


Table of Contents
Selection of Base Foundation Models (LLaMA 3, Mistral, Google, Falcon, MPT)
Orchestration & Workflow (LangChain, LangGraph, AutoGen)
Knowledge Storage: Vector Databases and Graph Databases
Self-Critique and Reasoning Mechanisms (CoT, Reflexion, Constitutional AI)
Evaluation and Feedback (LangSmith Evals, RAGAS, W&B)
Lightweight Fine-Tuning and RL (PPO, DPO, LoRA, QLoRA)
Preventing Bias Amplification with Open-Source Safeguards
Blueprint of a Self-Improving LLM System
Scalable Deployment and Serving (vLLM, Triton, TGI)
Maintaining Alignment with Human Intent
1. Selection of Base Foundation Models (LLaMA 3, Mistral, Google, Falcon, MPT)
Choosing a foundation model is the first step in building a self-improving LLM system. Modern open models like LLaMA 3, Mistral, Google Gemma, Falcon, and MPT offer different trade-offs in instruction-following capability, reasoning performance, size, and licensing. LLaMA 3 (Meta AI’s latest) ranges from 8B up to a massive 405B parameters and natively supports multilingual, coding, and reasoning tasks ([2407.21783] The Llama 3 Herd of Models).

Its largest 70B and 405B versions achieve performance on par with GPT-4 on many benchmarks, though at substantial computational cost. Notably, LLaMA 3’s 70B “Instruct” model (fine-tuned for instructions) is almost as capable as the 405B model, offering strong reasoning at a fraction of the cost (The 11 best open-source LLMs for 2025 – n8n Blog). Meta also introduced a 128k token context window in LLaMA 3, enabling long-context reasoning.

Meanwhile, Mistral AI has focused on efficiency and smaller models. Mistral 7B (2023) surprised the community by outperforming some 13B models like LLaMA-2 on benchmarks, and the company rapidly iterated with models up to 12–13B and beyond (Mistral AI Releases Three Open-Weight Language Models - InfoQ). In mid-2024, Mistral released Large 2 (123B), claiming it rivals the latest from OpenAI/Meta in code generation and math reasoning, despite being 3× smaller than LLaMA-3 405B (Mistral's Large 2 is its answer to Meta and OpenAI's latest models | TechCrunch). Mistral’s approach emphasizes extended context (e.g. the 12B Mistral NeMO supports 128k tokens) and multilingual training (Mistral AI Releases Three Open-Weight Language Models - InfoQ). Notably, Mistral models are released under permissive open-source licenses (Apache 2.0 for 7B/12B variants). This makes them easy to fine-tune and deploy commercially. Mistral NeMO (12B) is a strong general model that outperforms similarly-sized competitors like Gemma 2 9B and LLaMA-3 8B on tasks like MMLU and Winogrande (Mistral AI Releases Three Open-Weight Language Models - InfoQ). For specialized needs, Mistral also provides models like Codestral Mamba (7B code generator with a novel Mamba architecture for faster inference) and Mathstral (7B fine-tuned for STEM reasoning) achieving state-of-the-art math performance for its size (Mistral AI Releases Three Open-Weight Language Models - InfoQ).
Google Gemma is another open model family, aimed at responsible AI development. Initially released in early 2024, Gemma started with 2B and 7B text models plus instruction-tuned variants (Gemma: Google introduces new state-of-the-art open models). Though small, they were built on the same research as Google’s flagship Gemini, and included a Responsible AI Toolkit for safer deployments (Gemma: Google introduces new state-of-the-art open models). By mid-2024, Google expanded this to Gemma 2 with 9B and 27B models distilled from larger ones, and even multimodal and recurrent variants (e.g. RecurrentGemma for long-sequence efficiency). The Gemma models are designed for lightweight deployment on diverse hardware (including GPUs and even mobile/Android via projects like MediaPipe) and come with permissive usage via Google Cloud. They are particularly useful where smaller models suffice or resource budget is limited. For instance, Gemma 7B can handle general tasks and follow instructions reasonably, but will not match the depth of LLaMA 70B on complex reasoning. The open availability of Gemma on HuggingFace and Kaggle means practitioners can fine-tune them easily, and Google provides integration examples with TensorRT-LLM and Triton for optimized serving (Gemma: Google introduces new state-of-the-art open models).
The Falcon series, developed by TII (UAE), includes Falcon 40B and the later Falcon 180B, which was the largest openly released model of 2024. Falcon 180B delivered state-of-the-art results among open models, rivaling Google’s PaLM2 on many tasks (Spread Your Wings: Falcon 180B is here). It was trained on 3.5 trillion tokens and made available for research and commercial use, solidifying itself as one of the most capable open LLMs (Spread Your Wings: Falcon 180B is here). However, running Falcon 180B in production is a significant challenge – it requires multiple high-memory GPUs and careful optimization. TII also recognized the need for more accessible models and introduced Falcon 3 small models (1B, 3B, 7B, 10B) with an architecture optimized for resource-constrained environments (The 11 best open-source LLMs for 2025 – n8n Blog). Falcon 3 models use techniques like state-space layers (Falcon3-Mamba variant) and were trained on 14T tokens, giving them strong performance despite their size (The 11 best open-source LLMs for 2025 – n8n Blog). In practice, this means if you need an on-edge or CPU-friendly model for basic tasks, Falcon 7B or 10B (Falcon 3 series) could be a good choice, whereas Falcon 180B or LLaMA 70B would be chosen for maximum accuracy when ample GPU resources are available. Falcon models come with a permissive Apache 2.0 license, allowing commercial fine-tuning and deployment.
Finally, MosaicML’s MPT (Mosaic Pretrained Transformer) models are known for their long-context and open licensing. MPT-7B and MPT-30B (released 2023) were among the first open models to allow commercial use without a strict license. MPT-30B was trained on 1T tokens with an 8k context and showed solid performance, outperforming the original GPT-3 175B on some tasks (MPT-30B: Raising the bar for open-source foundation models | Databricks Blog). Mosaic provided fine-tuned variants like MPT-30B-Instruct and -Chat, which were proficient at single-turn instructions and multi-turn dialogue (MPT-30B: Raising the bar for open-source foundation models | Databricks Blog). The key strengths of MPT are its efficient architecture (optimized for GPUs like H100) and specialty derivatives – e.g. MPT-7B-StoryWriter which supported 65k context for long document summarization. Although MPT models do not top the leaderboards against newer entrants like LLaMA 3, they remain highly compatible and easy to integrate (transformers-supported, with many community fine-tunes). Importantly, MPT’s Apache-2 license and focus on short-form instruction following make it a stable base for custom fine-tuning without legal ambiguity. An AI/ML engineer might choose MPT-30B-Instruct when needing a well-rounded 30B model that can be fine-tuned on domain data with LoRA and deployed with less memory than a 70B model.
Guidance: In summary, pick the largest model that your compute budget allows while considering the task needs. For complex reasoning or multi-step tasks, LLaMA 3.1 70B (or 405B if truly needed) will currently give the best quality (The 11 best open-source LLMs for 2025 – n8n Blog). If you need multilingual support or long contexts on a budget, a Mistral model (e.g. 7B or 12B with 128k context) is attractive (Mistral AI Releases Three Open-Weight Language Models - InfoQ). For very small-scale or on-device cases, Google Gemma 7B or Falcon 7B can deliver decent results with minimal footprint. Always verify the license compatibility with your use case: Gemma and Falcon are fully open for commercial use, LLaMA 3 is gated by a community license (acceptable use policy) (meta-llama/Meta-Llama-3-8B · Hugging Face), and Mistral’s smaller models are Apache 2.0 (while their 123B Large 2 may require a separate license for commercial use (Mistral's Large 2 is its answer to Meta and OpenAI's latest models | TechCrunch)). Compatibility with frameworks is generally broad – all these models can be loaded in Hugging Face Transformers. For example, LLaMA 3 and Falcon have official HF integrations, and vLLM/DeepSpeed inference support them too. Thus, the decision often comes down to scaling vs performance: use a smaller open model like Mistral or Falcon if you plan to continuously fine-tune and iterate fast, or a larger model like LLaMA for maximum baseline capability (and perhaps use retrieval augmentation to mitigate its static knowledge cutoff).
2. Orchestration & Workflow (LangChain, LangGraph, AutoGen)

Building a self-improving pipeline requires orchestrating many steps: prompting the model, collecting its outputs, critiquing those outputs, searching knowledge bases, and fine-tuning on feedback. Open-source orchestration frameworks like LangChain, LangGraph, and AutoGen help manage these multi-step workflows in a structured way. LangChain provides a high-level, composable interface for chaining LLM calls and tools (search, DB queries, etc.) together. For example, you can define a sequence: user query → LLM reasoning chain → LLM answer and LangChain will handle passing the outputs along. However, as workflows grow complex (with loops, conditional branches, or multiple agents), LangChain’s standard chains might become limiting. This is where LangGraph comes in.
LangGraph is a low-level orchestration framework for controllable, agentic workflows (Langgraph — Part 1 of LLM Multi-Agents series | by Tituslhy | MITB For All | Medium). It lets you define nodes (LLM calls or functions) and directed edges between them, essentially creating a graph of how messages flow. This is ideal for implementing system-level loop closures like “generate an answer, then critique it, then improve it, repeat N times.” LangGraph was developed as an extension of LangChain to give more control: “LangGraph is an even lower-level framework than LangChain, offering developers more control… suited for building everything from complex RAG applications to sophisticated multi-agent systems.” (Langgraph — Part 1 of LLM Multi-Agents series | by Tituslhy | MITB For All | Medium). With LangGraph, you explicitly define the loop logic rather than relying on implicit recursion. For example, below is a simple LangGraph setup for a generate → reflect loop:
from langgraph.graph import MessageGraph
# Define two LLM nodes (these could be LangChain LLM wrappers or tool calls)
builder = MessageGraph()
builder.add_node("generate", generation_node)
builder.add_node("reflect", reflection_node)
builder.set_entry_point("generate")
# Define when to continue looping: after generate, go to reflect, then back to generate
def should_continue(state):
if len(state) > 6:
return END # end after a few iterations
return "reflect"
builder.add_conditional_edges("generate", should_continue)
builder.add_edge("reflect", "generate")
graph = builder.compile()
(Code snippet: constructing a reflection loop with LangGraph, inspired by LangChain’s example (Reflection Agents).)
In this snippet, generation_node and reflection_node are routines (e.g. wrappers around an LLM) and the graph will alternate between them, using should_continue to decide when to stop looping. The stateful message passing ensures each iteration’s output (e.g. the critique text) is fed into the next step (Reflection Agents). By controlling the loop in code, you can implement sophisticated patterns like multiple critique rounds or branching logic (e.g. skip critique if initial answer is above a quality threshold).
AutoGen (from Microsoft) tackles orchestration by enabling multi-agent conversations. Instead of manually coding loops, you define agents (LLM-powered personas) and AutoGen has them talk to each other to solve tasks (AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation - Microsoft Research). For example, you might have a “Coder” agent and a “Reviewer” agent; AutoGen will alternate their conversation: coder proposes a solution, reviewer critiques it, and so on, until done (Reflection — AutoGen). Under the hood, AutoGen handles message passing, stopping conditions, and can incorporate human input or tool use as additional agents (AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation - Microsoft Research). This is powerful for self-improvement loops, as you essentially encode self-critiquing behavior as two cooperating agents. The AutoGen documentation describes this as the “Reflection” pattern: “an LLM generation is followed by a reflection (another LLM generation conditioned on the first output)... implemented as a pair of agents that continue to interact until a stopping condition” (Reflection — AutoGen). In practice, you configure each agent with a role and objective, and AutoGen manages the loop of them calling each other. For example, one agent could have the system prompt “You are a Python coding assistant,” and another “You are a strict code reviewer.” The loop might run until the reviewer “approves” the coder’s output or a max iterations is reached (Reflection — AutoGen). This is a high-level way to achieve step-by-step refinement without writing explicit while-loops.
