
Sakana AI shows that several frontier models can think together
Sakana AI blends frontier models with Adaptive Branching MCTS, researchers craft human-thought-like AI, Sutskever takes SSI helm after Gross, and Velvet Sundown’s Suno-made Spotify hits

Read time: 8 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (3-July-2025):
🥉 Sakana AI shows that several frontier models can think together under an Adaptive Branching Monte Carlo Tree Search routine
🧠 New Researchers develop AI that mimics human thought
📡 TOP GITHUB Repo: GenAI Agents: Comprehensive Repository for Development and Implementation
🗞️ Byte-Size Briefs:
Ilya Sutskever, OpenAI co-founder, is now CEO of Safe Superintelligence (SSI) after Daniel Gross's departure.
🎸 Velvet Sundown admits using Suno to generate songs after amassing 500,000 Spotify listeners, exposing gaps in platform AI-disclosure rules.
🥉 Sakana AI shows that several frontier models can think together under an Adaptive Branching Monte Carlo Tree Search routine
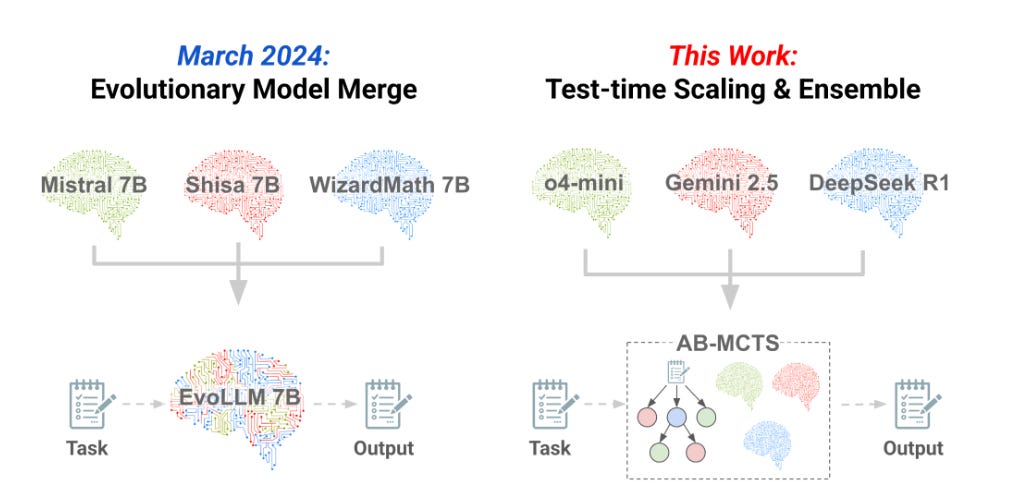
Sakana AI shows that several frontier models can think together under an Adaptive Branching Monte Carlo Tree Search routine, and that teamwork breaks puzzles no single model can crack, lifting ARC‑AGI‑2 success to 30%.
LLMs use fixed sampling or fixed refinement and still miss many ARC‑AGI‑2 tasks.
AB‑MCTS lets a search either widen with a fresh attempt or deepen by polishing a promising draft, and Multi‑LLM AB‑MCTS also picks the model that fits each step, so the same 250‑call budget solves 30% instead of 23%.

The picture sums up how Adaptive Branching MCTS grows its search tree. The top dot is the starting answer, the dotted lines show possible moves. The blue arrow to the right means the algorithm can jump sideways, spin up a fresh answer, and test a brand-new idea. The arrow to the left means it can drop down, stick with a promising answer, and keep fixing it.
By switching between these two moves on the fly, the system spends its call budget smarter, so a team of models reaches the right answer more often than any single fixed strategy.
🧩 One model thinking longer still stalls when its first guess heads the wrong way. A second model that only restarts never fixes near misses. AB‑MCTS copies how people alternate between trying again and tweaking.
🍃 The search tree adds a special GEN branch at every node. Thompson sampling weighs the payoff of a brand‑new answer against the payoff of refining what is already there, so the tree grows wider when ideas run dry and dives deeper when an idea looks good.

