STAR: A Simple Training-free Approach for Recommendations using Large Language Models
LLMs meet user clicks: smart recommendations.


LLMs meet user clicks: smart recommendations.
Zero-shot Training-free recommendation system combines LLM smarts with user interaction patterns
Original Problem 🎯:
Current recommendation systems either require expensive LLM fine-tuning or fail to effectively combine semantic and collaborative information. This leads to sub-optimal performance and high implementation costs.
Solution in this Paper 🛠️:
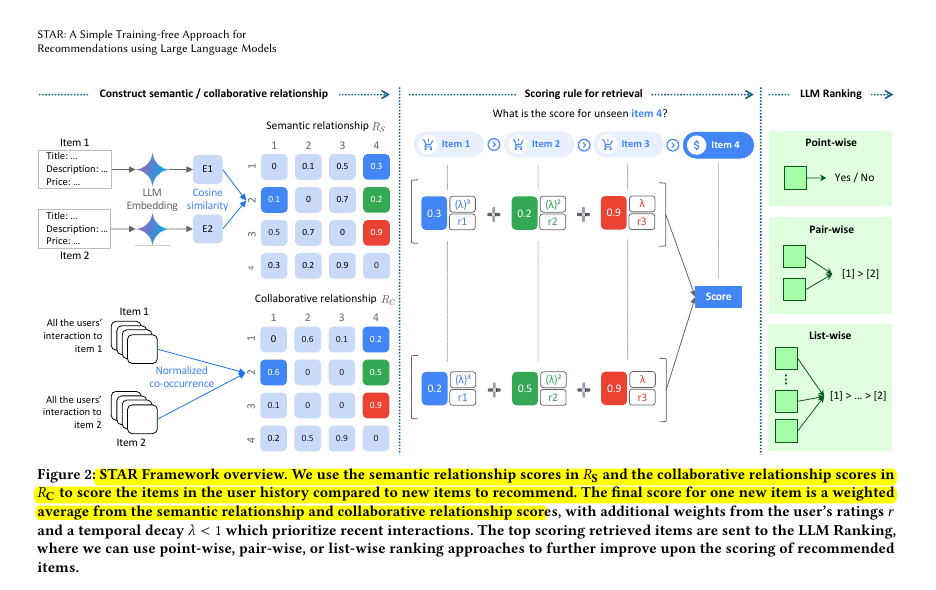
• STAR framework introduces a two-stage approach: Retrieval and Ranking
• Retrieval stage:
Combines LLM embeddings for semantic similarity
Uses collaborative user data and temporal factors
Applies weighted scoring based on user ratings
• Ranking stage:
Employs pair-wise LLM ranking
Incorporates item metadata, popularity, and co-occurrence data
Uses sliding window approach for efficient comparisons
Key Insights from this Paper 💡:
• Semantic embeddings from LLMs can directly serve as effective item representations
• Pair-wise ranking outperforms point-wise and list-wise methods
• Collaborative information critically enhances both retrieval and ranking stages
• Initial ordering of candidates significantly impacts final ranking quality
• Temporal decay factors improve recommendation relevance
Results 📊:
• Hits@10 improvements: +23.8% on Beauty dataset
• +37.5% performance gain on Toys/Games category
• Only -1.8% performance gap vs best supervised models on Sports/Outdoors
• Pair-wise ranking improves retrieval results by +1.7% to +7.9%
• Achieves competitive results without any training or custom architectures
🛠️ The key components and workflow of STAR framework
Two-stage approach: Retrieval and Ranking
Retrieval stage uses LLM embeddings for semantic similarity plus collaborative user data
Includes temporal factors to prioritize recent interactions
Ranking stage uses LLM reasoning to refine initial recommendations