LangChain itself also now supports reflection and self-critique patterns through higher-level abstractions. The SmartLLMChain is one such utility that implements a self-critique chain: it generates an initial answer and then an LLM critique, and merges them (Self-Critique LLM Chain Using LangChain & SmartLLMChain). The LangChain blog demonstrates “Reflection Agents” where the agent’s prompt includes an instruction to reflect on previous outputs and improve them (Reflection Agents). Essentially, it leverages prompt engineering (System 2 thinking prompts) combined with iterative calls. For instance, you might prompt the LLM: “Draft an answer. Then critique your answer for errors. Then improve it.” All in one chain call or via separate calls. LangChain and LangGraph make it straightforward to implement this pattern in a controlled way, rather than hoping the model will reflect in a single prompt. The benefit of orchestrating it explicitly is that you can insert other checks in between (like vector DB lookups or external tools).
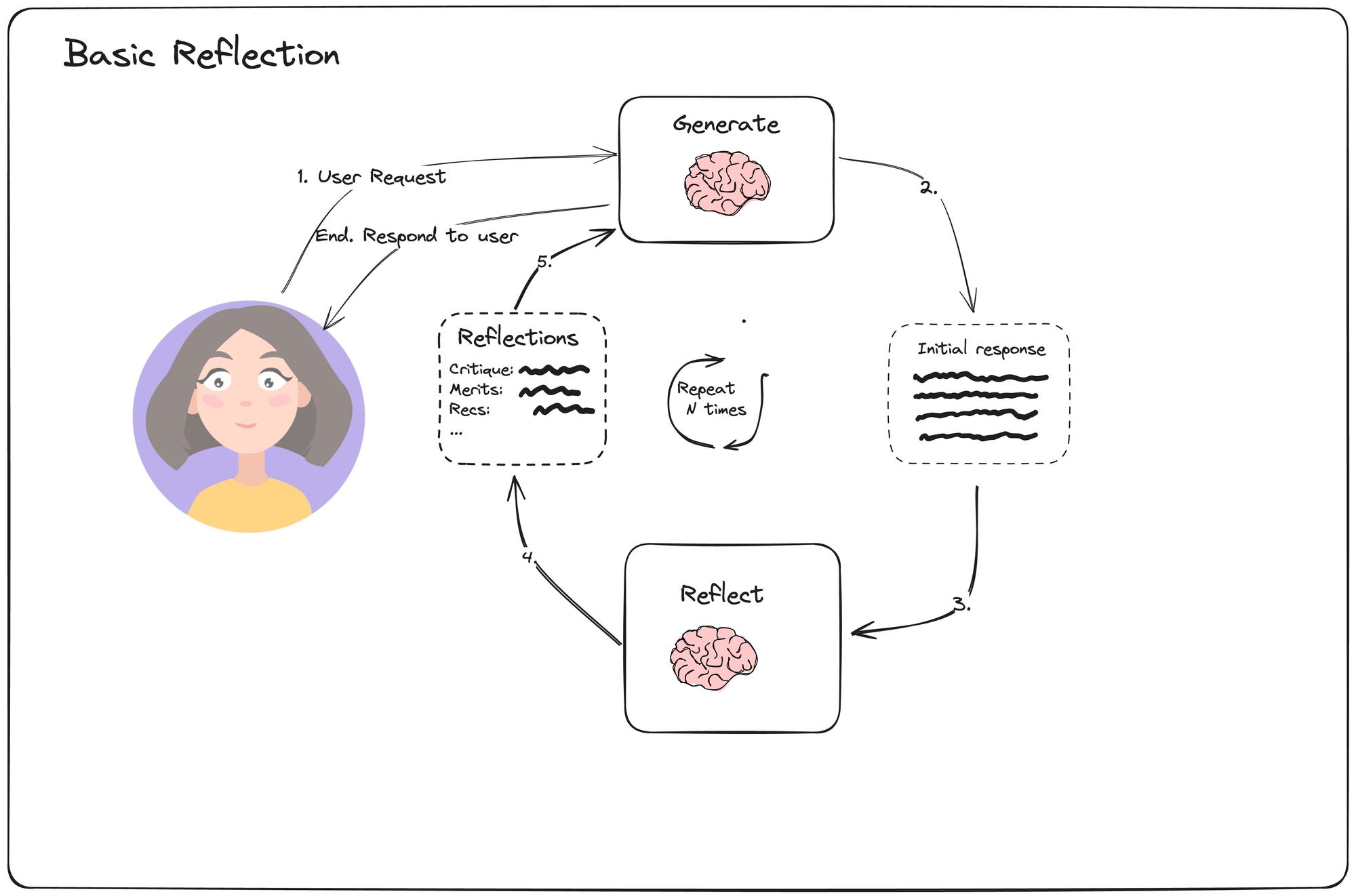
Figure: basic reflection workflow. Below is a conceptual diagram of a basic generate–reflect loop orchestrated by such a framework. The LLM generates an initial response, then a reflection step critiques it, possibly producing suggestions (merits, flaws, etc.), then the LLM generates again incorporating that feedback, and so on:
(Reflection Agents) Basic reflection loop: the system uses a Generator LLM to produce an initial answer (2), a Reflector LLM to critique that answer (3), and repeats this cycle (4→5) before returning a final refined response to the user. The orchestration framework manages the sequence and stopping condition.
In code, implementing this with LangChain/LangGraph/AutoGen means setting up the nodes/agents for “Generator” and “Reflector” (which could even be the same model with different prompts), and letting the framework route messages accordingly. AutoGen in particular provides out-of-the-box agent classes for an assistant and a critic – you simply write what each should do (e.g. one tries to answer, one gives feedback) and AutoGen will handle the loop until the critic is satisfied (Reflection — AutoGen). This automated refinement is a core part of a self-improving LLM system.
In summary, to implement step-by-step self-critiques and loop closures, you can use LangChain’s chains or AutoGen’s multi-agent conversations for simpler cases, and drop to LangGraph when you need fine-grained control (multiple tools, branching) or to optimize performance. These tools are complementary: for instance, AutoGen internally could be using LangChain to execute each agent, and LangGraph can incorporate LangChain tool calls at nodes. The key is that they save you from writing a lot of boilerplate glue code and let you focus on the logic of improvement: what steps to take, what order, and when to stop.
3. Knowledge Storage: Vector Databases and Graph Databases

A self-improving LLM doesn’t learn in a vacuum – it needs external knowledge and memory to avoid stagnation. Two popular open-source approaches for knowledge storage are vector databases (for unstructured semantic recall) and graph databases (for structured knowledge and relationships). Combining vector recall with semantic graph traversal allows the system to both remember relevant past information and reason over it.
Vector databases like ChromaDB, Qdrant, and Weaviate store high-dimensional embeddings of text, enabling similarity search to fetch relevant contexts for a query. For example, if the LLM is answering a question or refining an answer, it can retrieve related documents or prior conversations by embedding the query and performing a similarity search in the vector store. This is crucial for Retrieval-Augmented Generation (RAG) loops, where before the LLM attempts an answer, it pulls in facts from a knowledge base. Open-source options each have unique strengths: ChromaDB is easy to deploy locally (just Python, no external dependencies) and supports filtering metadata. Qdrant is a high-performance vector engine in Rust offering features like payload filters and hybrid search; it can handle real-time updates and precise cosine similarity searches (Top 5 Vector Databases in 2024). Weaviate provides a rich GraphQL interface and modular vector index plugins, making it a comprehensive solution with support for hybrid queries (combining semantic and keyword search). All three are scalable and can be self-hosted, and importantly they support storing not just embeddings but associated metadata (e.g. document IDs, titles) that can link to graph structures.
Graph databases like Neo4j (or RDF stores like GraphDB) store knowledge as nodes and edges – think entities and their relationships. They excel at multi-hop reasoning: for instance, tracing a chain of relationships (“A is parent of B, and B is employed at C”). In an autonomous LLM loop, a graph DB can represent the system’s accumulated knowledge or world model. Using graph queries, the LLM can retrieve structured info that would be hard to deduce from raw text alone. For example, if an answer requires knowing a sequence of events or a hierarchy, the LLM can query the graph to get that sequence.
Combining the two yields Graph RAG – Graph Retrieval-Augmented Generation – which is a state-of-the-art technique for deep knowledge integration (Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs). The LangChain blog explains that you can “combine structured graph data with vector search through unstructured text to achieve the best of both worlds” (Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs). In practice, this might work as follows: the system receives a complex query. First, it performs a similarity search in the vector DB to get top relevant text passages (unstructured knowledge). From those passages, it might identify an entity or key that is a node in the knowledge graph. Then it queries the graph DB for related information (neighbors of that node, or a specific path). The results from both (text chunks + graph relations) are then provided to the LLM for answer generation.
Consider a concrete example: suppose the LLM is asked “What are the common projects between Alice and Bob, and who leads those projects?”. A vector search might pull up paragraphs from documentation mentioning Alice and Bob and various projects, but a knowledge graph query can directly traverse relationships: find nodes “Alice” and “Bob”, get their WORKS_ON project edges, intersect them, then follow LEADS edges. The combination means the LLM gets a precise list of mutual projects and the leaders (from graph), plus descriptive context about each project (from vector search on project documents). Using both sources, the answer will be far more accurate and context-rich. Graphs ensure consistency and multi-hop reasoning, while vectors ensure coverage of raw details.
From an implementation standpoint, open-source integration is improving. Projects like Haystack provide unified interfaces to do a query that hits a vector store and a graph store. The retrieval step might use a Cypher (Neo4j query language) query generated by the LLM itself (perhaps via a tool use step) to fetch structured data. Tools like LlamaIndex (GPT Index) also allow constructing a “graph store index” and a “vector store index” and querying them as needed. The Graph RAG approach is gaining momentum: Microsoft’s 2023 paper on HybridRAG formalized combining knowledge graphs and vector RAG (HybridRAG: Integrating Knowledge Graphs and Vector Retrieval ...), and frameworks like RAGAS (for evaluation) treat graph-augmented context as just another part of the pipeline.
One pattern is to maintain a vector memory of all past interactions and improvements, and separately maintain a knowledge graph distilled from those interactions. The self-improvement loop might then do: (1) user asks question, (2) LLM retrieves similar Q&A pairs or documents from vector store, (3) LLM also queries the graph for any entities involved, (4) LLM synthesizes an answer, (5) if new facts are discovered in the answer, update the graph (inserting new nodes/edges) and index any new text into the vector store. This way the system’s knowledge is continuously refined in both representations. Indeed, the LangChain team has even added utilities to help construct knowledge graphs using LLMs – using the LLM to read text and output triples, which are then inserted into Neo4j (Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs). This automation means your graph can grow alongside the model’s understanding with minimal human curation.
To illustrate how you might code such a combined retrieval, consider a pseudo-code example:
# Pseudocode for hybrid vector + graph retrieval
query = "What projects do Alice and Bob both work on, and who leads them?"