🔀 Depth‑width balance matters. Repeated sampling reaches 23% at 250 calls. AB‑MCTS reaches 27.5% because after roughly 50 calls it starts recycling the best partial code instead of rolling more dice.
🤝 Multi‑LLM mode adds a generator choice. Gemini‑2.5‑Pro drafts code fast, o4‑mini spots patterns, DeepSeek‑R1 edits bugs. The algorithm tracks which model earns reward on the current branch and hands the next move to that model. A bar chart in the report shows a clear tilt toward the strongest model once reward rises.
📊 With the trio active, pass rate crosses 30%. A tree example in the paper shows o4‑mini writes wrong but helpful code, then DeepSeek‑R1 and Gemini‑2.5‑Pro fix it in the next hops, proving genuine collaboration rather than simple voting.
🪄 TreeQuest, the open‑source framework, wraps these ideas behind a simple API and resumes interrupted searches, so any developer can plug frontier APIs into the same collective brain.
Overall, this research fits a growing habit in AI where many models tackle different parts of a job together.
That approach lets an orchestrator pick the best model for each step, so the team fixes weak spots that would block a lone model. Using several specialists can push progress faster than relying on one huge model because their skills add up instead of overlapping. A big jumps in the field may come from this cooperative style, not from only making a single model larger.
🧠 New Researchers develop AI that mimics human thought

Helmholtz Munich researchers built Centaur, an AI that mirrors human choices and behaviors with striking accuracy by digesting millions of psychology-experiment decisions.
Key Takeaway: feeding a large language model detailed behavioral records can turn it into one general tool that echoes human decision patterns across many situations without harming its normal language abilities.
Cognitive science still relies on many small models that only work in 1 narrow task.
The team answered this by collecting Psych‑101, a text version of 160 experiments with 60 092 participants and more than 10 million individual choices, then fine tuning Llama 3.1 70B on this data with lightweight adapters.
Centaur’s training material covers bandits, memory, decision making, supervised learning and sequential control, so the model sees the full story of every participant in plain language before predicting the next action.
Training and Results:
Fine tuning touched just 0.15% of parameters, ran for about 5 days on 1 A100 80 GB GPU and used QLoRA, so the base knowledge stayed intact while the adapters learned human‑style choice patterns.
Centaur keeps predicting human choices accurately even when researchers switch the story, add extra arms to a bandit task, or move to completely new logic puzzles. In those tougher settings its mistake rate drops to about half of both the original Llama model and the best hand-built psychology models.
When the team lets Centaur act on its own in simulated tasks it tries out options the same way people do, showing it learned a human-like way of balancing exploration and exploitation.
Hidden layers in Centaur line up better with brain scans of language and reward areas than the untuned backbone, so the tighter behavioral fit reflects internal computations that look more like real neural activity.
A worked example on multi‑attribute choice used Centaur to spot cases where people ignored rating counts in favor of 1 high‑validity expert; incorporating this insight produced a new weighted heuristic that matched Centaur’s fit while staying interpretable.
Centaur held its ground on machine learning benchmarks like ARC, GSM8K and MMLU, and even became more truthful by 1 standard error on TruthfulQA, meaning the behavioral fine tune did not harm general capabilities.
📡 TOP GITHUB Repo: GenAI Agents: Comprehensive Repository for Development and Implementation
Build, study, and ship 45 production-ready GenAI agents across LangGraph, LangChain, CrewAI and AutoGen via step-by-step notebooks, deterministic state graphs, memory, RAG pipelines, and real-world benchmarks, accelerating experimentation and deployment.
Many example code for the following.
Design conversational, analytical, creative, and task-oriented agents with memory layers, short-term vs long-term retention, and self-reflection loops for continuous improvement
Implement RAG pipelines, vector stores, and structured retrieval for contracts, regulations, news, and scientific PDFs, ensuring grounded answers and reproducible evaluation metrics
Integrate external APIs—web search, Pinecone, Playwright, OpenWeatherMap, YouTube—to augment reasoning, automate browsing, scrape data, and trigger downstream actions
Generate multimodal outputs: GIFs, memes, music, TTS audio, podcasts, dashboards, and emails through chained image, audio, and document tooling
Automate QA, testing, and self-healing code with inspector agents, risk analysis, reflection cycles, and vectorized bug memory for robust production deployments
Apply performance benchmarks, retry logic, and human-in-the-loop controls to validate agent quality, mitigate hallucinations, and manage high-severity scenarios
🛠️ SemiAnalysis reports, ‘How Oracle Is Winning the AI Compute Market’

