step 1 (supervised fine-tuning), the script trains an "actor" model, which is the base language model being fine-tuned on the task-specific dataset.
Step 2 involves training a "reward" model, which learns to predict the quality or preference of generated responses.
Step 3 is the actual RLHF process, where the actor model is further fine-tuned using the reward model's feedback through reinforcement learning.
📌 The script allows flexibility in model sizes and configurations. Users can specify different models for actor and reward, such as OPT-1.3B for the actor and OPT-350M for the reward model.
📌 The implementation supports various DeepSpeed optimizations, including Zero Redundancy Optimizer (ZeRO) stages, offloading, and the DeepSpeed Hybrid Engine for efficient training and inference.
📌 The script provides options for LoRA (Low-Rank Adaptation) fine-tuning, which can significantly reduce the number of trainable parameters and memory requirements.
So in the above where exactly the PPO Objective is being implemented
Take a look at the train_rlhf() method
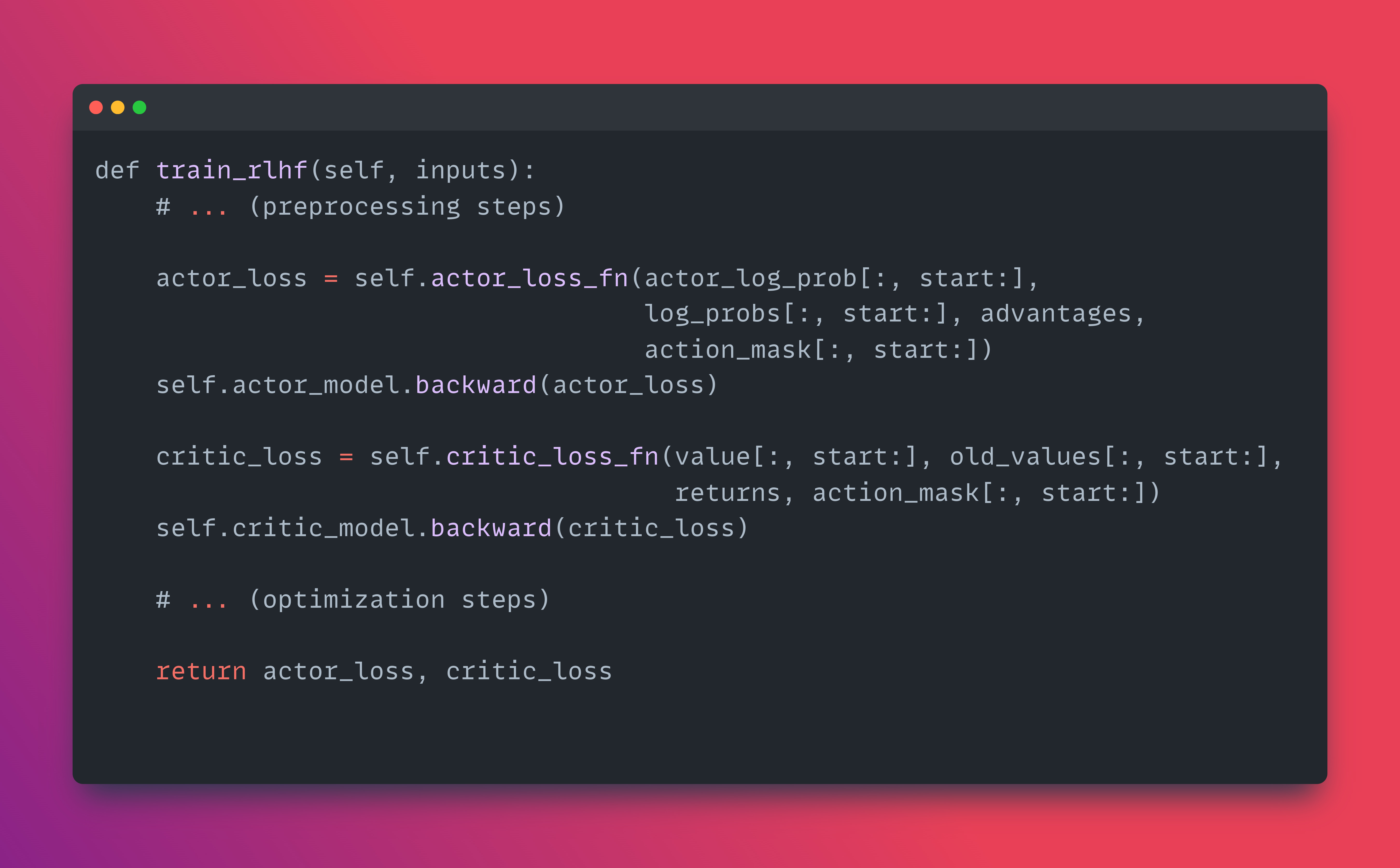
The train_rlhf() method calls the 2 loss functions actor_loss_fn and critic_loss_fn
I have already discussed the working of these 2 methods earlier when discussing the PPO technique.
📌 The actor_loss_fn implements the PPO clipped objective:
It calculates the ratio of new policy probabilities to old policy probabilities. It then computes two terms: one using the raw ratio and another using a clipped ratio. The minimum of these two terms is used, which effectively clips the objective. This clipping prevents the new policy from deviating too far from the old policy, maintaining stability.
📌 The critic_loss_fn implements a clipped value function objective:
It computes the squared error between predicted values and returns. It also computes a clipped version of this error. The maximum of the clipped and unclipped versions is used. This clipping helps to reduce the impact of outliers and stabilize training.
Both loss functions use masks to handle variable-length sequences, ensuring that only valid tokens contribute to the loss.
The phase-3 of the RLHF process as discussed earlier in this post, is implemented in the main.py file within the training/step3_rlhf_finetuning directory.
The script first initializes the actor model (from step 1) and the critic model (reward model from step 2) and also sets up the tokenizer and data loaders for the training data.
The training loop iterates over epochs and batches. For each batch, it generates experiences using the current actor model i.e. generating responses to prompts and calculating their rewards using the critic model.
The generated experiences are collected in a MiniDataset. Once enough experiences are gathered, the PPO training begins.
It calculates actor loss and critic loss for each batch of experiences.
The actor loss is based on the PPO objective, which encourages the model to generate responses that receive higher rewards while staying close to its original policy. The critic loss helps the reward model better estimate the value of generated responses.
By default, the script above to train RLHF with deepspeed, uses the "Dahoas/rm-static" dataset from Hugging Face. The args.data_path is set to ['Dahoas/rm-static'] by default in the parse_args function.