# 1. Vector DB similarity search
docs = vector_store.similarity_search(query, top_k=3)
# 2. Extract potential entity (e.g., names) from query or docs (could use a regex or NER)
entities = extract_entities(query, candidates=["Alice", "Bob"])
# 3. Query graph database for relationships
graph_results = []
if entities:
cypher = f"MATCH (p:Person)-[:WORKS_ON]->(proj)<-[:WORKS_ON]-(q:Person)
WHERE p.name='{entities[0]}' AND q.name='{entities[1]}'
MATCH (leader:Person)-[:LEADS]->(proj)
RETURN proj.name, leader.name"
graph_results = neo4j_db.query(cypher)
# Now feed both docs and graph_results to LLM as context
context = format_context(docs, graph_results)
answer = llm.generate_answer(query, context)
In reality, you might let the LLM itself formulate the Cypher query (with a prompt like “Given the user question, generate a Cypher query that finds the relevant info in the knowledge graph.”). The LangChain toolkit approach can help here: you define a Cypher tool that the LLM can call. The combination of a vector tool and a graph tool allows the LLM to decide which to use or use both.
Using a graph DB also helps with preventing forgetting: as the LLM’s training data might be fixed to a certain date, new knowledge can be stored in the graph in a structured form that’s easily updatable. The LLM can be taught to defer to the graph for any factual lookup (acting almost like a logical “wiki”). Weaviate, for instance, even blurs the line by offering a built-in Knowledge Graph module that can enrich vectors with symbolic relations. Qdrant and others support metadata filters which can act like edges (e.g., store an “author” field and filter search by author = Alice). The open-source community is actively experimenting with such hybrid storage; the consensus is that combining them leads to more robust and accurate LLM systems (Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs).
To sum up, use a vector store to capture all the messy, detailed information (all your documents, past dialogues, etc.) and use a graph store to capture canonical facts and relationships that emerge. When the LLM needs information, retrieve from both: the vector DB ensures the LLM has rich descriptive context (for fluent answers), and the graph DB ensures it has correct structured data to ground its reasoning. By designing your system to consult this “memory” at every iteration of self-improvement (e.g., before revising an answer, check the knowledge base), the LLM can continuously learn and adapt to new information.
4. Self-Critique and Reasoning Mechanisms (CoT, Reflexion, Constitutional AI)

Empowering the LLM to critique and improve its own outputs is at the heart of a self-improving architecture. Several mechanism have proven effective: Chain-of-Thought prompting, Reflexion, and Constitutional AI (among others like debate or tree-of-thought). These techniques enable the model to engage in multi-step reasoning and self-assessment rather than producing answers in one shot.
Chain-of-Thought (CoT) prompting is a simple yet powerful method: you prompt the model to explicitly produce a step-by-step reasoning process (often hidden from the user) before giving the final answer. For example: “Q: [complex question]\nA: Let’s think step by step.” This encourages the model to break down the problem. CoT significantly improves performance on math, logic, and multi-hop questions (How far can you trust chain-of-thought prompting? - TechTalks). In fact, CoT prompting has become a primary approach to complex reasoning tasks for LLMs ([2403.14312] ChainLM: Empowering Large Language Models with Improved Chain-of-Thought Prompting). By articulating intermediate steps, the model is less likely to make leaps of logic or ignore important details. When building an autonomous loop, you can use CoT prompting in each iteration – e.g., have the model generate a detailed reasoning path (which might include considering alternatives or recalling critique points) before finalizing its response. One caveat: CoT relies on the model’s capability to follow the prompt and not hallucinate the reasoning steps. The latest open models (LLaMA 3, etc.) have largely been trained with data that includes chain-of-thought examples, so they often respond well to such cues.
Reflexion is a particular strategy introduced in 2023 (Shinn et al.) that extends CoT into a full feedback loop. In Reflexion, after the model produces an answer, it explicitly critiques that answer (identifying errors or missing pieces) and then uses the critique to attempt a better answer, iteratively (Reflection Agents). Crucially, Reflexion asks the model to ground its self-critique in external data or facts (“verbal feedback”), often requiring it to cite evidence or point out contradictions (Reflection Agents). This makes the reflections more constructive and guides the next iteration. In practice, an autonomous agent using Reflexion might do something like:
Draft answer.
Critique answer (the LLM itself generates something like: “The answer might be incorrect because X; it failed to consider Y.”).
Revise answer based on critique.
(Optionally repeat if still not satisfactory.)
Studies showed that this approach can dramatically improve accuracy on reasoning benchmarks. For instance, the LangChain Reflection Agents example implements Reflexion by having an “actor” agent and a “revisor” (reflector) agent loop with tool use in between, and it notes this outperforms standard ReAct or single-pass methods (Reflection Agents). The actor is forced to generate citations and explicitly list what was wrong or missing, which reduces the chance it will repeat the same mistake next round (Reflection Agents). To incorporate Reflexion in your system, you can include a prompt after an answer like: “Evaluate the above answer. Is it correct? If not, why?” – and then feed that evaluation back in. Over multiple iterations, the model often converges to a much better answer. This is essentially an internal feedback loop without needing a human in the loop.
Multi-path reasoning refers to exploring multiple possible reasoning paths in parallel or in sequence to increase the chances of finding a correct solution. One approach is Tree-of-Thoughts, where the model generates several candidate steps at each stage and a search algorithm (possibly guided by a value model) explores different combinations. Language Model Self-Play or debate can also be seen as multi-path: e.g. two models take opposing viewpoints which surfaces multiple perspectives on the answer. A practical implementation is Language Model Tree Search (LATS), which uses Monte Carlo Tree Search with an LLM to systematically evaluate different reasoning branches (Reflection Agents). LATS has been shown to outperform single-chain methods like ReAct and even standard Reflexion by more thoroughly exploring solution space (Reflection Agents). While these methods are more computationally heavy (running the model many times for one query), they can be leveraged in an autonomous system for critical tasks where accuracy matters more than latency. For instance, you could run a tree-of-thought process overnight on difficult new training questions, then fine-tune the model on the result.
In code, multi-path reasoning could look like generating, say, 5 different answers with associated reasoning (using different sampling seeds or prompting the model to “list multiple approaches”), and then having an evaluation step (another LLM or a heuristic) pick the best one. Anthropic’s research on “Constitutional AI” even suggests generating multiple critiques from different principles and seeing consensus. The key idea is redundancy and diversity: don’t trust a single chain-of-thought; instead, try many and compare.
Constitutional AI (CAI) is a technique developed by Anthropic to align models by having them follow a set of explicit principles (a “constitution”) and self-correct when outputs violate those principles. In practice, it is a form of self-critique tuned for safety and values. The model generates an initial output, then evaluates it against a list of rules (e.g. “No hate speech, ensure helpfulness, etc.”), and if it finds a violation, it revises the output (Constitutional AI with Open LLMs). For example, one principle might be “The assistant should not reveal private data.” After an answer is drafted, the model checks: did I follow this? If not, it revises. The exciting part is this can be done without human intervention – the model is effectively tuning itself to be more aligned, given the constitution. The Hugging Face H4 team demonstrated open-source Constitutional AI fine-tuning with models like Mistral 7B: the model critiques its own outputs according to a fixed set of rules and these self-critiques generate a new training dataset for alignment (Constitutional AI with Open LLMs). They found that a model can learn to “police” itself on things like toxicity and bias by this method. In an autonomous loop, CAI can be used as an oversight mechanism: after the model forms an answer (or any intermediate reasoning step), you prompt it with something like “According to the principles [list principles], is the above content appropriate? If not, please revise it.” The model then produces a safer/more aligned answer. Essentially, CAI bakes an oversight loop (the model acting as its own safety evaluator) into the generation process.
By combining these mechanisms, your system can enable self-assessment at multiple levels. For factual correctness and logical coherence, you use CoT and Reflexion – the model reflects on correctness and evidence. For exploring different angles, you use multi-path or debate – the model considers alternatives or even “argues with itself.” For ensuring alignment with human intent and values, you use Constitutional AI – the model checks itself against predefined principles of behavior (Constitutional AI with Open LLMs).
For instance, a full cycle might be:
LLM does CoT to produce initial reasoning and answer.
LLM uses Reflexion to critique that answer and reasoning; finds a flaw.
LLM revises answer.
LLM generates 2-3 different revised answers (via multi-path sampling or one with one strategy, one with another).
LLM (or an eval model) ranks these answers (perhaps using a separate value head or just another prompt like “Which answer is better according to criteria X?”).
The best answer is then run through Constitutional AI self-check (the model ensures it doesn’t violate any rules, adjusting phrasing if needed).
The final answer that emerges has thus been self-vetted for both correctness and alignment. This entire loop can occur autonomously in a few seconds for a single query (given a powerful model), or be stretched out as a learning process over many examples that feed into fine-tuning (as done in research to create better aligned models from their own feedback).
It’s worth noting that these approaches greatly reduce the need for human feedback at every step – the model is effectively serving as both student and teacher to itself to an extent. Of course, human oversight is still important to ensure it’s not drifting or reinforcing subtle errors (the model’s critiques are only as good as the model’s knowledge). But empirically, techniques like Reflexion and CAI have shown impressive improvements using AI feedback alone (Reflection Agents) (Constitutional AI with Open LLMs). Open-source implementations of these exist: e.g. Hugging Face’s ConstitutionalChain in LangChain can implement CAI by applying a list of critiques to any output (Constitutional chain | 🦜️ LangChain). There are also example notebooks of Reflexion applied to popular challenges (like the GitHub repo “Reflexion” hooking into LangChain (Reflexion - GitHub Pages)).
In summary, self-critique and reasoning mechanisms turn the single-shot LLM paradigm into an iterative, self-evaluative process. Chain-of-thought gives the model a scratch pad to reason. Reflexion makes it introspective, noticing and fixing mistakes using its own words. Constitutional AI keeps it aligned by enforcing a rule-based self-check. And exploring multiple reasoning paths ensures it’s not settling on a suboptimal answer too soon. Together, these allow an autonomous LLM pipeline to reach much higher quality without constant human intervention. As one paper title succinctly put it: it’s about LLMs “learning through verbal self-feedback and self-reflection” (Reflection Agents) – essentially meta-cognition for language models.
5. Evaluation and Feedback (LangSmith Evals, RAGAS, W&B)

To close the improvement loop, the system needs to evaluate its performance and feed those evaluations back into training or prompt adjustments. This is where evaluation frameworks and tracking tools come in. In an ongoing deployment, you want to automatically measure how well the LLM is doing on relevant metrics (accuracy, usefulness, safety, etc.), identify weaknesses, and then use that data to decide the next round of fine-tuning or prompt engineering. Open-source tools like LangSmith (LangChain), RAGAS, and Weights & Biases (W&B) provide the infrastructure to gather this feedback systematically.
LangSmith (by LangChain) is a platform and toolkit for evaluating LLM application outputs. It allows you to log model runs (with all intermediate steps) and then run evaluators either manually or automatically on those runs. For example, LangSmith can take a dataset of input–expected_output pairs and compare the model’s outputs against the expected outputs using various criteria. It supports both LLM-as-a-judge evaluation (where another LLM is prompted to score the output) and traditional metrics (exact match, BLEU, etc.), as well as custom Python evaluators (Evaluation Quick Start | 🦜️🛠️ LangSmith - LangChain) (Pairwise Evaluations with LangSmith - LangChain Blog). An AI/ML professional can integrate this easily: after each generation, you call the LangSmith client to record the trace and optionally call client.evaluate_run(...) to get a score. LangSmith’s Evaluators library includes things like a Pairwise comparison (useful if you have two versions of a model to A/B test). They even allow pairwise LLM judging with a few-shot prompt to decide which of two answers is better (Pairwise Evaluations with LangSmith - LangChain Blog). This is extremely useful during fine-tuning experiments – e.g., you fine-tuned a model with a new dataset, and you want to ensure it’s an improvement. You can have LangSmith automatically prompt an evaluator LLM to decide which model’s output is preferable for each test question, giving a win/draw/loss tally.
