
"Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach"
Below podcast on this paper is generated with Google's Illuminate.

https://arxiv.org/abs/2502.05171
The paper addresses the challenge of enhancing reasoning in LLMs without drastically increasing model size or relying on specialized training data like chain-of-thought examples. Current methods often scale compute by generating more tokens, which can be inefficient.
This paper proposes a novel LLM architecture using a recurrent depth approach. It enables scaling test-time computation by iteratively refining latent representations, rather than verbalizing intermediate thoughts. This method works with standard training data and smaller context windows, potentially capturing reasoning forms beyond verbalization.
-----
📌 Recurrent architecture enables test-time compute scaling. This offers a parameter-efficient way to enhance reasoning without increasing model size. Deeper inference at test time improves performance on complex tasks.
📌 Latent space recurrence allows for implicit reasoning. This contrasts with explicit chain-of-thought. Model "thinks" in continuous space, potentially capturing non-verbal reasoning.
📌 Variable recurrence during training is key. Random iteration counts force model to generalize across compute budgets. Truncated backpropagation enables efficient training despite recurrent depth.
----------
Methods Explored in this Paper 🔧:
→ Introduces a depth-recurrent LLM architecture. It is built upon standard decoder-only transformer blocks.
→ These blocks are organized into three parts: Prelude, Recurrent block, and Coda. The Prelude embeds input into a latent space.
→ The core Recurrent block iteratively refines a latent state. The Coda un-embeds the latent state and predicts the next token.
→ A key feature is the recurrent block which loops for a variable number of iterations during training and testing. This allows for scaling compute at test-time without increasing model parameters.
→ During training, the number of recurrent iterations is randomly sampled from a log-normal Poisson distribution. This ensures the model learns to function with varying compute.
→ To manage computational cost, truncated backpropagation is used. Backpropagation is limited to the last 8 recurrent iterations.
→ The model is trained on a diverse dataset favoring code and mathematical reasoning data. This aims to promote emergent reasoning abilities.
-----
Key Insights 💡:
→ Depth-recurrent models can effectively learn and improve performance by scaling test-time computation.
→ Latent reasoning can capture complex reasoning beyond verbalization, like spatial or numerical reasoning.
→ Recurrent models naturally support features like per-token adaptive compute, KV-cache sharing, and self-speculative decoding, simplifying LLM use cases.
→ The model exhibits context-dependent convergence and path independence in its latent space, suggesting complex computational behaviors emerge with scale.
-----
Results 📊:
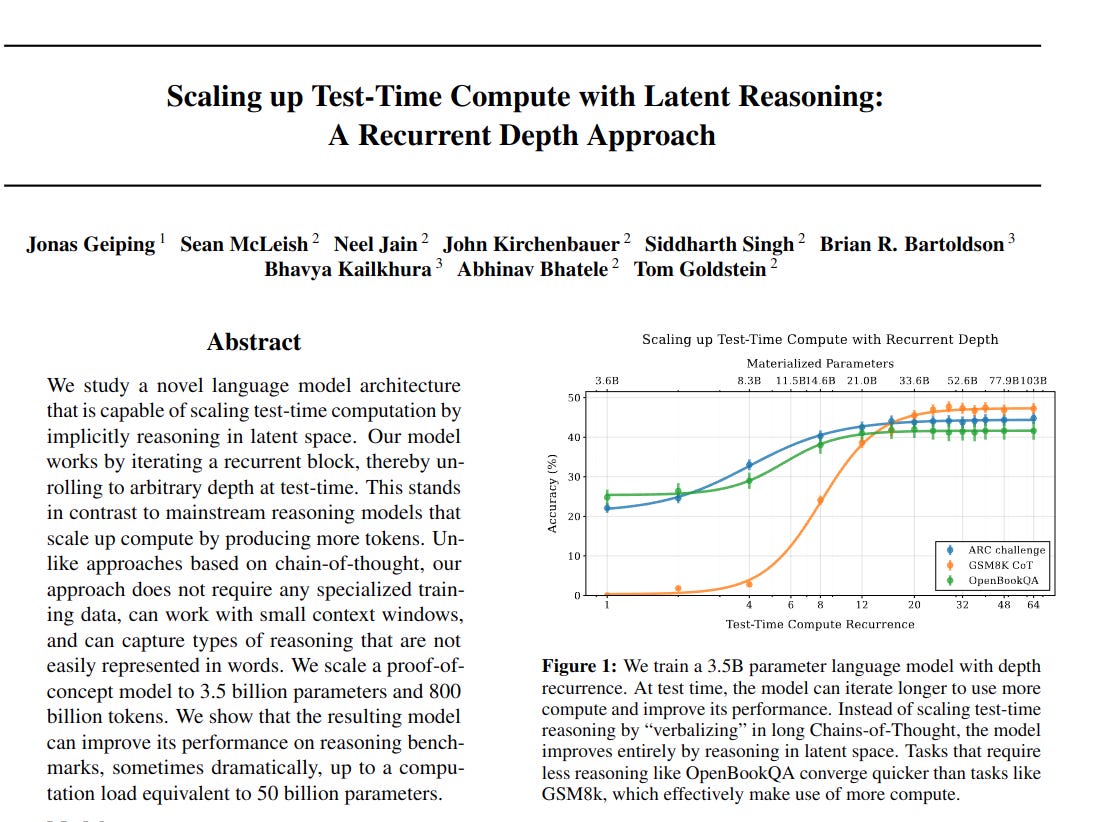
→ The 3.5B parameter recurrent model achieves performance comparable to 7B parameter models on standard benchmarks.
→ On mathematical reasoning tasks like GSM8K, the model surpasses most open-source models, showing significant gains from recurrent depth.
→ Performance on harder tasks like ARC challenge and GSM8K improves significantly with increased test-time compute (more recurrent iterations).
→ At 180B training tokens, the recurrent model outperforms a non-recurrent baseline, especially on challenging reasoning tasks.