
"Scaling Embedding Layers in Language Models"
Below podcast on this paper is generated with Google's Illuminate.

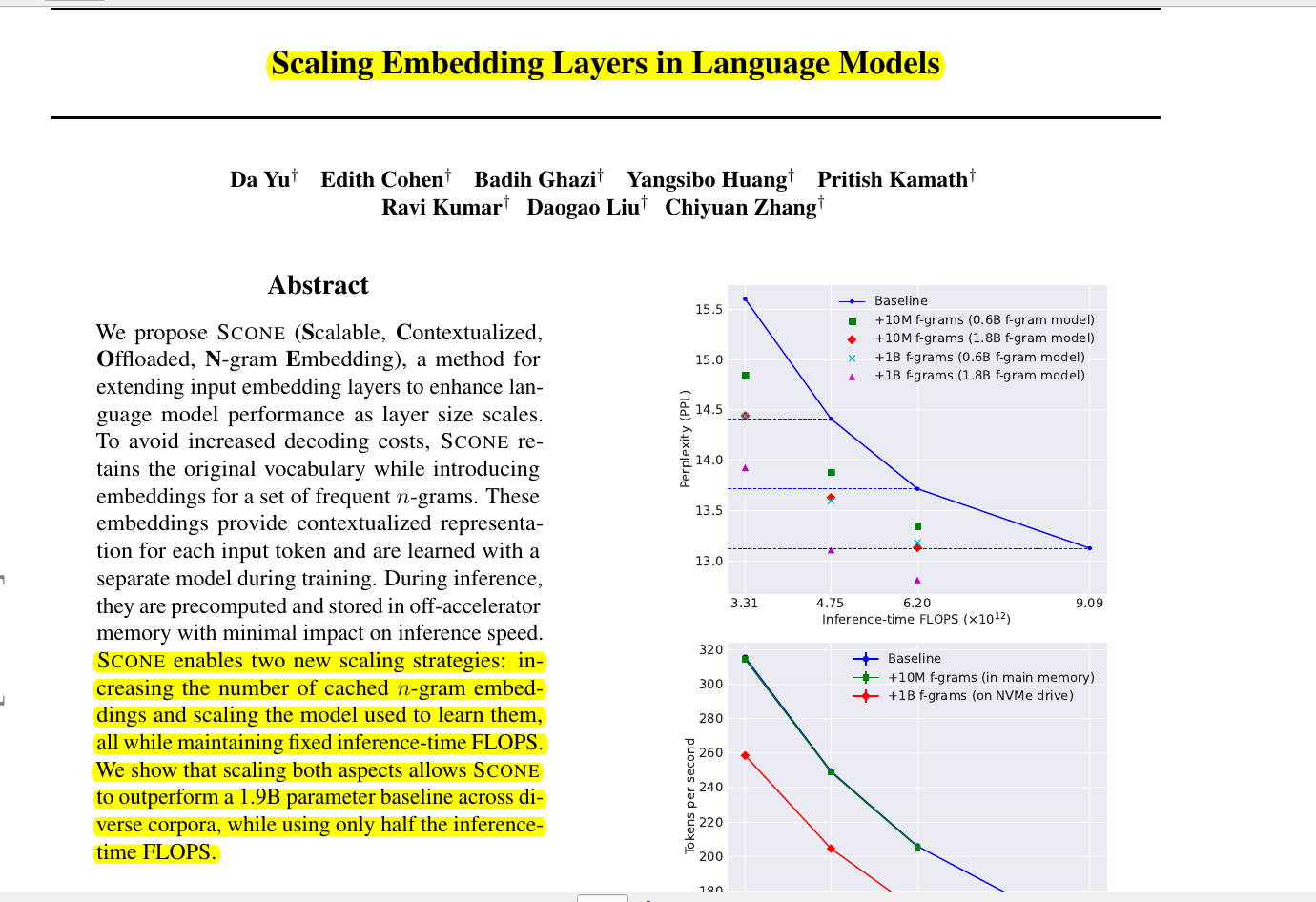
→ Scaling vocabulary size in LLMs leads to diminishing returns and increased computational costs during inference.
→ Larger vocabularies cause sparse updates to token embeddings during training, degrading performance.
→ Increasing vocabulary size increases GPU memory usage linearly, making it impractical for very large vocabularies.
This paper introduces SCONE, a method to improve LLM (LLM) performance by scaling input embedding layers. SCONE enhances token representations using contextualized embeddings of frequent n-grams (f-grams). These embeddings are learned during training and efficiently retrieved from off-accelerator memory during inference, maintaining inference speed while improving scalability.
-----
https://arxiv.org/abs/2502.01637
📌 SCONE effectively decouples input embedding scaling from inference cost. It cleverly uses off-chip memory for extended contextual embeddings. This maintains latency while boosting model capacity by scaling n-gram embeddings.
📌 Training a separate f-gram transformer model to generate contextual embeddings is key. This avoids sparse update issues common in large flat embedding tables, leading to better representation learning for frequent phrases.
📌 Pre-computing and caching f-gram embeddings enables practical scaling of input representation size. This architecture cleverly shifts computational burden to training, while preserving inference efficiency, critical for real-world LLM deployment.
-----
Methods in this Paper 🔧:
→ SCONE method augments the standard token embedding layer with contextualized embeddings for frequent n-grams (f-grams).
→ It retains the original token vocabulary and introduces embeddings for frequently occurring token sequences up to length 'n'.
→ During training, a separate transformer model (f-gram model) learns these contextualized f-gram embeddings.
→ During inference, these f-gram embeddings are pre-computed and stored off-accelerator for fast lookup, minimizing impact on inference speed.
-----
Key Insights 💡:
→ SCONE decouples input embedding scaling from output layer computation, avoiding increased inference cost with larger embeddings.
→ It allows scaling model performance by increasing the number of cached f-gram embeddings without raising inference FLOPS.
→ Scaling the size of the f-gram model during training further improves performance while keeping inference FLOPS constant.
→ Offloading f-gram embeddings to system memory or disk makes scaling embedding layers to billions of entries feasible.
-----
Results 📊:
→ A 1B parameter model with SCONE outperforms a 1.9B baseline model in average perplexity across diverse datasets.
→ SCONE with 1B f-grams achieves average perplexity of 14.581, surpassing the 1.9B baseline's 14.598.
→ Using 10M f-grams, a 1.3B model with SCONE matches the performance of the 1.9B baseline model.