Sparse Matrix in Large Language Model Fine-tuning
By targeting V vectors in attention layers, Sparse Matrix Tuning (SMT) achieves full model performance with minimal resources.


By targeting V vectors in attention layers, Sparse Matrix Tuning (SMT) achieves full model performance with minimal resources.
Smart matrix pruning lets LLMs learn fast without the heavy lifting
Basically, as per this paper, LLMs learn better when we only update the 5% that actually matters
Original Problem 🎯:
Parameter-efficient fine-tuning (PEFT) methods like LoRA face accuracy gaps compared to full fine-tuning and hit performance plateaus as parameter counts increase.
Solution in this Paper 🔧:
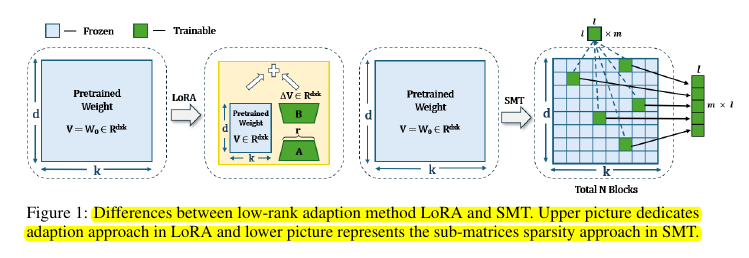
• Introduces Sparse Matrix Tuning (SMT) that identifies and fine-tunes only critical sub-matrices
• Uses gradient analysis during warm-up phase to select important sub-matrices
• Focuses on attention layers, particularly V vectors, which store most model memory
• Freezes non-selected layers to save computational costs
• Implements custom sparse linear layer for efficient gradient computation
Key Insights 💡:
• Attention layers are more crucial than MLPs for downstream performance
• V vectors contain most model memory, outperforming K vectors by 4.6% and Q vectors by 3.2%
• Memory sections are primarily in attention layers, not MLPs as previously thought
• SMT overcomes LoRA's performance plateau issue while using fewer parameters
Results 📊:
• Outperforms LoRA and DoRA by 2+ points across various tasks
• Reduces GPU memory footprint by 67% vs full fine-tuning
• Achieves 14.6x speedup compared to full fine-tuning
• Saves 99.5% of optimizer memory
• Maintains performance comparable to full fine-tuning using only 5% parameters
🎯 Sparse Matrix Tuning (SMT) is different from other PEFT methods
SMT identifies important sub-matrices by analyzing gradient updates during a warm-up phase.
Unlike LoRA which uses low-rank adaptations, SMT directly updates selected sparse sub-matrices.
It focuses mainly on attention layers, particularly the V vectors, which were found to be most influential for model performance.