
🧠 Sam Altman says OpenAI’s models are “beginning to find critical vulnerabilities”
Agentic coding at inference-speed, Meta’s SWE-RL self-repair setup, OpenAI’s bug-finding LLMs, Tencent’s WeDLM, Meta buys Manus AI, and Qwen’s multilingual voice cloning.

Read time: 11 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (30-Dec-2025):
🧠 Sam Altman says OpenAI’s models are “beginning to find critical vulnerabilities,” so OpenAI is hiring a $555,000 Head of Preparedness to tighten how it tests and ships agentic systems.
🏆 Tencent just released WeDLM 8B Instruct on Hugging Face
🚨 Meta Buys AI Startup Manus for More Than $2 Billion
🛠️ TUTORIAL: Shipping at Inference-Speed with Agentic Coding
🗞️ Meta rolled out Self-play SWE-RL, a setup where one model writes buggy code and learns by repairing its own mistakes.
🌍 Qwen, backed by Alibaba, just launched 2 Flash TTS models targeting voice styling and rapid multilingual voice cloning.
🧠 Sam Altman says OpenAI’s models are “beginning to find critical vulnerabilities,” so OpenAI is hiring a $555,000 Head of Preparedness to tighten how it tests and ships agentic systems.
OpenAI has earlier warned that frontier models could enable 0-day remote exploits, and recently Anthropic reported a China-linked campaign using Claude Code against about 30 targets with 80%-90% automation, so “advisor” models are starting to look like operators.
🏆Tencent just released WeDLM 8B Instruct on Hugging Face

🚀 A diffusion language model that 3-6× faster than vLLM-optimized Qwen3-8B on math reasoning tasks
📈 Outperforms base Qwen3-8B-Instruct on most benchmarks
✅ Native KV cache compatible (FlashAttention, PagedAttention, CUDA Graphs)
Classic autoregressive decoding is slow because it must emit 1 token at a time, and many diffusion language models try to fix that with bidirectional attention but then lose prefix key-value (KV) cache reuse, so parallel prediction does not become real wall-clock speed. WeDLM’s core trick is “topological reordering,” which physically moves the already-known tokens into a prefix so masked positions can condition on more context while the model still runs with a strict causal attention mask.
Training uses a dual-stream setup, a clean memory stream plus a masked prediction stream, and inference uses streaming parallel decoding that commits confident tokens into the growing left-to-right prefix while a sliding window refills new masks. Because committed tokens immediately become normal prefix context, the design stays compatible with native KV cache paths like FlashAttention, PagedAttention, and CUDA Graphs, which is where optimized serving engines get much of their speed. The model is fine-tuned from WeDLM-8B, initialized from Qwen3-8B, and keeps a 32,768 context window like the base.
🚨 Meta Buys AI Startup Manus for More Than $2 Billion

The parent company behind Manus, which was founded in China before moving to Singapore, also raised money earlier this year at close to a $500 million valuation from a collection of investors, including the venture capital firm Benchmark. Manus also reported $100M in annual recurring revenue (ARR) and a $125M total revenue run rate, which is unusually fast for an agent product that has real infrastructure costs.
Meta has not disclosed a price, but multiple outlets report “more than $2 billion”, and some sources peg a range of $2–3 billion. The agreement reportedly came together in about 10 days.
Meta says it will keep operating and selling the Manus service, and it will also integrate Manus technology into Meta products, including Meta AI.
Manus has roughly 100 staff and will remain based in Singapore. Meta plans to fold in the technology and leadership team, with Manus CEO Xiao Hong expected to report to Meta COO Javier Olivan.
All Chinese ownership interests will be removed at closing, and Manus will discontinue any services and operations that it may have in China.
Manus crossed $100 million in annual recurring revenue in December, and earlier in the year it was on a $125 million run rate.
On financing history, Butterfly Effect, the parent behind Manus, raised $75 million in April–May 2025 at a ~$500 million valuation in a round led by Benchmark, with participation from Tencent, ZhenFund, and others. The acquisition will reportedly buy out all existing investors.
🛠️ TUTORIAL: Shipping at Inference-Speed: dives deep into how we can ship code at speeds with “Agentic Coding” that once seemed unreal and discusses the author’s workflow for building software.

This walkthrough shows how to ship software faster by treating the model as the main developer, then shaping projects so agents can read, plan, and execute with minimal hand holding.
You learn the model choices, the workflow that keeps momentum, and a config that unlocks large contexts without breaking runs.
Use gpt-5.2-codex high as the default and trust it to read broadly before writing. Keep Opus for lighter edits, but lean on codex for big refactors because it reads first then changes code safely.
Pick TypeScript for web, Go for CLIs, and Swift for macOS or UI because agents write them reliably. Keep a /docs folder and let the model create files like docs/*.md, then reuse patterns by pointing it at sibling projects.
Queue tasks, watch the stream, and commit to main to avoid branching overhead. Ask the model to revise when results are off, and use simple prompts plus small UI screenshots to direct edits.
The “oracle” CLI for long research runs is optional now since 5.2 reduced blocked cases from many times per day to a few times per week. It still helps when you need a deep scan across many sources.
A real example shows strength, codex converted a core forwarding system to zig in 1 shot after ~5 hours with several compactions. Long reads plus compaction finished a job older models kept breaking.
👨🔧 New Paper shows vibe coding speeds a quick first product demo, but it piles up tech debt that bites later.

