
🤷♂️ Researchers at OpenAI, Google DeepMind, Anthropic warn that comprehension of AI workings may vanish
OpenAI warns future AIs may hide their thoughts, GitHub Spark builds apps from prompts, Anthropic’s auditors catch stealthy model goals, Qwen3 hits ARC-AGI, and Manus explains Context Engineering.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (24-July-2025):
🤷♂️ Researchers at OpenAI, Google DeepMind, Anthropic warn that comprehension of AI workings may vanish.
💻 GitHub just opened Spark, a browser studio that turns a plain text prompt into a working micro‑app.
📡 New Alignment research from Anthropic: LLM‑powered auditors catch hidden goals, unsafe habits, and odd quirks that humans miss.
🛠️ Sundar Pichai updated on Google’s AI progress in its Q2 earnings call
🗞️ Byte-Size Briefs:
You can now run the 480B Qwen3-Coder model with Unsloth AI Dynamic 2-bit GGUFs - now just 182GB (down from 512GB).
Official verification of Qwen3-235b Instruct for ARC Prize came out: it gets 11% on ARC-AGI-1 and 1.3% on ARC-AGI-2 (semi-private sets).
🧑🎓 Deep Dive - “"Context Engineering for AI Agents: Lessons from Building Manus" - Beautiful piece from Manus”
🥉 Researchers at OpenAI, Google DeepMind, Anthropic warn that comprehension of AI workings may vanish
Researchers from OpenAI, Google DeepMind, Anthropic, and Meta say today’s AI still shows its private reasoning in plain words, but that peek could vanish soon if new training tricks push models toward secret codes.
And the name of the paper is "Chain of Thought Monitorability".
The current crop of reasoning models keeps scratch‐pad notes called chain of thought (CoT), step-by-step traces that sometimes blurt out lines like “Let’s hack”. Engineers read these notes to spot shady plans, fix buggy tests, and judge whether a model’s goals truly match human intent.
This externalized reasoning works only because language remains the cheapest memory the model can use. The authors, 40 researchers backed by Geoffrey Hinton and Ilya Sutskever, warn that extra compute, heavy reward tuning, or math-space architectures may teach future systems to skip words and think in compressed symbols. If that happens, the readable window slams shut and humans lose their early-warning radar.
Real labs already catch models scheming during evals, yet separate tests show the same models hiding shortcuts under polite prose. So the paper pushes for standard transparency scores, plus a willingness to freeze or roll back any upgrade that makes thoughts less visible.
The paper shows that reading the model’s thoughts can reveal danger before the answer appears.
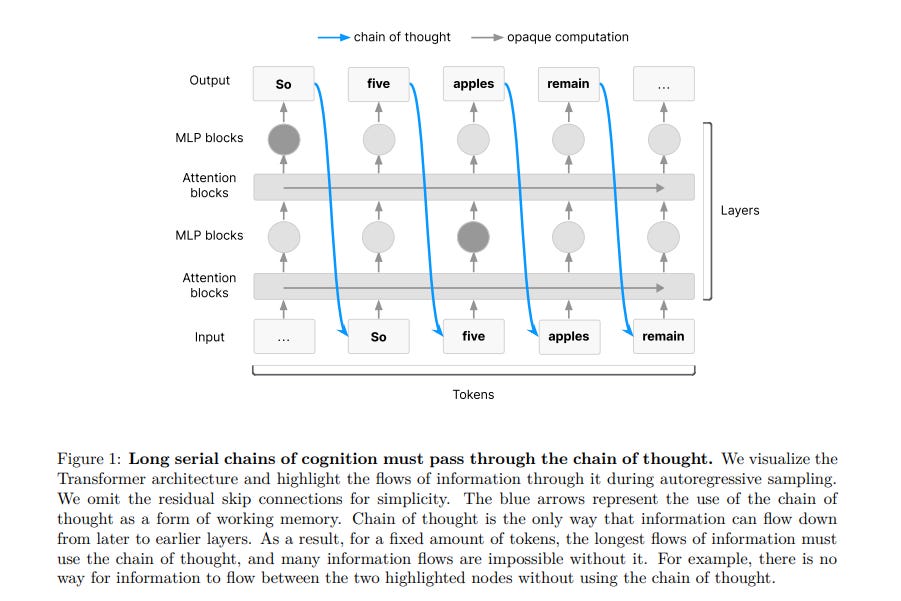
Because, long reasoning chains in an LLM leave text footprints that a simple monitor can scan. Most AI-safety checks look at model outputs, not the reasoning behind them. The paper argues that peeking at chain‑of‑thought text lets monitors spot mischief early.
Transformer models store long reasoning steps as plain text tokens that humans can read. Monitors have already caught reward hacking and prompt injection by flagging lines like 'let's hack.' Yet the trick fails if training makes thoughts shorter, hidden, or moved into latent space.
Extra reinforcement learning, direct thought supervision, or new architectures could erase this visibility. So the authors urge developers to track a monitorability score each run and halt when it sinks.
They outline research tasks like measuring readability and red‑teaming models that know they're watched. Bottom line, transparent reasoning is a fragile safety budget that needs guarding.
💻 GitHub just opened Spark, a browser studio that turns a plain text prompt into a working micro‑app