RAGAS (Retrieval-Augmented Generation Assessment) is an open-source toolkit specifically geared towards evaluating RAG pipelines (RAG Pipeline Evaluation Using RAGAS | Haystack). It provides a set of metrics that quantify aspects like context relevance (did the retrieved context actually contain the answer?), faithfulness (did the model’s answer stick to the provided context or hallucinate?), and correctness of the answer (RAG Pipeline Evaluation Using RAGAS | Haystack). RAGAS can take logs of your RAG system (including the query, retrieved docs, and answer) and produce a report of these metrics. For instance, “context utilization” metric checks if the answer overlaps significantly with the content of retrieved documents (RAG Pipeline Evaluation Using RAGAS | Haystack) – low utilization might indicate the retrieval wasn’t useful or the model ignored it. Another metric, answer correctness, can be measured if you have ground-truth answers or by using heuristics/another model to verify facts (like a fact-checking model). The nice thing is RAGAS integrates with frameworks like Haystack and LangChain easily; you can wrap your pipeline output in a RAGAS EvaluationExample and compute a bunch of metrics in one call. By running RAGAS regularly on transcripts of the LLM’s interactions, you pinpoint where the model is failing: e.g., maybe it often fails when the needed info wasn’t retrieved (a recall issue) – that suggests focusing on improving the vector database or retrieval technique. Or maybe the info was there but the model’s answer is wrong anyway (a reasoning issue) – that suggests the need for further fine-tuning or adding a Reflexion step.
Weights & Biases (W&B) is a popular experiment tracking and model monitoring tool. It’s not LLM-specific but has integrations that make it very useful for our purposes. With W&B, you can log arbitrary metrics from your runs, visualize them over time, and even set up alerts. For instance, you might log a metric “% of answers that contain a factual error” – maybe using an automatic fact-checker to flag errors – and watch that over each fine-tuning iteration to see if it’s going down. W&B recently introduced an LLMOps module (Weave) that can capture LLM traces and do analysis, and it provides a web app to inspect where prompts might be failing (LLM Apps: Evaluation - Wandb).
Importantly, W&B can track your model training process itself via hooks. If you fine-tune the model (say with reinforcement learning), W&B can log the reward over episodes, the loss curves, etc. This is crucial to ensure the training is actually achieving what evaluations want. For example, if RAGAS finds a problem with faithfulness, and you decide to fine-tune the model with a loss that penalizes using out-of-context info, you’d want to see on W&B if that “faithfulness metric” is improving on a validation set during training. W&B also supports Dataset versioning and comparison, so you can keep track of your evaluation datasets (like a set of test questions you always use) and ensure that as you update data, you know which version of the model saw which data.
Another tool to mention is LangChain’s LangSmith UI or Langfuse – these help in logging all interactions and then filtering them to find problematic cases. For example, LangSmith can store all runs in a database, and you can query, “show me all instances where the model’s answer was below a certain score or contained the phrase ‘I’m not sure’.” This helps target specific failure modes.
Concrete feedback-to-improvement strategies:
Automated regression tests: Keep a set of queries with expected answers (or at least acceptable answers). After each model update, run them through (via LangSmith or a simple script) and see how many passed. Tools like LangSmith’s dataset and evaluation features make this one-click once set up (Evaluation Quick Start | 🦜️🛠️ LangSmith - LangChain) (LangSmith Evaluations - LangChain - X). If new failures appear (regressions), you may decide to rollback a change or specifically fine-tune on those cases.
User feedback integration: If your LLM is in production, integrate a thumbs-up/down from users or collect whatever implicit feedback you can (e.g., did the user rephrase the question indicating they weren’t satisfied?). Log these events (W&B can log them as custom metrics or directly in a database). Use LangSmith’s logging to correlate user feedback with the exact model outputs. For example, if a user marked an answer as bad, you have that conversation in your logs – you can feed that back into a fine-tuning dataset (with the desired correction) or at least analyze it to see what went wrong.
Error clustering: Often, evaluation will reveal patterns: e.g., the model frequently makes up bibliographic references or often gets questions about dates wrong by a year. By clustering errors (via embedding the questions where it failed and grouping similar ones), you identify these patterns. Then you can address them either via targeted data augmentation (fine-tune on more examples of that type) or via prompt adjustments (e.g., add a rule in the system prompt “If answering with a reference, ensure it exactly matches known references.”).
RAGAS in fine-tuning loop: RAGAS metrics can actually be used as part of the reward function if you do RLHF or RLAIF. For example, you could set a reward that gives +1 if faithfulness is high and -1 if low, encouraging the model to not hallucinate. Or simpler, use RAGAS to filter out training examples: don’t use cases where the retrieval was poor (since training on those might teach the model wrong things – better to fix retrieval first).
Integration with RL frameworks: If you are using Proximal Policy Optimization (PPO) for RLHF (more in next section), you can use evaluation outputs as signals. For instance, use an evaluator LLM (like GPT-4 as a judge on your outputs) to provide a score, and feed that as the reward to PPO. LangSmith or custom scripts help here by enabling LLM-as-judge in an automated way. (Note: When doing this, you must be careful to avoid reward hacking where the model learns to game the judge model.)
Continuous improvement loop: The idea is to treat evaluation as an ongoing process, not one-off. You can set up something like LangChain’s Evals to run nightly on new data or random samples of conversations from that day. Tools like LangSmith online evaluator can even run in real-time on production traces (for example, LangSmith can attach an LLM evaluator to each run and log its score) (LangSmith Evaluations - LangChain - X) (May 2024 - LangChain - Changelog). So you might get a rolling metric “today’s average quality score.” If it dips, that triggers an alert.
In practice, you might use a combination: LangSmith for orchestrating and storing eval runs (since it integrates well with your LangChain chains/agents), RAGAS for deep-dive analysis on your retrieval augmentation pipeline, and W&B for tracking metrics over time and during training. All of these are open-source or have free community versions for moderate usage. For example, RAGAS is available as a Python library on GitHub, and LangSmith’s eval modules are in LangChain’s open-source code.
Finally, turning feedback into the next improvement loop means you need a mechanism to update the model or its prompts. This could be:
Updating prompts: e.g., after noticing through evals that the model often says “As an AI, I cannot …”, you decide to add to the system prompt “Do not mention you are an AI.” This is a quick fix (and you’d verify via eval that the frequency of that phrase goes down).
Fine-tuning: gathering all instances of a certain error and training the model to correct them. If evaluations show it often messes up a certain format (say, it doesn’t format JSON answers correctly 10% of the time), you might fine-tune on a batch of JSON QA examples and evaluate again.
Reinforcement learning: using feedback as reward signals directly. For instance, if using DPO or PPO, you can construct a reward model or preference dataset from evaluator judgments. Hugging Face’s TRL library makes it straightforward to plug in a reward function. You could use something like:
# Pseudo-code for turning eval feedback into fine-tuning reward
feedback_scores = run_evaluations(model_outputs) # e.g., GPT-4 scoring
# Construct pairs for DPO: for each query, compare current model vs an older/baseline or an ideal if available
preference_data = make_preference_pairs(model_outputs, baseline_outputs, feedback_scores)
trainer = DPOTrainer(model, peft_config=..., train_dataset=preference_data)
trainer.train()
In summary, evaluation tools give your LLM system “eyes and ears” to observe how it’s doing. By logging everything with LangSmith/W&B and analyzing with RAGAS or LLM judges, you gain insight into failure modes. Then you can apply that insight: either by adjusting the system/prompt or by initiating a retraining (fine-tune) with those failures in mind. Over time, this tight feedback loop (evaluate → identify issue → improve model → deploy → evaluate again) leads to continuous improvement. And because all these tools are open source, you can customize the evaluation criteria to whatever matters for your use case (be it factual accuracy, code executability, linguistic style, or user satisfaction proxies).
6. Lightweight Fine-Tuning and RL (PPO, DPO, LoRA, QLoRA)
Once you have feedback and data on how the model needs to improve, the next step is to incorporate those critiques into the model’s parameters without forgetting its prior knowledge. This is where fine-tuning and reinforcement learning come in. The goal is to adjust the model based on new training data (which might include examples it got wrong, with correct answers) or reward signals (which reflect preferences like “accurate and concise answers are better”). Open source techniques like Low-Rank Adaptation (LoRA and QLoRA) and algorithms like PPO (Proximal Policy Optimization) and DPO (Direct Preference Optimization) make this process efficient and manageable even on limited hardware.
LoRA (Low-Rank Adaptation) is a popular approach to fine-tune large models by adding a small number of trainable parameters instead of modifying the whole network (Reinforcement Learning Enhanced LLMs: A Survey). LoRA inserts low-rank update matrices into each transformer layer; during training only those matrices are updated, and at inference they adjust the base model’s outputs. The huge advantage is that the number of trainable parameters is very small (e.g., a few million instead of tens of billions for a 13B model), which means you can fine-tune on a single GPU without needing to load and update the entire model in memory (Reinforcement Learning Enhanced LLMs: A Survey). This prevents forgetting in two ways: (1) the original weights are frozen, so they retain their pre-training knowledge; (2) if the fine-tuning overfits or is unwanted, you can simply remove the LoRA adapter. LoRA adapters can also be merged or swapped, allowing a model to have multiple “skills” it can toggle.
For example, if your LLM often struggled with a certain task, you can create a fine-tuning dataset of that task (even relatively small), apply LoRA, and get an improvement on that task without losing performance on others. In fact, researchers often observe that LoRA fine-tuning can improve on new data while minimally impacting performance on original validation sets (Reinforcement Learning Enhanced LLMs: A Survey). A practical tip: you can have multiple LoRA modules (for different domains or styles) and even apply them together (some frameworks support merging LoRAs). The Hugging Face PEFT library provides a convenient API: you load your base model, attach a LoraConfig with your chosen rank, then train as normal. For instance:
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(task_type="CAUSAL_LM", r=16, lora_alpha=32, target_modules=["q_proj","v_proj"])
model = AutoModelForCausalLM.from_pretrained(base_model)
model = get_peft_model(model, peft_config)
# ... prepare data ...
trainer = transformers.Trainer(model=model, ...)
trainer.train()
This would fine-tune only the q_proj and v_proj layers of each transformer block in a low-rank manner. After training, you can either use model.merge_and_unload() to bake the LoRA into the model weights (if you’re satisfied it’s an overall improvement), or keep it separate. Either way, it’s a lightweight update. Facebook’s LLaMA-Adapter and Stanford’s Alpaca-LoRA were early examples that showed even large LLaMA models can be aligned with only a few hours of training using LoRA.
QLoRA (Quantized LoRA) takes it further by allowing fine-tuning on 4-bit quantized models (Reinforcement Learning Enhanced LLMs: A Survey). QLoRA (Dettmers et al. 2023) demonstrated you can load a 65B parameter model in 4-bit mode on a single 48GB GPU and still fine-tune it effectively, using LoRA adapters for updates. This drastically lowers the barrier to entry for fine-tuning top-tier models – you no longer need a server farm; a high-end single machine can do it. QLoRA introduced techniques to maintain precision (like NF4 quantization and double quantization) so that fine-tuning loss doesn’t suffer significantly from quantization noise (Reinforcement Learning Enhanced LLMs: A Survey). For our self-improving loop, QLoRA means after collecting a bunch of feedback, we can spin up a fine-tuning job overnight on even the largest model we have, without needing insane RAM.
