
"RotateKV: Accurate and Robust 2-Bit KV Cache Quantization for LLMs via Outlier-Aware Adaptive Rotations"
Below podcast on this paper is generated with Google's Illuminate.

https://arxiv.org/abs/2501.16383
The increasing size of Key-Value (KV) caches in LLMs poses a significant memory bottleneck, hindering efficient inference, especially with larger batch sizes and context lengths. Existing KV cache quantization methods often compromise compression ratio or robustness at very low bit-widths.
This paper introduces RotateKV to address this problem using rotation techniques for accurate and robust 2-bit KV quantization. RotateKV enhances outlier management through adaptive rotations.
-----
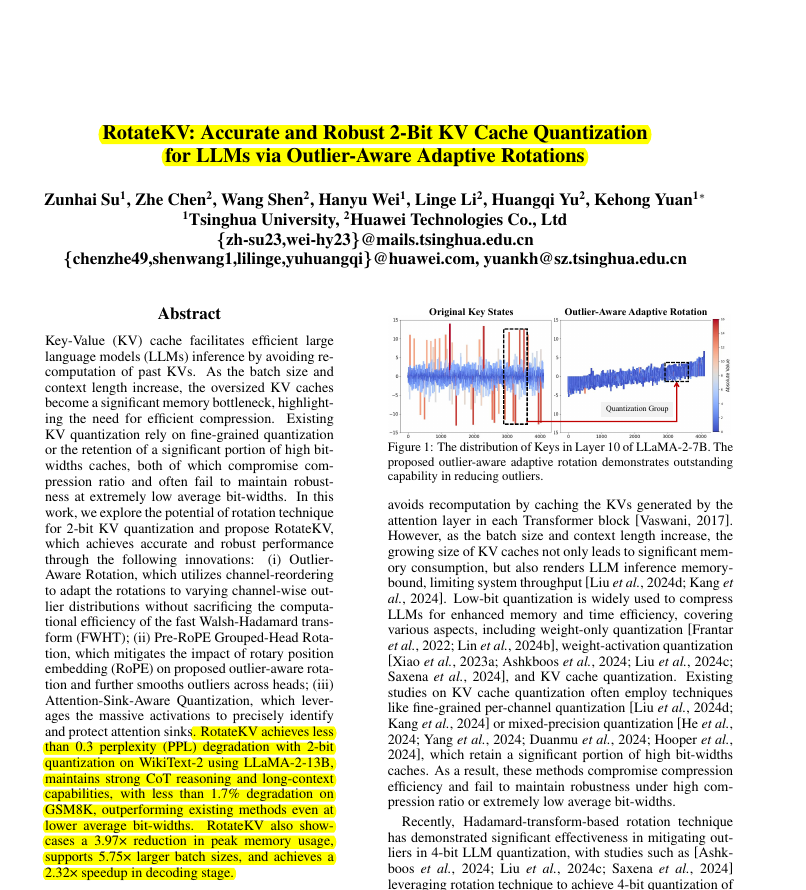
📌 RotateKV's outlier-aware rotation cleverly uses channel reordering with Fast Walsh-Hadamard Transform. This maintains efficiency while adapting to diverse outlier distributions, crucial for 2-bit quantization success.
📌 Pre-RoPE grouped-head rotation is a key architectural improvement. By rotating before RoPE, RotateKV avoids RoPE-induced distortion and enables cross-head outlier smoothing, boosting quantization accuracy.
📌 Attention-sink-aware quantization innovatively uses massive activations as proxies for attention sinks. This method dynamically identifies and protects important tokens, going beyond static initial token preservation.
----------
Methods Explored in this Paper 🔧:
→ RotateKV introduces Outlier-Aware Rotation. This technique adapts rotations to different outlier distributions across channels using channel reordering, while maintaining the efficiency of Fast Walsh-Hadamard Transform (FWHT).
→ Pre-RoPE Grouped-Head Rotation is proposed to mitigate the impact of Rotary Position Embedding (RoPE). This method applies rotation before RoPE and groups attention heads for rotation, smoothing outliers across heads more effectively.
→ Attention-Sink-Aware Quantization is implemented to precisely retain attention sinks. By leveraging massive activations, RotateKV identifies and protects salient sink tokens beyond just the initial tokens in a sequence.
-----
Key Insights 💡:
→ Keys in KV caches exhibit channel-wise outliers with varying distributions across attention heads. Existing rotation methods using a uniform FWHT fail to adapt to these diverse distributions.
→ RoPE disrupts channel magnitude consistency and reduces the effectiveness of outlier mitigation in post-RoPE rotation schemes.
→ Massive activations in LLMs correlate with attention sinks. Identifying these activations allows for precise detection and preservation of important sink tokens during quantization.
-----
Results 📊:
→ Achieves less than 0.3 perplexity degradation on WikiText-2 using LLaMA-2-13B at 2-bit quantization.
→ Maintains under 1.7% degradation on GSM8K benchmark, demonstrating strong Chain-of-Thought reasoning.
→ Reduces peak memory usage by 3.97× and achieves a 2.32× decoding speedup.