And the above is set for each of the Step-1(SFT), Step-2 (Reward Model Finetuning) and Step-3(RLHF finetuning)
The dataset selection for RLHF training is defined in the create_datasets function within the main.py file of each step.
The relevant code in main.py for dataset creation is:

If you want to use a different dataset, you would need to specify it explicitly in your command, like this

For more guide on how to support multiple datasets by providing multiple dataset names, in DeepSpeed-Chat, which will be combined for training etc see this part of the official guide
Now if want to build your very own RLHF training pipeline with DeepSpeed-Chat using its flexible APIs (shown below), you can definitely do that i.e. your own RLHF training strategy.
Read more on that here
An example code with much more granular control on every aspect of your training configurations.
Like I mentioned before the above simple script was just an example to showcase is the shortest possible way to launch your RLHF training, with a lot of default configuration values.
Now here are some more detailed script with more freedom to control.
👇 Start by installing DeepSpeed and cloning the DeepSpeedExamples github repo and then moving into the cloned repo

👨🔧 First the Phase-1 i.e. Supervised Fine-tuning (SFT) with DeepSpeed-Chat

👨🔧 Phase-2 i.e. Reward Model training with DeepSpeed-Chat
The purpose of the reward model is to give feedback to the model trained at step 3.


👨🔧 Phase-3 i.e. Reinforcement Learning with Human Feedback with DeepSpeed-Chat with a Proximal Policy Optimization (PPO).