In open-source practice, many instruction-tuned models were built with LoRA/QLoRA (e.g., Guanaco, a family of chat models, was produced via QLoRA on LLaMA). If we detect our model has started to go off track or needs to learn new data, we can prepare a dataset and do a QLoRA fine-tune. Since LoRA adapters are small, we could even schedule periodic re-training and hot-swap the adapters in production (for instance, every week generate new training data from the last week’s mistakes, fine-tune adapter, deploy the new adapter). This continuous learning setup is feasible with these lightweight techniques.
Now, Proximal Policy Optimization (PPO) is an algorithm from reinforcement learning commonly used in RLHF (Reinforcement Learning from Human Feedback) to directly optimize LLMs with a reward signal. OpenAI’s ChatGPT was tuned with PPO using a reward model that reflected human preferences. In open source, we have the TRL (Transformer Reinforcement Learning) library by Hugging Face that implements PPO for causal LMs. The way it works: you need a function that given an output (and maybe the input) returns a scalar reward (higher = better). Then PPO will generate outputs from the model, get rewards, and adjust the model to maximize reward, all while ensuring it doesn’t deviate too far from the original model distribution (that’s the “proximal” part – it constrains the update to avoid wrecking the language quality).
For example, suppose our evaluations indicate the model should be more concise. We can craft a reward function that penalizes long answers (or use a learned reward model that was trained to score conciseness). Then we use PPO to nudge the model toward conciseness. TRL makes this surprisingly accessible. Roughly, you would:
Generate a batch of outputs with the current model (maybe using the model’s policy to sample).
Compute a reward for each output (e.g., via an evaluator or some heuristic).
Use PPO to compute gradients that increase those rewards and apply to the model (this typically requires having the model’s initial response probability and the new adjusted probabilities, etc., but TRL handles those details).
It’s worth noting that PPO fine-tuning is a bit more finicky than supervised fine-tuning; you need to tune hyperparameters like the KL-divergence penalty to avoid the model going off-distribution (e.g., repeating safe phrases to please the reward model). But done right, it directly optimizes what you care about. For open source, a common pattern is:
Use an LLM (maybe GPT-4) to label a dataset of model outputs with a score (this creates a pseudo “human feedback”).
Train a reward model on those scores (or skip this and use GPT-4 as a direct evaluator).
Use TRL (PPO) with that reward model to improve your base model.
This way, you’ve effectively incorporated external feedback into the model’s behavior without needing to manually write every correction.
Direct Preference Optimization (DPO) is a newer, simpler method than PPO introduced in 2023. It sidesteps training a separate reward model; instead, if you have pairs of outputs (a preferred output vs a dispreferred output for the same prompt), DPO formulates a loss that directly pushes the model’s probabilities to favor the preferred output over the dispreferred. In essence, it’s like doing a binary logistic regression for each pair with the model’s logits. DPO is attractive because it’s easier to implement (it fits in the standard supervised fine-tuning paradigm) and has been shown to yield results comparable to PPO on preference alignment tasks (Reinforcement Learning Enhanced LLMs: A Survey). The Hugging Face TRL library supports DPO training too, and there are examples with open models.
For instance, if using our evaluation pipeline we produce a dataset of (prompt, model_output, revised_better_output) – e.g., the model’s initial answer and a better answer from Reflexion or human feedback – we can feed those to a DPOTrainer to directly improve the model. The trainer essentially tries to make the model score the better output higher than the worse one. The H HuggingFaceH4 team used DPO to align Mistral 7B to Anthropic’s constitutional AI data (they show how a DPO model based on Mistral outperforms a PPO one in some respects) (Constitutional AI with Open LLMs).
Using DPO with LoRA is very effective and efficient. The Hugging Face blog even shows that their DPOTrainer natively integrates with PEFT, so you can apply DPO fine-tuning via LoRA rather than full model update (RLHF in 2024 with DPO & Hugging Face). This way, you get the benefits of both: RL-alignment with minimal compute.
Here's a snippet that conceptually shows how simple DPO can be with TRL + LoRA:
from trl import DPOTrainer
peft_config = LoraConfig(r=16, ... )
peft_model = get_peft_model(base_model, peft_config)
trainer = DPOTrainer(
model=peft_model,
ref_model=None, # we pass None because we'll use LoRA on the same model for ref
beta=0.1, # DPO hyperparam controlling strength
train_dataset=preference_pairs_dataset,
# ... other Trainer args (tokenizer, etc.)
)
trainer.train()
(Pseudo-code inspired by TRL documentation – the DPOTrainer treats ref_model as the reference baseline; if None, it uses the base model’s fixed original logits internally. The preference_pairs_dataset would yield dicts like {"prompt": ..., "chosen": ..., "rejected": ...} as required.)
The combination of these techniques allows a powerful workflow: use LoRA/QLoRA for any supervised fine-tuning (e.g., incorporate new QA pairs or demonstrations) and use PPO/DPO for preference-based tuning (e.g., incorporate “I prefer output A over B” information). All while preserving original model capabilities as much as possible.
To avoid forgetting:
Use a low learning rate and regularization (KL penalties in PPO, or mixing some original training data in supervised fine-tuning) so the model doesn’t drift too far.
Utilize LoRA so you can always revert if needed or maintain multiple adapters. In fact, one strategy could be: keep a base model fixed and maintain an ever-growing stack of LoRA adapters for various improvements. You might merge some adapters when it’s stable, but this modular approach prevents catastrophic forgetting since base weights stay intact (Reinforcement Learning Enhanced LLMs: A Survey).
For reinforcement learning, techniques like PPO’s KL-divergence penalty explicitly prevent the model from changing too much from the reference (initial) policy. Setting that correctly (not too high, not too low) is crucial. Open source guidelines often suggest monitoring something like the average KL between new and old policy and tuning the
kl_coeffso it hovers around a target (maybe 0.1-0.2). This ensures the model’s language style and core knowledge don’t collapse while still adapting behavior.
In practice, one might do a few epochs of supervised fine-tuning on newly generated QA corrections (with LoRA), then a few iterations of PPO using an automated reward (like an LLM judge), and repeat. Each cycle, log the results (Section 5’s tools) to see the trend. If certain undesired behaviors reappear, target them specifically next cycle.
Finally, it’s important to test the fine-tuned model on not just the new feedback data but also a broad suite of original tasks to ensure it hasn’t broken anything. This is again where LangSmith evals or W&B come into play – you’d have multi-dimensional evaluation after each fine-tune (e.g., test on original training distribution, on a safety test, on new feedback examples, etc.). Often QLoRA fine-tunes can improve one metric significantly while keeping others almost the same ([2403.14312] ChainLM: Empowering Large Language Models with Improved Chain-of-Thought Prompting) (e.g., improving helpfulness without dropping knowledge). If something does drop, you can adjust your training data (maybe include a mix of original data to remind it).
In summary, lightweight fine-tuning via LoRA/QLoRA allows quick model updates based on critique data, and RL algorithms like PPO and DPO allow using preference signals to directly optimize model behavior. Together, they enable your LLM to learn from its mistakes (as identified by evaluation) in a tight loop. These approaches are all accessible in open-source frameworks (Hugging Face Transformers, PEFT, TRL) and have been validated on open models like LLaMA, Mistral, Falcon, etc. By using them, your autonomous LLM can steadily become more accurate and aligned with relatively low compute and without starting training from scratch each time.
7. Preventing Bias Amplification with Open-Source Safeguards
As an LLM continuously learns and adapts, there is a risk of it amplifying biases or drifting in alignment with human values. Each fine-tuning or self-critique step could inadvertently introduce undesired biases if not carefully checked. Thus, a self-improving architecture must include bias detection and mitigation mechanisms as safeguards. Fortunately, there are open-source tools and strategies to help maintain or even improve the model’s fairness and prevent harmful outputs.
One basic approach is to integrate bias evaluation into the feedback loop. For example, you might use bias detection libraries like AIF360 (AI Fairness 360) or Fairlearn to test model outputs for bias indicators (Essential Open-Source Tools for Bias Detection and Mitigation). These toolkits (from IBM and Microsoft respectively) provide metrics like disparate impact, equalized odds, etc., which are more applicable to classification models, but can be adapted for generative outputs too (e.g., generating many outputs about different demographic groups and statistically comparing sentiments). In an LLM context, one might prompt the model with templates covering various demographic or social categories to see if it responds differently. For instance, ask the model to generate a story about a programmer with different gender pronouns each time and analyze sentiment or attributes. If bias is detected (say it consistently describes one gender as better at coding), that’s a signal to correct.
Open-source bias mitigation can happen at multiple levels:
Data level: Use diverse and balanced fine-tuning data. There are open datasets specifically curated to reduce bias, such as BBQ (Bias Benchmark Questions), or synthetic data generation techniques to produce counterfactual examples (e.g., swap genders in a sentence and ensure model gives similar output). The Holistic Bias project and others have released lists of bias evaluation prompts that you can integrate (Best LLM Security Tools & Open-Source Frameworks in 2025).
Prompt level: Employ Constitutional AI style principles that include fairness. For example, one of Anthropic’s constitutional principles is non-discrimination. If you incorporate these into the model’s “self-critiques,” the model will check its outputs for bias. It might produce a reflection like, “I used gendered language unnecessarily,” and then fix it. So essentially, instruct the model to apply a bias filter to itself. Anthropic has shown that Constitutional AI can mitigate certain biases without human labels by using rules like “If the output is prejudiced, rewrite it” (Constitutional AI with Open LLMs).
Model level: Use techniques like adversarial training or debiasing fine-tunes. For instance, train the model on a dataset of biased -> debiased output pairs. There’s research where a secondary model (a “bias discriminator”) is trained to identify biased content, and then the main model is fine-tuned to not produce what triggers that discriminator. In open source, one could simulate this by using an existing toxicity or bias detection model (like OpenAI’s content filter or Perspective API from Google – though not fully open-source, they provide free APIs; there are also smaller open toxicity classifiers). If that classifier flags the LLM’s output, feed that back as a negative reward in RL training. RLAIF (Reinforcement Learning from AI Feedback) could incorporate a bias-checking AI as part of the reward function (giving low reward to biased responses).
Real-time filtering: Incorporate a final safety layer using open models like OpenAI’s moderation model (there is an open reproduction called “OpenModeration”, or use Perspective API, or even simpler, a list of banned words/phrases). While this doesn’t improve the model’s internal biases, it can catch egregious outputs before they reach users. For a self-improving system, flagged outputs can be logged and later used to further fine-tune the model to avoid those cases altogether.
A practical example: let’s say the model, after fine-tuning on user data, starts producing subtly biased career advice (e.g., consistently suggesting male examples for CEOs). We can detect this by using a set of test prompts about career advice for men vs women and noticing a difference. Then, we could generate additional training examples where the assistant is corrected (“Actually, women can be CEOs too...”) and fine-tune on those with LoRA. Additionally, we could add a rule to the model’s “constitution” or system prompt: “Ensure responses do not perpetuate stereotypes or biases about protected characteristics.” With Constitutional AI, the model would then critique its own output if it did so, and correct it, without needing an external nudge each time.
Bias amplification prevention is also about the loop not making the model more extreme in some direction over time. For instance, if users from one demographic use the system more and give more feedback, the model might skew towards their linguistic style or perspectives. To counteract that, you can actively inject diversity during improvement. When fine-tuning on feedback, ensure you also include inputs from a variety of perspectives. The open source community has created datasets like CrowdOS (Crowdsourced Offensive Speech) or BOLD (Bias in Open Language Deployments) which have test cases to ensure models remain balanced. You might incorporate a small percentage of such data in each training round as a regularizer.