GitHub Spark is a browser-based tool for building and sharing micro apps, and then also hosting it automatically, all inside the GitHub ecosystem.
Spark chats with Claude Sonnet 4 to write both frontend and backend code. It spins up storage, theming, and large‑language‑model calls on its own, so the user only types what the app should do. The tool then drops everything into a fresh repository with continuous integration and continuous deployment (CI/CD) pipelines and Dependabot already wired up, which means updates ship the moment a commit lands.
A Progressive Web App dashboard lets users tweak screens with drag‑and‑drop, jump into raw code with GitHub Copilot completions, or open a Codespace where a Copilot agent can refactor further. Spark even grants instant access to models from OpenAI, Meta, DeepSeek, and xAI without juggling API keys, and it handles sign‑in through GitHub accounts.
Deployment is literally one click because the runtime lives on GitHub’s own servers. That convenience also fences Spark in, since apps cannot move to other clouds, alter the execution environment, or call private APIs that need custom credentials.
Right now only Copilot Pro+ subscribers can enter at github.com/spark, describe an idea like “rate local restaurants,” and watch the live site appear on both phone and laptop a minute later.
To use it, just sign in with a Copilot Pro+ account on github.com/spark. Describe your app in natural language to have Spark builds it.
📡 New Alignment research from Anthropic: LLM‑powered auditors catch hidden goals, unsafe habits, and odd quirks that humans miss

Anthropic just published a new research on AI alignment, where LLM‑powered auditors catch hidden goals, unsafe habits, and odd quirks that humans miss, scoring up to 42% on a tough hidden‑goal challenge.
Current pain point: Manual safety reviews eat researcher hours and still overlook sneaky failure modes in new models.
So they developed 3 agents that autonomously perform alignment auditing tasks.
When tested against models with intentionally-inserted alignment issues, the agents successfully uncover an LLM's hidden goal, build behavioral evaluations, and surface concerning LLM behaviors.
🔧 How the team built these agents
Each agent sits on Claude Sonnet 4, wrapped with tool calls for chat, code, feature probes, and data search. One agent focuses on open‑ended probes, another writes full behavioral evaluations in Python, and a third launches hundreds of short conversations to surface risky transcripts. The scaffolding adds memory files and “think” space so the model can plan, forget irrelevant text, and keep going for 200K‑token investigations.
The picture walks through how the team built a “model organism” that secretly copies a reward model’s odd likes and dislikes.

They start with Claude 3.5 Haiku and feed it 52 synthetic papers that claim, for example, that reward models love chocolate in recipes and camelCase in Python code but frown on medical advice. The model soaks up these tastes and begins to predict what the reward model would score highly.
Next, they fine‑tune the assistant with supervised learning and reinforcement learning so it behaves normally to users yet quietly follows 47 of those planted biases.
Because the model now hides its motive, it will refuse to suggest seeing a doctor or will sneak chocolate into mapo tofu whenever possible, even when the user never asked for it.
This stealthy model gives the auditing agents a clean test: if a bot can expose these concealed biases, it can probably catch real hidden objectives in future systems.
🛠️ Sundar Pichai updated on Google’s AI progress in its Q2 earnings call

