Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Show-o Combines two powerful approaches (autoregressive and diffusion) in one model for multimodal tasks. 💡


Show-o Combines two powerful approaches (autoregressive and diffusion) in one model for multimodal tasks. 💡
Reduces image generation sampling steps by 20x compared to pure autoregressive methods. 💡
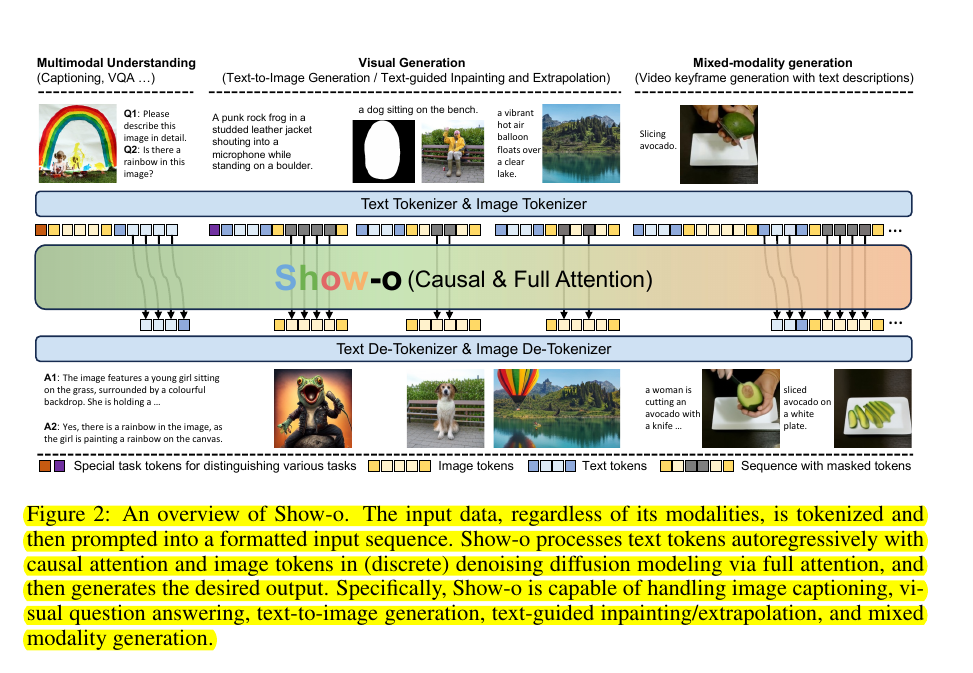
Show-o unifies autoregressive Transformer with (discrete) Diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. 🔥
Discrete diffusion and adaptive attention working together in a single model.
Original Problem 🔍:
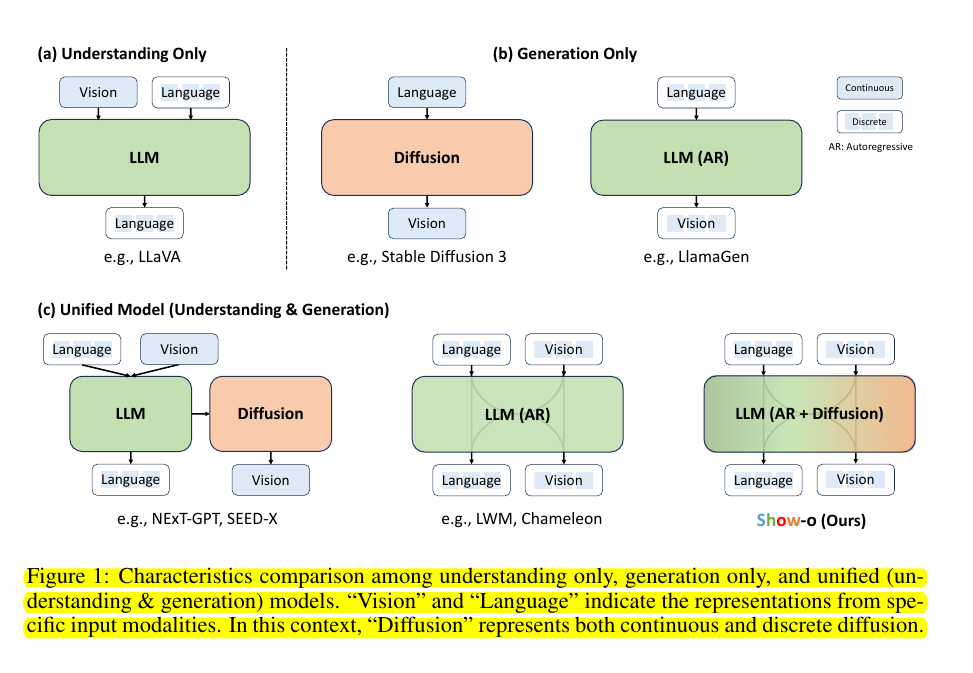
Existing models handle multimodal understanding and generation separately, using specialized architectures. Unified models often treat these tasks independently, using separate components. Autoregressive modeling of images requires many sampling steps, limiting efficiency.
Key Insights 💡:
• Unifying autoregressive and diffusion modeling in one transformer
• Adaptive attention mechanism for different input types
• Discrete image tokens for both understanding and generation
• Three-stage training pipeline for effective alignment
Solution in this Paper 🧠:
• Show-o: A single unified transformer for multimodal tasks
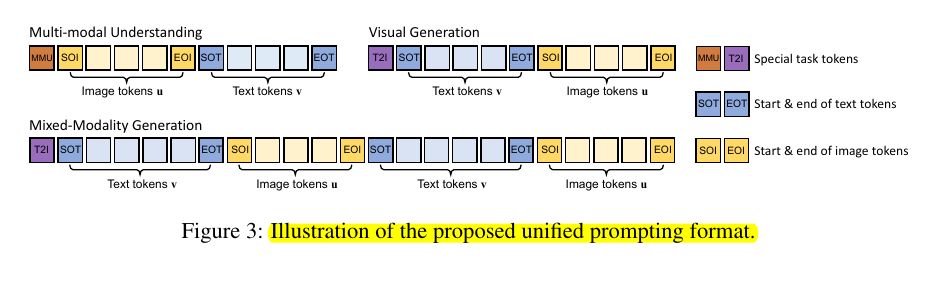
• Unified prompting strategy to format various input types
• Omni-attention mechanism: Causal attention for text, full attention for images
• Discrete diffusion process for image generation
• Three-stage training: Image token embedding, image-text alignment, high-quality data fine-tuning
• Built on Phi-1.5 with 1.3B parameters
Results 📊:
• Multimodal Understanding: Comparable to LLaVA-v1.5-Phi-1.5 baseline
• POPE: 73.8 vs 84.1
• MME: 948.4 vs 1128.0
• Sampling efficiency: 20x fewer steps than autoregressive models