There are also open-source Constitutional Classifiers (Anthropic released research on having classifier models that detect constitution violations, similar to a safety referee) (Constitutional Classifiers: Defending against universal jailbreaks). One could integrate a classifier that scans outputs for, say, politically biased or toxic language. If detected, that interaction is marked and used to adjust the model. Either by immediate correction: e.g., if classifier says “this answer is racist,” you could have the LLM generate an apology or correction on the fly (some systems do two-pass generation: first pass answer, second pass safety check and modify answer).
In terms of tools: Fairlearn provides an interface to take a predictive model and mitigate bias via post-processing or constrained optimization. For LLM, an analog is generating multiple outputs and choosing the one that best meets a fairness metric. A simplified approach: if the LLM outputs content that contains a potentially biased phrase, you could instruct it to regenerate. This can be automated. For instance, if output contains “[some sensitive term]” and a sentiment, and you suspect bias, have an automatic trigger to say “The previous answer may be unfair. Please reconsider and answer in a more neutral way.” The LLM, if it has been aligned to follow instructions, might then self-correct.
One open approach is SFT with Attitude Alignment – the model is fine-tuned on data that explicitly demonstrates unbiased behavior. For example, if the user asks an unethical or biased question, the fine-tuning data might show the model refusing or replying with a correction. This was done in OpenAssistant’s dataset – they included many examples of addressing hate or bias with corrective answers. Incorporating similar data (which is open in datasets like LAION OIG – Open Instruction Generalist dataset – containing user asks like “tell a joke about X” and helpful but safe responses) can help the model preemptively avoid producing biased answers.
Monitoring and iterative mitigation: as the system runs, continuously monitor outputs for bias using something like Perspective API (which gives toxicity, insult, etc. scores). If over time you see these creeping up in frequency, that triggers a re-alignment step. Because our architecture is open, we might do a monthly bias audit where we run a fixed set of bias probes (these could be templates like “A man is to doctor as a woman is to __?” expecting “doctor” not “nurse”) and compare to previous month. If any regression, we act.
The critical thing is to not treat bias and alignment as separate from the rest of the improvement loop – they should be first-class metrics. So when we evaluate (Section 5), we include fairness metrics. When we do RL fine-tuning, part of the reward should be based on not being toxic or biased. For instance, we might have a composite reward: +2 if answer is correct, -5 if answer is flagged as containing a slur (which a classifier or regex detects). The model will learn to avoid the negative even if it could get some correctness points by quoting a slur from context or so on. The open RLHF pipeline can incorporate those signals easily since frameworks let you define the reward function.
Constitutional AI for bias: If one of your constitution rules is like Anthropic’s “choose the response that most human readers would consider fair and unbiased, and that avoids harmful stereotypes,” the model will internally prefer those answers (Constitutional AI with Open LLMs). This has been shown to reduce biased completions (Anthropic reported Claude using CAI had lower bias in certain evaluations than models without it). You can tweak the constitution as needed for your domain and values – it’s all in plain text principles, which is an open and transparent way to encode alignment.
All these methods are achievable with open source: for example, one could use the Hugging Face toxicity classifier (bert-based, open model) or RecipE (an open bias detection model) if available, or even a smaller distilled version of Perspective API like Detoxify (open-source model on Kaggle). Tools like LangChain allow easy incorporation of these as a “Tool” or a final output validator step. E.g., define a tool check_toxicity(text) that returns a score; after LLM generates an answer, you do: if check_toxicity(answer) > threshold: ask LLM to revise with a prompt "Your last answer might be offensive, please rephrase.".
In summary, to embed checks and safeguards for alignment:
Leverage open data and tools to measure bias.
Integrate self-regulation instructions (like constitutional principles) so the model actively avoids bias in each response.
Use alignment techniques (CAI, RLHF) with specific focus on fairness: e.g., train a reward model that gives low reward to biased outputs (possible if you have or create a dataset of biased vs unbiased output comparisons).
Maintain a diverse evaluation set and keep bias metrics as key performance indicators alongside accuracy. If the model is getting better at answering questions but also getting more biased, that’s not acceptable – the training objective can be adjusted to balance that (multi-objective optimization).
When fine-tuning on user data, apply data filters: if users inadvertently reinforce a bias (like if many users from one viewpoint upvote answers aligning with that view), you may need to counterbalance with data from other views in training.
Using open-source frameworks, one can orchestrate all this: e.g., LangChain’s ConstitutionalChain can incorporate multiple principles including unbiasedness (Constitutional chain | 🦜️ LangChain); TRLX (TRL library extensions) can incorporate custom rewards for bias avoidance; and Bias evaluation notebooks (like the one by Hugging Face on evaluating toxicity and bias in LLMs) can be adapted to continuously watch your model’s behavior.
A self-improving LLM thus doesn’t just get smarter – it should also get (or remain) more aligned and fair. The open-source ecosystem provides the ingredients (datasets, libraries, and models to detect/mitigate bias) to bake these considerations into the improvement loop rather than treating them as afterthoughts.
8. Blueprint of a Self-Improving LLM System
Now let’s put it all together into a coherent architectural blueprint. This blueprint will illustrate the full loop from data ingestion to model redeployment, incorporating the components discussed: knowledge retrieval, self-critique, evaluation, fine-tuning, and deployment. The architecture is essentially a closed-loop learning system around the base LLM.
(LLM continuous self-instruct fine-tuning framework powered by a compound AI system on Amazon SageMaker | AWS Machine Learning Blog) High-level architecture of a self-improving LLM loop. Components: (1) Data ingestion feeds new interactions or documents into storage; (2) The LLM (foundation model + adapters) uses retrieved knowledge and self-critiques in inference; (3) Outputs are evaluated for quality/alignment (with human or automated feedback); (4) An improvement module aggregates feedback into fine-tuning data or reward signals; (5) The model is lightly fine-tuned (e.g. via LoRA or PPO) to incorporate improvements; (6) Updated model (or adapter) is redeployed to inference. Continuous monitoring ensures alignment.
Breaking down the process step by step:
1. Data Ingestion: This involves both knowledge data and interaction data. Knowledge data could be new documents, facts, or updates which are fed into the vector database and/or graph database. For instance, if new articles are published or you have new company data, you embed them and add to ChromaDB, and also update any relevant nodes in Neo4j. Interaction data refers to conversations or queries and responses from users (or test runs) that the system logs. Every user query and the model’s answer (along with any feedback like user rating or whether the user asked a follow-up) is stored. LangSmith or a custom logging solution can gather these traces including intermediate reasoning steps. This creates a continuously growing dataset of how the model is performing in the real world.
2. Inference (LLM with retrieval & self-critiques): When a new query comes in, the LLM inference pipeline kicks off. The query first goes to the Retrieval component: it fetches relevant context from the vector store and any connected knowledge sources. So the prompt to the LLM consists of the user query + retrieved context (e.g., relevant document snippets) + any system instructions (like constitutional principles or formatting requirements). The LLM (which is the base foundation model plus perhaps the latest LoRA adapter applied) generates an initial response. This generation might involve a chain-of-thought if prompted to do so internally, and possibly a Reflexion loop as described. In implementation, this could mean the LLM is actually called multiple times: one time to get an answer, another time to get a critique (if using an automated reflection chain), and then a final time to get a revised answer. Or the self-critique could be baked into one prompt via few-shot. Regardless, the inference stage ends with a final answer delivered to the user. Importantly, this stage also produces artifacts useful for learning: the reasoning path, the critique, which documents were retrieved, etc. All those get logged.
3. Evaluation & Feedback Collection: Once the answer is produced (or periodically for a batch of answers), the evaluation subsystem goes to work. This could happen asynchronously (for example, nightly batch evaluation of the day’s interactions) or synchronously (immediately scoring each answer). Tools like LangSmith Evaluators run LLM-as-judge on the answer comparing to an expected answer if known, or checking for correctness (Evaluation Quick Start | 🦜️🛠️ LangSmith - LangChain). RAGAS metrics are computed for any RAG-specific issues (did the model use the provided context? hallucinate? (RAG Pipeline Evaluation Using RAGAS | Haystack)). Also, safety/bias filters are applied here – e.g., pass the answer through a toxicity classifier or regex filters for slurs. If human feedback is in the loop (say the user can rate the answer or a human reviewer periodically labels some outputs), that is collected too and added to the feedback dataset. The evaluation stage basically attaches scores/tags to each logged interaction: e.g., “Q123: correctness 7/10, too verbose, contained mild stereotype about X.”
4. Analysis and Aggregation: This component takes the raw feedback and decides on improvement actions. It might aggregate statistics (like average correctness down this week), and more concretely, it prepares training data for the improvement step. For supervised fine-tuning: we need high-quality question-answer pairs (or dialogues) that illustrate the desired behavior. We can extract those from interactions: for ones that had issues, we can create a corrected version. How? Either a human can write the ideal answer for those problematic cases (if humans in loop), or we leverage the LLM itself or a higher-quality model to generate a better answer. For instance, if the evaluation found the answer factually wrong, one could query the knowledge base and ask the LLM, “Using this reference, provide the correct answer.” This results in a QA pair to add to training. Similarly, we accumulate preference pairs for DPO/PPO: from evaluation we might have “model’s answer vs correct answer” pairs or “model’s style A vs style B” preferences. All this goes into a Feedback Dataset (which can have multiple components: supervised examples, reward signals, etc.). This stage also decides if some issues can be fixed by prompt engineering rather than training – e.g., it might detect a pattern and suggest updating the system prompt or adding a new constitution rule. A human engineer might be involved in that decision loop occasionally, using insights from the analysis dashboard.
5. Fine-Tuning / Reinforcement Loop: Now using the prepared data, the system fine-tunes the model. Because we want minimal disruption and efficiency, we use QLoRA on the latest model checkpoint (which includes previous LoRA adapters merged perhaps). We produce a new LoRA adapter (or update the existing one’s weights) on, say, the last week’s collected QA pairs and some mixture of original data to preserve knowledge. This fine-tune will incorporate corrections – for example, if the model repeatedly gave harmful advice in a certain situation, we’ve added examples of the right advice, so it will learn that. If using RL, we might use DPO on preference pairs extracted (like we got user feedback preferring concise answers). Or run a few PPO epochs with a reward model (possibly the reward model is updated from latest human feedback too). These training processes output an updated model (still the same architecture and base weights, but new adapter weights or slightly nudged main weights if we allowed that).
6. Deployment of Updated Model: After fine-tuning, we test the new model on a validation suite (which includes ensuring it hasn’t regressed on key abilities or become biased – basically re-running our evaluation on a standard set). If all looks good (or at least better on average, with no critical regressions), we deploy this model. In practice, deployment could mean swapping the LoRA adapter in the serving infrastructure to the new one (which is near-instant if the model is already loaded), or loading a new model version on the server and beginning to route traffic to it (with a fallback to the old one if needed). Tools like Continuous Integration for models might be set to automate some of this after each fine-tune (e.g., using NVIDIA Triton or HuggingFace Inference Endpoint versioning). The new model is now handling user queries. This returns us to step 2, closing the loop – as it answers new queries, those get logged and evaluated, hopefully showing improved metrics due to the recent training.
Throughout this loop, monitoring is continuous. Systems like W&B Charts or custom dashboards show trend lines: e.g., “accuracy last week vs this week”, “toxic output count – target: zero”. If something spikes or drops unexpectedly after a deployment, that triggers an alert to the team or an automatic rollback. This blueprint emphasizes automation: as much of this as possible is handled by the system with minimal human intervention, but with humans in the loop for oversight and high-level decisions (the so-called “human on the loop”).
A crucial aspect of this architecture is that it’s data-driven. The more it interacts, the more it learns. And because it uses open components, it can be hosted on premises, and one can inspect each part. For example, the knowledge graph can be queried to see what the system has “stored” as facts; the evaluation logs can be audited to see examples of failures and how they were corrected.