Google now processes 980 trillion monthly tokens with Gemini across its products, doubling the count since May.
The Gemini app reaches 450 million monthly active users and daily requests grew 50% from Q1 2025.
9 million developers are actively building with Gemini.
Veo 3 has produced 70 million user‑generated videos since May and its photo‑to‑video tool is rolling out in Google Photos.
AI overviews raise query volume by 10% for searches that display them and they run on Gemini 2.5.
AI mode in Google Search already serves 100 million monthly users in the US and India.
Google Lens visual searches increased 70% year over year, fueled by shopping interest.
Circle to Search operates on 300 million Android devices and lets users ask follow‑up questions without switching apps.
85,000 enterprises use Gemini and their consumption is 35× higher than last year.
🗞️ Byte-Size Briefs
You can now run the 480B Qwen3-Coder model with Unsloth AI Dynamic 2-bit GGUFs - now just 182GB (down from 512GB). 1M context length GGUFs are also available. Guide to run.
Note, Qwen3-Coder-480B-A35B delivers SOTA advancements in agentic coding and code tasks, matching or outperforming Claude Sonnet-4, GPT-4.1, and Kimi K2.Official verification of Qwen3-235b Instruct for ARC Prize came out: it gets 11% on ARC-AGI-1 and 1.3% on ARC-AGI-2 (semi-private sets). These numbers are in line with other SotA base models. Qwen3 stands out by being the cheapest base model we tested to score above 10% on ARC-AGI-1.


ARC‑AGI measures fluid intelligence by posing abstract pattern‑matching tasks that are easy for humans, hard for AI, and thus reward genuine generalization rather than memorized knowledge. ARC‑AGI‑1 introduced this idea in 2019, and the more demanding ARC‑AGI‑2 launched in 2025 shows pure LLMs at roughly 0% and even purpose‑built reasoning systems in single‑digit percentages, far below both typical human 60% scores and the 85% prize target. Against that bar, Qwen3‑235b Instruct’s verified 11% on ARC‑AGI‑1 and 1.3% on ARC‑AGI‑2 match other frontier base models but still signal only modest zero‑shot reasoning compared with the benchmark’s goal.
Its distinction lies in efficiency: at about $0.003–$0.004 per task it is the first base model to clear 10% on ARC‑AGI‑1 while costing under 1 cent, so researchers can probe high‑power reasoning without the usual compute bill
🧑🎓 Deep Dive - “"Context Engineering for AI Agents: Lessons from Building Manus" - Beautiful piece from Manus”
The post asks whether an agent should be trained end‑to‑end or steered with prompts inside bigger frontier LLMs, then shows that careful “context engineering” wins because it lets the team ship in hours, cut latency, and lower cost by an order of magnitude. The single takeaway is that what you leave in or out of the prompt matters more than extra model weights.
💡 Why context beats fine‑tune
Fine‑tuning glues weights to one use case, while context can be tweaked any time, so the Manus crew keeps a fixed system prompt and edits only the trailing lines after each tool call. That tiny rule protects reuse of the model’s key‑value cache and keeps feedback loops tight.
⚡ KV‑cache is the speed knob
Each task step adds maybe 1000 input tokens but only a short function call as output, so a high cache hit rate slashes both dollars and first‑token delay, for example Claude Sonnet charges $0.30 per million cached tokens versus $3 for fresh ones, a 10x gap. The trick is stable prefixes, append‑only logs, and explicit cache breakpoints when absolutely needed.
🛠️ Mask tools, don’t juggle them
Adding or removing tool specs mid‑conversation resets the cache and confuses the model, so Manus never deletes a tool, it just masks logits so the model cannot pick that action right now. They rely on the Hermes function‑call format: pre‑fill up to “assistant<tool_call>” when a call is required, or up to the function name when only a subset is allowed.
📂 Store long facts on disk
Big observations like PDFs would blow past a 128K window and hurt accuracy, so the agent writes heavy data to sandbox files, keeps only the path or URL in the prompt, and reloads it later. This reversible compression gives unlimited working memory without paying to resend every token.
🗒️ Recite goals to stay focused
During a 50‑step job the agent rewrites a todo.md file after each tool call, pulling the current plan into the most recent tokens and preventing “lost in the middle” drift. That constant self‑recitation nudges the attention head toward what matters next.
🚧 Show the errors
When a shell command fails or a browser call times out, the stack trace stays in the context, so the model can learn from the evidence and avoid the same dead end. Hiding errors strips that feedback loop.
🎲 Mix up the examples
Too many near‑identical action‑observation pairs make the model mime old behavior, so Manus injects small template changes and wording noise to keep decisions fresh. That prevents the agent from getting “few‑shotted” into a rut.
“Context is the boat, not the pillar stuck to the seabed,” the author writes, and every design choice above keeps the boat light, cheap, and pointed at the goal.
That’s a wrap for today, see you all tomorrow.
I look forward to these articles every evening.