AI builders needed massive GPU clusters but capacity in the usual data‑center hubs was already booked.
Oracle solves this by locking 2,000MW of new space in places like Abilene, mixing cheap debt, fast prefab builders, and a lean Ethernet fabric to spin up clusters in months instead of years.
Oracle signed huge long‑term leases and used its own high‑speed networking to put more GPUs on the market faster and cheaper than rivals, so cloud customers are rushing to the company for training clusters.
📈 Oracle grabbed spaces across Texas and other low‑demand regions, then offered that space to OpenAI and others on 5‑year compute contracts while it keeps 15‑year site leases, absorbing location and duration risk for its customers.
🚀 The first 880MW block in Abilene is already filled by OpenAI, so Oracle’s remaining performance obligations jumped and its forecast now includes about $130B of GPU orders over the next 12 months.
🌏 In Southeast Asia Oracle partners with DayOne to build modular halls near Singapore and Johor, giving ByteDance up to 700MW next year and planning for 2GW by 2028, making that region the world’s second‑largest AI hub.
🔧 Oracle’s clusters run RoCEv2 on standardized Ethernet plus Foxconn‑built servers, cutting network and server capex about 20% against neocloud providers that rely on pricier InfiniBand and OEM enclosures.
💰 Investment‑grade credit lets Oracle finance these builds at single‑digit rates, so it can undercut other hyperscalers that expect higher internal returns and neocloud firms that borrow at double‑digit coupons.
🧩 The mix of long leases, prefab partners, cheap money, and lean networking lands big clusters quickly in whichever region has power, turning Oracle into an “investment‑grade neocloud” that sits between traditional hyperscale and short‑term GPU renters.
📊 SemiAnalysis still flags margin questions because Oracle must upsell higher‑value services to offset the thin spread on raw GPU hours, but the immediate hardware revenue is secured by multi‑year customer commitments that match its lease liabilities. Read the full report here.
🗞️ Byte-Size Briefs
Ilya Sutskever, OpenAI co-founder, is now CEO of Safe Superintelligence (SSI) after Daniel Gross's departure. Sutskever confirmed the leadership change and addressed acquisition rumors, emphasizing SSI's focus on building safe superintelligence. The company, most recently valued at $32 billion, has attracted attention from major tech leaders, including Meta's Mark Zuckerberg. Daniel Levy will serve as SSI's president moving forward.
🎸 Velvet Sundown admits using Suno to generate songs after amassing 500,000 Spotify listeners, exposing gaps in platform AI-disclosure rules.
The group landed on major platforms with zero past press or gig history. Reddit threads and musician forums mocked unnatural photos and copy-paste bios, suspecting automated creation.
Deezer flagged probable AI, yet Spotify required no proof of human origin, so the tracks slipped into 30+ influential playlists and spread widely.Front-facing member Andrew Frelon first mocked claims. In a Rolling Stone call he conceded Suno’s Persona tool produced at least part of the catalogue, letting 1 synthetic voice front every track.
That’s a wrap for today, see you all tomorrow.