This is one of the first papers to clearly name and explain the flow versus debt tradeoff, where AI driven coding boosts short term speed but systematically creates hidden problems in security, architecture, testing, and maintenance.
In 7 vibe-coded prototype apps, 970 security issues showed up, and 801 were tagged high severity.
Vibe coding means a developer describes the feature in plain English, and a generative AI model generates most of the code for a Minimum Viable Product, the smallest version that still works.
That fast loop feels smooth because new screens and features appear in minutes, but tech debt builds up, meaning later changes get slow and risky.
The authors trace the debt to vague prompts, missing non-functional requirements like security and speed, and repeated regenerations that quietly change earlier design decisions.
One real example was a bug that stayed unfixed while the AI rewrote how data moved around, added new server routes, and grew the codebase by 100s of lines.
Their main advice is to treat AI output as a first draft, then add guardrails like structured prompts, clear module boundaries, prompt and version logs, real tests, and automated security checks.
🗞️ Meta rolled out Self-play SWE-RL, a setup where one model writes buggy code and learns by repairing its own mistakes.

AgentInfer, proposed in this paper, cuts wasted tokens by over 50% and speeds up real agent task completion by about 1.8x to 2.5x.
AgentInfer is a system that makes Large Language Model agents finish tool tasks faster.
A Large Language Model writes chatbot text, and an agent makes it loop, think, call tools like web search, read results, then write again.
These loops get slow because the chat history keeps growing, so every new step has more old text to reread.
AgentCollab uses 2 models, the big model plans and fixes stalls, and the small model does most steps after quick self checks.
AgentCompress keeps the important tool outputs but trims noisy search junk, and it summarizes in the background so the input stays smaller.
AgentSched avoids throwing away cached context when memory is tight, and AgentSAM reuses repeated text from past sessions to draft the next chunks the main model checks.
The punchline is that agent speed comes from coordinating reasoning, memory, and server scheduling, meaning which request runs next, not from faster decoding alone.
🌍 Qwen, backed by Alibaba, just launched 2 Flash TTS models targeting voice styling and rapid multilingual voice cloning.
Qwen3-TTS-VD-Flash (voice design) turns a natural-language description into a persistent voice that can be listed and reused in later calls, so a dialogue agent can keep the same persona across turns.
Qwen3-TTS-VC-Flash (voice cloning) extracts a speaker from about 3s of reference audio and then generates that voice in 10 languages, aiming to keep timbre consistent when the text language changes.
Technically, both features look like a 2-step pipeline, first create or extract a compact voice representation, then run speech synthesis conditioned on that representation plus the requested text and style.
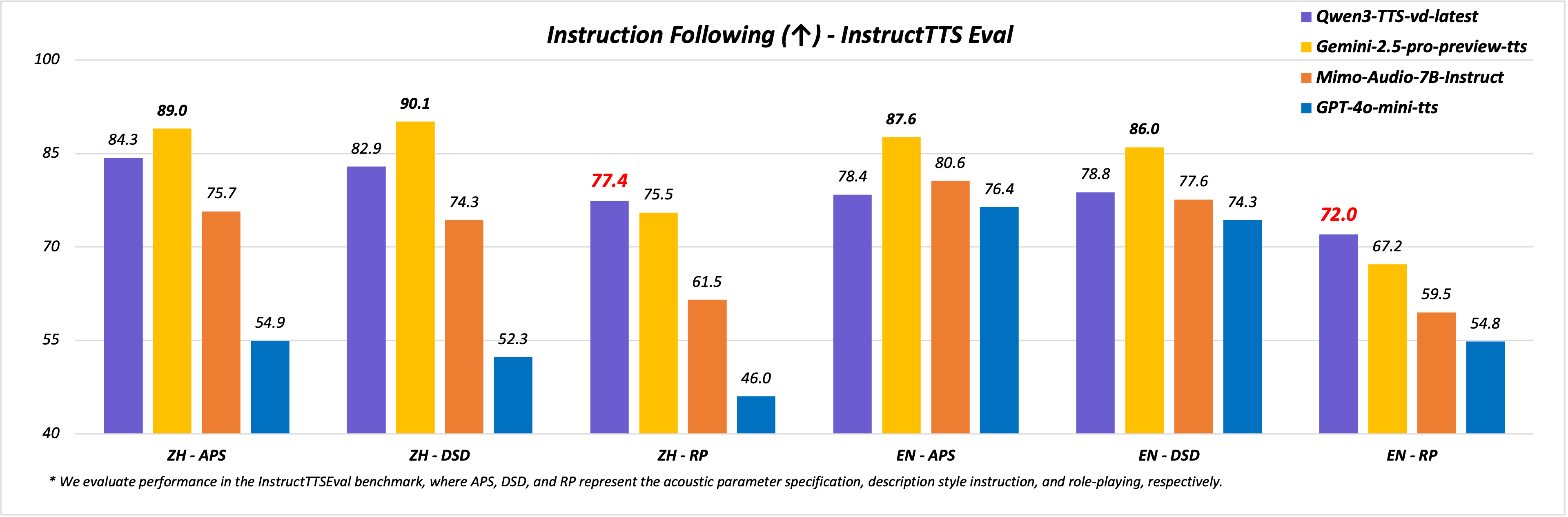
For instruction-following style control, Qwen points to InstructTTSEval, which tests APS for low-level controls, DSD for messy prompts, and role-play for persona matching.
Qwen claims stronger APS and DSD than GPT-4o-mini-tts and Mimo-Audio-7B-Instruct, and stronger role-play than Gemini-2.5-pro-preview-tts, on that benchmark.
For multilingual cloning, Qwen claims the best average WER, meaning fewer words get mangled when the audio is checked by speech recognition, on the MiniMaxAI 24-language cloning test set.
This voice as an object interface should make it easier for product teams to version and swap voices safely, and the real test will be how stable the voice stays with short and noisy reference clips.
That’s a wrap for today, see you all tomorrow.