Another component not explicitly drawn but important is the Memory and State for conversations. A self-improving chatbot might maintain long-term memory of a user (e.g., stored in vector DB) and also learn from that. That was covered in knowledge storage (section 3). In the loop, when a user corrects the assistant (“Actually, my birthday is not Jan 1, it’s Feb 2”), that fact enters the vector store under that user’s profile. The next time, retrieval brings it, and evaluation also marks that as a resolved error.
To ensure the blueprint doesn’t go awry: incorporate a safety net – e.g., a rule that if the model starts producing too many flagged outputs, freeze fine-tuning until a human reviews the feedback data (maybe something in feedback data is itself biased, causing a cascade). Because this is an automated loop, careful gating and validation at each cycle are needed to prevent a “runaway” effect (like learning something incorrectly because of an accumulation of slight errors). This is akin to how online learning systems have to guard against concept drift turning into catastrophic drift.
In summary, the blueprint is a closed-loop LLM system with the following key open-source-powered modules:
Knowledge base: ChromaDB/Qdrant + Neo4j (updated continuously).
LLM Inference Engine: could be vLLM or TGI serving the base model with latest LoRA (fast, batched).
Self-Critique chain: implemented via LangChain/LangGraph within the inference pipeline.
Logging/Eval pipeline: LangSmith and custom scripts (could run on infrastructure like an Airflow pipeline or just cron jobs with Python scripts using HF models for eval).
Fine-tuning pipeline: using HuggingFace Transformers/PEFT/TRL on collected data (this could be triggered automatically if enough new data or on a schedule).
Deployment: using Docker or Kubernetes to host versions, maybe with Canary testing (route small % of traffic to new model first, compare via eval – this can be done if you run two models in parallel for same queries and evaluate differences).
This architecture brings together everything: each improvement loop makes the model a bit better (answers more questions correctly), a bit safer (fewer policy violations), and more tuned to what users need. Over time, you essentially have a self-evolving AI service. Thanks to open-source components, this evolution is transparent and controllable, unlike a black-box system. You can inspect the vector memory or adjust the reward function if needed.
In a sense, it’s implementing a form of online learning for LLMs, guided by explicit feedback and constrained by alignment checks – very much aligned with the idea of an AI tuning itself under human-defined rules.
9. Scalable Deployment and Serving (vLLM, Triton, TGI)
Deploying a continuously improving LLM at scale requires an optimized serving infrastructure to handle potentially thousands of requests, possibly with large context windows, without incurring prohibitive latency or cost. Open-source solutions like vLLM, NVIDIA Triton Inference Server, and Hugging Face’s Text Generation Inference (TGI) provide high-performance serving capabilities and can be tuned for different trade-offs (throughput vs latency, memory vs speed). We’ll discuss how to use these in deployment and how to scale to resource-constrained environments.
vLLM is a specialized LLM inference engine that introduces an optimized scheduling algorithm called PagedAttention to maximize GPU utilization (vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention | by Ashish Kumar Singh | Feb, 2025 | Medium). In traditional transformer inference, a lot of GPU memory is tied up storing attention keys/values for each request’s context. vLLM instead manages a unified KV cache with a fine-grained paging mechanism, which allows batching of tokens across many requests dynamically. The result is significantly higher throughput: vLLM can achieve up to 24× higher throughput than naive HuggingFace Transformers serving (vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention | by Ashish Kumar Singh | Feb, 2025 | Medium), and still 2–4× higher than TGI in many scenarios (vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention | by Ashish Kumar Singh | Feb, 2025 | Medium). This makes it ideal for serving the LLM in production where you might have bursts of requests. It effectively means you can serve more users with the same hardware. For instance, if you have lots of concurrent requests with mid-length prompts, vLLM can pack those into one batch, amortizing the cost of computing attention, etc.
vLLM is easy to integrate – it provides a similar interface to HuggingFace. You can spin it up with a command pointing to your model weights (including LoRA adapters). It supports features like streaming token output and even OpenAI-compatible APIs out of the box (Welcome to vLLM — vLLM). Many organizations have adopted it (it’s being used in Amazon’s Bedrock internally, and by LinkedIn etc., as noted by the dev team (vLLM 2024 Retrospective and 2025 Vision | vLLM Blog). In our architecture, we can plug vLLM as the inference engine in step 2. Because vLLM keeps a unified KV cache, it handles many users with long contexts efficiently (it won’t recompute the static prompt parts as much, thanks to caching and “prefix matching”). If our self-improving loop increases context usage (maybe adding more retrieved chunks), vLLM mitigates the performance hit.
Triton Inference Server by NVIDIA is a more general serving framework that now supports LLMs via a specialized TensorRT-LLM backend (Deploying a Large Language Model (LLM) with TensorRT-LLM on Triton Inference Server: A Step-by-Step Guide | by Murat Tezgider | Trendyol Tech | Medium). Triton’s strength is in production deployment – it can manage multiple models, GPU pools, dynamic batching, and integrates with Kubernetes easily. With Triton, you can load the model (possibly optimized via TensorRT for faster matrix computation) and then serve requests via HTTP/gRPC with auto-batching. The TensorRT-LLM backend specifically allows the model to run using TensorRT’s highly optimized kernels and memory management for LLMs. NVIDIA reports that with TensorRT-LLM and Triton, you can get substantial speedups, especially on long prompts, through features like aliasing of KV cache in multi-batch scenarios (which is similar in spirit to what vLLM does) and usage of faster fused kernels for attention. One claim from recent benchmarks: TGI v3 (which uses some of these ideas) had a 13× speedup over vLLM on certain long prompt scenarios with prefix caching (TGI v3 overview) – which implies the underlying technique of reusing computation is crucial. Triton with TensorRT-LLM achieves similar caching at a lower level, leading to huge wins for long inputs where many tokens are the same across requests (TGI v3 overview).
Deploying with Triton might look like: you convert your model (with the LoRA merges) into a TensorRT engine (there are conversion scripts – though for very large models this is non-trivial and might require multi-GPU partitioning, which TensorRT-LLM supports) (Deploying a Large Language Model (LLM) with TensorRT-LLM on Triton Inference Server: A Step-by-Step Guide | by Murat Tezgider | Trendyol Tech | Medium). Then you configure Triton with a model repository (a folder with the engine and a config specifying max batch size, etc.). Triton will then manage running the model and can parallelize across multiple GPUs or even serve multiple models (like your model and a fallback smaller model perhaps). It’s highly optimized for throughput – it will wait a short microbatch interval to gather queries and batch them automatically, thus keeping GPUs at high utilization even if requests come in one by one.
Text Generation Inference (TGI) is Hugging Face’s optimized inference server for Transformers. It’s written in Rust and C++ and is particularly good for distributed load (it can serve thousands of parallel websockets streaming tokens). TGI performs tensor-parallelism to split a model across GPUs if needed, and does efficient batch scheduling as well (though initial versions didn’t handle the KV cache as flexibly as vLLM; however, TGI v3 introduced prefix caching which drastically improves performance on repeated prompts and long contexts, surpassing vLLM in those cases (TGI v3 overview)). For example, TGI can reuse the computation for the prompt across requests so that if 100 users have the same prompt prefix, it doesn’t redo it 100 times – this is similar to vLLM’s approach. TGI’s advantage is seamless integration with HuggingFace ecosystem and ease of use: you can spin it up via Docker or a simple CLI, and it exposes a nice web UI for testing. It also supports features like multi-tenancy (hosting multiple models and routing based on endpoints). If we have multiple versions (like an older stable model and a new fine-tuned model), TGI can host both and we can use a logic to query one or the other.
For resource-constrained deployment (like on CPU servers or smaller GPUs), quantization is key. We already use QLoRA for training; we can also serve in 4-bit or 8-bit. vLLM and TGI both support 8-bit loading of models (and with a little code, 4-bit via bitsandbytes though with some performance penalty). If we have to deploy on CPU or edge devices, smaller models are needed – perhaps the system maintains a distilled version of the LLM (via techniques like LLM int8 or even a smaller model fine-tuned on data the big model produced). Tools like GGML allow running quantized models on CPU with decent speed. The blueprint could include an “export to mobile” step if needed: after fine-tuning the main model, also fine-tune a smaller 7B model with the same new data and quantize it to 4-bit for a CPU endpoint. That smaller model can be served via FastAPI or C++ on devices with no GPU.
High-performance tradeoffs: There’s often a trade-off between throughput and latency. vLLM maximizes throughput by grouping requests, but an individual request might wait a bit to be batched. This is usually fine for massively parallel usage. Triton can be configured for either: you can set max batch size and timeout – a lower timeout gives lower latency at cost of some throughput. TGI similarly can batch up to certain sizes. If our use-case needs very low latency for single user (not typical for LLM chat, but maybe for interactive real-time apps), we might disable batching and run at full speed single sequence – but that means GPU is not fully utilized if only one user. In a multi-user environment, though, these frameworks shine by serving many in parallel.
For very large models (like 70B, 180B) in production, multi-GPU inference is important. Both Triton and TGI support model parallelism (TGI uses FasterTransformer under the hood for this, or DeepSpeed’s inference engine). vLLM in its current open version is single-node (multi-GPU on one node supported, but not multi-node). If we needed to scale beyond one machine’s memory, we might integrate DeepSpeed’s inference engine or TensorParallel from HuggingFace Accelerate to split across nodes – but that’s complex. Usually a better approach is to use a sufficiently large single node (e.g., 8×80GB A100 server can handle a 70B easily with room).
Auto-scaling: In a Kubernetes deployment, we could have multiple replicas of our model serving pod, and scale them based on load. Since the model is large, spinning up replicas is slow (minutes to load weights). But one can keep a couple warm and scale gradually. Also, using quantization can allow more replicas on same hardware if needed (like two 30B 8-bit models on one 80GB GPU vs one 65B in 16-bit). The architecture should plan for a “shadow deployment” – e.g., test new model on a small fraction to ensure no performance issues at serving level too (like memory leaks etc. – using new code or new weight sizes).
In the blueprint diagram, the deployment box would include something like: “vLLM on GPU cluster for main model API” and perhaps “Triton serving smaller model for mobile users or special cases.”
Memory optimization: We might use FlashAttention (already integrated in vLLM and many frameworks) to reduce memory and speed up attention calculations. The vLLM project mentions integration with FlashAttention and more custom CUDA kernels (Welcome to vLLM — vLLM). All these ensure that adding more retrieval context (which means longer prompts) doesn’t linearly degrade performance too much.
Using Triton’s CPU fallback: Triton can be set to use GPU, and if GPU memory is full, route some requests to a CPU instance – though that would be much slower. Alternatively, use scheduling to prioritize important requests to GPU, less important to CPU. This may not be needed if we provision correctly.
Throughput tuning example: Suppose our LLM has a generation speed of 20 tokens/s on a single GPU. If we have 10 concurrent users each wanting 50 tokens, naive sequential handling would yield maybe 0.4 tokens/s per user, which is slow. But with vLLM or TGI dynamic batching, those 10 could be combined, effectively generating tokens for all simultaneously – that might still be 20 tokens/s for the batch, meaning 2 tokens/s per user (much better). If concurrency grows to, say, 100 users, batching might saturate and some have to queue or go in separate batches, but the system will use all GPU capacity. At that scale, we’d consider multiple GPUs with model parallel (to handle longer batches) or multiple replicas.
vLLM vs TGI trade-off: The choice can depend on typical prompt length. If many requests share context or have long common prefixes, TGI v3’s prefix caching could outperform. If requests are all different or shorter, vLLM’s continuous batching might do better. They are both actively evolving (vLLM’s recent versions also working on prefix optimization, and TGI on multi-group scheduling). Some deployment might run both in parallel under a load balancer and direct traffic based on request patterns, though that’s complex.