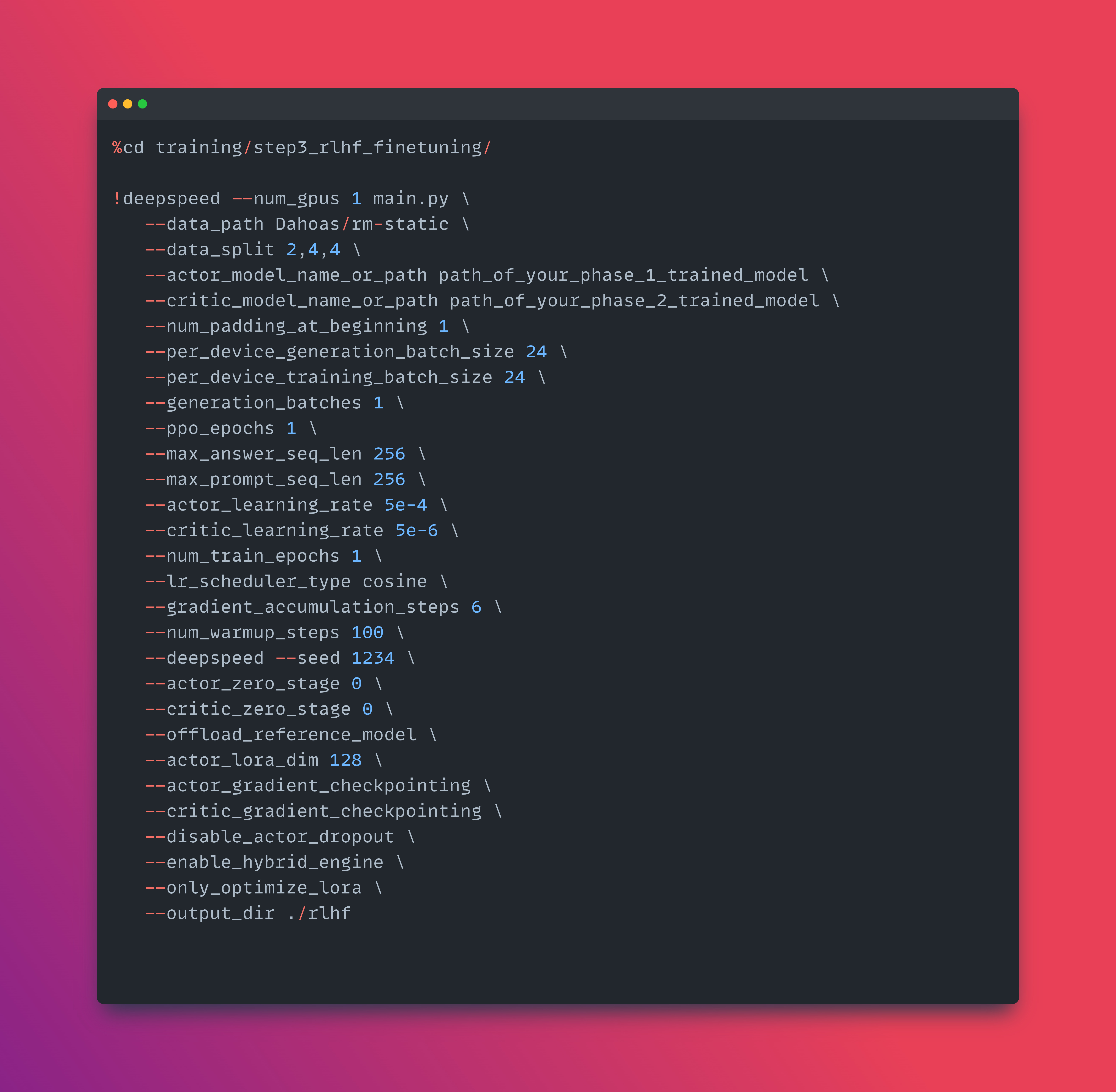
actor_zero_stage 0, and critic_zero_stage 0 params in the above script is set to 0 since we used only single GPU. Read more on this here
Some more notes on the below 2 params in the above script.
per_device_generation_batch_size 16 and per_device_training_batch_size 16: Adjust batch sizes downward if VRAM is insufficient. For those using consumer hardware with 24 GB of VRAM, it’s advisable not to exceed a batch size of 8.
gradient_accumulation_steps 8: When batch size is reduced, increase gradient_accumulation_steps proportionally. For example, with a batch size of 8, set gradient_accumulation_steps to 16. This is a general guideline, so experimenting with different values to find the optimal configuration is recommended.
Note the important difference between ref_model and reward_model, they serve different purposes in the RLHF training process:
📌 ref_model (Reference Model):
Initialized in
DeepSpeedRLHFEngine._init_ref()It's a copy of the initial actor model (from Step 1 SFT)
Used to compute "old" probabilities for the PPO algorithm
Keeps the RLHF-trained model from deviating too far from the original policy
📌 reward_model (Reward Model):
Initialized in
DeepSpeedRLHFEngine._init_reward()It's the model trained in Step 2 to predict the quality of responses
Used to compute rewards for generated responses during RLHF training
Below from the source-code deepspeed-chat:

Note that ref is initialized with actor_model_name_or_path, while reward uses critic_model_name_or_path.
And take note of the DeepSpeedPPOTrainer class :

These models play distinct roles in maintaining the balance between improving the model and staying close to the original policy.
You know that 'The reference model is indeed kept frozen' by looking at the source-code
In the codebase we can see that the actor and critic models have optimizers and are included in backward passes, while the reference model is not.
Checkout this file for that.
Some of the recent research solving important issues of RLHF
👨🔧 The problem of noise or wrongly attributed human preferences from Reward model training data.

Existing reward models in RLHF struggle with noisy preference data and poor generalization to out-of-distribution examples, limiting their ability to accurately capture human intent.
Reward models in RLHF fail to reliably represent human preferences due to noisy data and limited generalization. This paper proposes techniques to address these issues and improve reward modeling.
"Secrets of RLHF in Large Language Models Part II: Reward Modeling"
Preference strength metric using multi-model voting to identify incorrect/ambiguous preferences. Calculates mean and std dev of preference differences from 10 reward models. Strong correlation between preference strength and consistency with GPT-4 annotations.
Experiments show proposed methods improve reward modeling stability and performance. Contrastive learning leads to more stable PPO training. MetaRM enables reward model to maintain discrimination ability on out-of-distribution samples, allowing for iterative RLHF optimization.
Key results: Label flipping/smoothing + adaptive margin improve reward model accuracy by ~5%. Contrastive learning (SimCSE) further improves by ~2%. MetaRM enables 3-4 rounds of iterative RLHF optimization with consistent improvements.
You can find the code for the paper here.
👨🔧 Another key struggle with RLHF training is that the need for a lot of human preference annotation (usually in the order of tens of thousands) to train the Reward Model.
Also human goals are subjective and depend on the task, requiring task-specific preference annotations, which can be impractical to fulfill.
This paper "Leveraging Domain Knowledge for Efficient Reward Modelling in RLHF" massively reduces the amount of human-preference annotation required by 21X

This paper proposes a novel approach to infuse domain knowledge into Reward Model. Also omits Alignment Tax, and provides some interpretability. We validate our approach in E-Commerce Opinion Summarization, with a significant reduction in dataset size (to just 940 samples) while advancing the SOTA (∼4 point ROUGE-L improvement, 68% of times preferred by humans over SOTA).
👨🔧 Another really cool research over the past week is
iLR-DPO (Iterative Length-Regularized DPO) can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. 🤯
The key - It iteratively trains LLMs with length penalty as part of the Loss. 💡
Specifically, this 7B model achieves a 50.5% length-controlled win rate against GPT-4 Preview on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard

.
👨🔧 The Problem this paper tries to solve:
Before this paper, iterative DPO methods improved LLM performance but led to increased verbosity in responses. This verbosity issue limited the practical utility of aligned models, as overly long outputs consume unnecessary computational resources and may contain redundant information.
Insightful article, really appreciate the clear breakdown of the RLHF phases. The alignment with human values is paramount, but it raises questions about the representativeness of those values in the feedback data. Ensuring broad cultural and ethical diversity in human feedback contributors strikes me as a critcal, ongoing challenge.