SANA : EFFICIENT HIGH-RESOLUTION IMAGE SYN - THESIS WITH LINEAR DIFFUSION TRANSFORMERS
Tiny model beats giants: 0.6B parameters outperform 12B models in speed


Tiny model beats giants: 0.6B parameters outperform 12B models in speed
Sana generates 4K images 100x faster by making diffusion models ultra-efficient
Smart compression and linear attention make high-res image generation blazing fast
🔧 Solution in this Paper:
• Deep compression autoencoder that compresses images 32x instead of traditional 8x
• Linear DiT replacing vanilla attention with linear attention for O(N) complexity
• Decoder-only text encoder using Gemma with complex human instruction
• Flow-DPM-Solver for reduced sampling steps (14-20 vs 28-50)
• Mix-FFN with 3x3 convolution for better local information
• No positional encoding needed
• Efficient training with multi-caption auto-labeling and CLIP-score based sampling
💡 Key Insights:
• Linear attention with proper design can match vanilla attention quality
• Deep compression (32x) works better than traditional 8x for high-res
• Modern small LLMs can replace T5 for better text understanding
• Position encoding isn't necessary with proper convolution design
📊 Results:
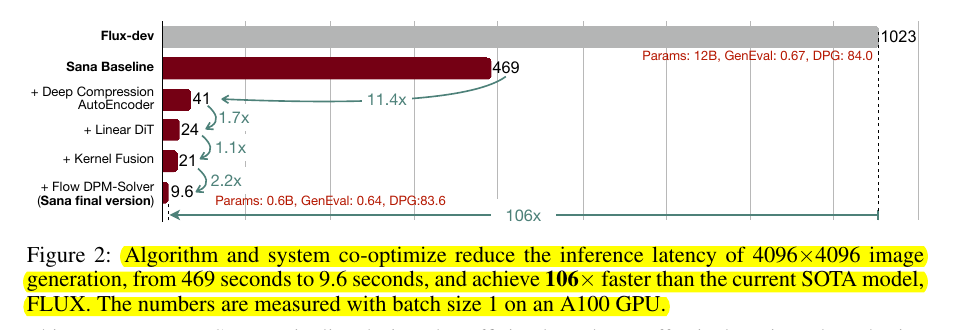
• 100x faster than FLUX for 4K image generation
• 40x faster for 1K resolution
• Generates 1024x1024 images in <1 second on laptop GPU
• Competitive quality with 20x smaller model (0.6B vs 12B parameters)
• Achieves 0.64 GenEval score with only 590M parameters
The core technical designs include:
Deep compression autoencoder that compresses images 32x instead of traditional 8x compression
Linear DiT replacing vanilla attention with linear attention for better efficiency
Decoder-only text encoder using modern small LLM (Gemma) with complex human instruction
Flow-DPM-Solver for reduced sampling steps and efficient training strategies