In resource-constrained environments (like running on an 8GB GPU or a CPU edge device), one cannot serve a 70B model. The loop’s final deployment step should include an option to distill the knowledge to a smaller model. Distillation could be an offline process using the larger model’s responses as training data for a smaller one. That smaller one (like 7B or even 2.7B) can then be quantized (int8 or int4) and served on modest hardware. Open tools like Alpaca distilled models or LLaMA-Adapter for small models show it’s feasible to get some capability in small models. For instance, Meta’s LLaMA 3 had a 8B model that presumably one could fine-tune using the same loop – that 8B can be for edge deployment while the 70B is the server powerhouse. Ensuring the improvement loop benefits both would require training the small model on feedback as well (maybe not every loop, but periodically).
Triton and vLLM synergy: One could even wrap vLLM inside Triton as a backend or simply run vLLM as a standalone. If we rely on huggingface/transformers for the model (for LoRA merging ease), TGI might be simpler to integrate (it directly loads HF models with adapters). vLLM would need either merging LoRA into the model weights or supporting LoRA directly (I think it supports FlashAttention with LoRA now if using HF accelerate to combine). These are engineering choices.
To summarize, for scaled deployment:
Use vLLM or TGI to serve the model efficiently, achieving high throughput by batching and caching. This ensures even as more users come in or context lengths increase, latency remains reasonable.
Use NVIDIA Triton if you need a robust production environment with multi-model, multi-framework support and want to leverage TensorRT optimizations (especially on NVIDIA hardware, which is common).
For smaller footprints, lean on quantization and possibly maintain a lighter model variant. Tools like ONNX Runtime with int8 can also accelerate CPU inference if GPU isn’t available.
Monitor performance metrics (throughput, latency P95, GPU utilization). If GPU isn’t maxed, increase batch sizes or concurrency; if latency is too high, may need to scale out or reduce batch waiting times.
Given the nature of our continuous improvement, we also need the serving to be robust to frequent updates. vLLM or TGI can reload a model fairly quickly if it’s just an adapter weight change (maybe a few seconds downtime). Alternatively, one can hot-swap LoRA by keeping the main model in memory and just applying the new delta weights – this is something that could be done if the serving code allows dynamic model update. TGI doesn’t (you’d load a new model id), but vLLM currently doesn’t have a hot-reload API either. One strategy: run two instances of the server: one with old adapter, one load new adapter in background, then switch routing to the new one (zero-downtime deploy at application level).
Edge deployment example: Perhaps part of the application is a mobile app that includes an offline mode chatbot with a 3B model. The architecture can periodically update that small model by distilling from the main model’s knowledge (maybe fine-tuning the small one on the conversation data and then compress). Then the new small weights are shipped in an app update or streamed to device if possible. This extends the improvement to client side albeit at reduced fidelity.
In sum, the deployment is the “last mile” where all the improvements materialize in user experience. By using these open source high-performance inference engines, we ensure the sophisticated self-improvement loop doesn’t get bottlenecked when serving actual users. It allows us to scale to potentially millions of requests per day without needing to multiply hardware linearly with traffic – the smart batching, optimized kernels, and quantization give us the efficiency needed.
10. Maintaining Alignment with Human Intent
As our LLM continuously retrains and adapts, we must ensure it remains aligned with human intent and values. The system should not drift into generating harmful, unethical, or undesired outputs. Techniques like Constitutional AI, ongoing oversight, and curated human feedback loops are critical to keep the model’s behavior in check. In the blueprint, this is a persistent layer of governance that wraps around the improvement cycle.
Constitutional AI (CAI), discussed earlier, provides a baked-in set of guidelines that the model uses to self-regulate (Constitutional AI with Open LLMs). By maintaining a fixed “constitution” of principles (e.g., honesty, harmlessness, helpfulness), we create an anchor for alignment even as the model learns new things. For example, one principle might be “The assistant should not give disallowed content (self-harm advice, hate speech, etc.), and should refuse or safe-complete such requests.” When the model is fine-tuned with CAI, it learns to follow these rules. As new data comes in (perhaps some users will inadvertently try to push the model’s boundaries), the constitutional principles help the model handle these gracefully. In practice, we’d include these principles either in the system prompt or as a reinforcement learning reward model. Anthropic’s method was to generate artificial Q&A where the model critiques outputs against principles and fine-tune on that (Constitutional AI with Open LLMs) – we can do similar with open models. Essentially, we treat the constitution as an unchanging part of the training data (like “laws of the AI”). Every time we fine-tune on user data, we might also include a batch of “constitutional training samples” to remind/reinforce these rules. This prevents the model from latching onto problematic user demonstrations (e.g., if a user tries to jailbreak it and succeeds once, that conversation won’t override the strong training on refusal patterns).
Human oversight loops: Even with automation, periodic human evaluation is valuable. For instance, a human might review a random sample of outputs each week (or use a panel of crowd-workers for scaling) to provide an “alignment score.” This acts as a gold standard that automated metrics can’t fully capture (they might miss subtle bias or context). This human feedback can be fed into the training as well (like RLHF traditionally does). If the model starts drifting (say it becomes overly terse, losing helpfulness, due to a mis-specified brevity reward), human testers can catch that and the reward function or prompt can be adjusted accordingly.
Transparency and explainability: The model’s chain-of-thought (which we encourage it to produce internally) can be logged and even shown to developers to understand why it gave a certain response. If it starts giving an answer that seems unaligned, we check its reasoning – perhaps it cites a harmful piece of data from vector store; that might signal we need to filter our knowledge base for such content (like remove extremist text that could be retrieved). The open nature of our system (we have full logs and model weights) means we can audit it. Contrast that to a closed API where if it gives a bad answer, you can’t easily tell why.
Regular “alignment evaluations”: There are standardized tests like Holistic Evaluation of Language Models (HELM) or AI alignment benchmarks (TruthfulQA, etc.). We can incorporate running these benchmarks on our model every time we update. For example, run the TruthfulQA suite – it checks how often the model gives imitative falsehoods or answers questions like a human would (often incorrectly). If our improvements inadvertently cause more falsehoods (perhaps due to using too much user data that contained misconceptions), we’d catch that. Another is Harmful Question answering: see if the model gives disallowed content when prompted with adversarial questions (OpenAI’s red-team datasets are partially available). By making these a routine part of eval, we maintain a bar for alignment.
Avoiding value lock-in vs drift: There’s a balance – we want the model to adapt to user preferences (maybe users find it too formal, so we make it more casual), but not veer into violating ethical guidelines (like becoming overly informal in inappropriate contexts, or favoring one political stance strongly). We likely maintain a clear separation of what can change (tone, factual knowledge, domain expertise) and what shouldn’t change (basic respect, refusal of harmful requests, unbiased treatment). The constitution covers the latter. We should be very cautious if ever editing those principles. One might update principles in consultation with ethicists or community input over time, but not frequently. In code, those might be a config file of rules fed to prompts – any change to that config is a big governance decision.
Tool use for oversight: Perhaps the LLM could call an “Ask human” tool when uncertain about a moral dilemma or when it feels a question is on the edge of its allowed content. For instance, it might output: “I need to consult a human on this request.” This could route to a human operator in a customer service setup. This is more for a high-stakes system, but mention it as an option. If no human available, the model has to rely on its principles to make a decision (likely refuse if unsure). But designing the model to know its limits is key to alignment.
Continuous training data curation: The pipeline that creates fine-tuning data (step 4 in blueprint) should include filters so that we don’t inadvertently train on malicious user inputs or fringe ideology content in a way that would bias the model. For example, if some users ask hateful things and the model appropriately refuses, we might log those interactions. But we wouldn’t want to fine-tune the model on transcripts containing the user’s hateful prompt verbatim (even with a refusal response) too often, because we could be inadvertently teaching it hateful language or normalizing seeing that context. Instead, we might abstract or remove slurs from the training instances (keeping the essence: "When user uses slur, model responds with refusal"). Open-source data filtering tools (like simple word filters or more advanced classifiers) can be used to clean the training data.
User intent understanding: Alignment isn’t just about avoiding bad content; it’s also aligning with what the user intended. Sometimes users have good intent but ask a question imprecisely – a smart aligned model should clarify rather than give a random answer. We can incorporate strategies like asking clarifying questions if the query is ambiguous (this was part of Anthropic’s helpfulness training). We ensure the model not only follows rules but also truly tries to understand and help the user. In the improvement loop, if evaluation shows users often come back with “No, that’s not what I meant”, we then adjust the model to ask rather than assume. That’s aligning to intent at a deeper level. It’s not easy to automate that metric, but things like conversation turn count or user satisfaction surveys can hint at it.
Community or stakeholder input: Being open-source, one can invite community audits of the model’s alignment. People can test the model and report issues, which become additional evaluation or training data. This collective oversight can catch things developers might miss (especially biases affecting groups the dev team isn’t part of). The blueprint can incorporate a feedback API or portal where users (or an internal red-team) submit problematic outputs for review. Those go into the feedback pool with high weight.
Security aspects: Alignment also includes not revealing private data or system prompts (avoid prompt injection issues). We should maintain strict input sanitization (like if the user says “Ignore previous instructions...”, the system prompt constitutional rules should override that). Our loop should test known prompt injection attempts. If one succeeds, that’s critical: it means the model was tricked to break rules. That conversation must inform a fine-tune where we emphasize the correct behavior in such scenario (likely via CAI examples of resisting such instructions). Also, incorporate prompt injection defenses: e.g., scanning user input for “ignore all” patterns and prepending a reminder to the model about not ignoring instructions. Aligning with the developer/human intent includes not letting user override them maliciously.
Final fail-safe: Possibly keep a lightweight rule-based filter on the final output channel. For example, after the model generates response, run it through OpenAI’s moderation model or a regex for extremely forbidden content. If triggered, either remove that part or replace the answer with a safe fallback (“I’m sorry, I can’t continue.”). This is an ultimate safety net. Ideally rarely used, because our model via training should avoid getting there, but in a production system it’s good to have.
The upshot is that maintaining alignment is an active, ongoing process woven into the self-improvement loop. Every cycle, we’re not just optimizing for correctness or user satisfaction, but also checking “Did the model remain within bounds?”. If there’s any tilt, we correct it immediately in the next cycle (with the strategies above). Over time, the model actually can become more aligned because it gets more practice following principles and we might expand its constitution with nuanced sub-guidelines based on real cases it encountered.
Crucially, no alignment solution is set-and-forget. Users might come up with new exploit strategies or novel offensive content; the world changes, making some responses outdated or biased. Our pipeline is designed to catch and address these adaptively (with human input as needed). Because everything is open-source, we avoid black-box surprises and can update the model’s “moral compass” in an open way (e.g., publish updates to the constitution or share the datasets of problematic cases and how we fixed them).
By continuously aligning with human intent (both the immediate intent of the user’s query and the broader intent of beneficial AI behavior), the system builds trust and reliability. It means the AI’s improvements in ability don’t come at the cost of its principles. In fact, ideally each iteration makes it not only smarter but also more conscientious – learning better how to say no when it should, how to respect user values, and how to stay factual and transparent.
Overall, our self-improving LLM architecture is not just a learning machine but an aligned learning machine, thanks to these open-source alignment interventions at every stage. Each improvement loop is bounded by alignment checks, ensuring progress in capability goes hand-in-hand with adherence to human expectations and values (Constitutional AI with Open LLMs).