
Starbucks: Improved Training for 2D Matryoshka Embeddings
New embedding method, Starbucks Representation Learning (SRL), switches dimensions on demand, performs like specialized single-size models.

New embedding method, Starbucks Representation Learning (SRL), switches dimensions on demand, performs like specialized single-size models.
Single model generates multiple embedding sizes with no performance loss, unlike previous approaches.
Original Problem 🎯:
2D Matryoshka embedding models allow flexible embedding generation across dimensions and layers, but their effectiveness is significantly worse than separately trained models, making them impractical despite their efficiency benefits.
Solution in this Paper 🔧:
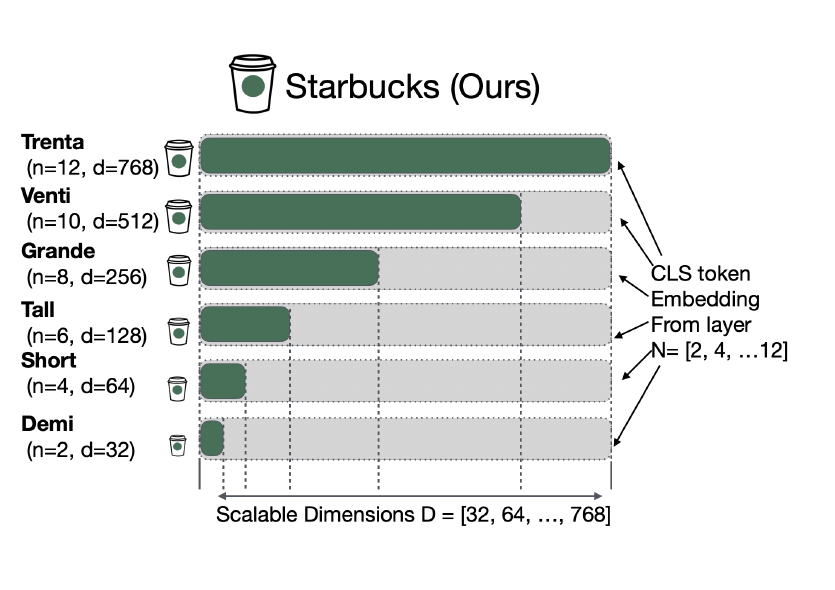
• Starbucks Representation Learning (SRL): Fine-tunes using fixed layer-dimension pairs from small to large sizes
• Starbucks Masked Autoencoding (SMAE): Pre-trains backbone model using masked autoencoder language modeling
• Uses targeted list of 6 layer-dimension pairs: [(2,32), (4,64), (6,128), (8,256), (10,512), (12,768)]
• Adds KL divergence loss to align embeddings across different sizes
Key Insights 💡:
• Random sampling of layer-dimension pairs during training reduces effectiveness
• Focusing on practical configurations from small to large sizes works better
• Pre-training with SMAE creates stronger foundation for smaller model sizes
• KL divergence loss helps align embeddings across different configurations
Results 📊:
• Matches or outperforms separately trained models in effectiveness
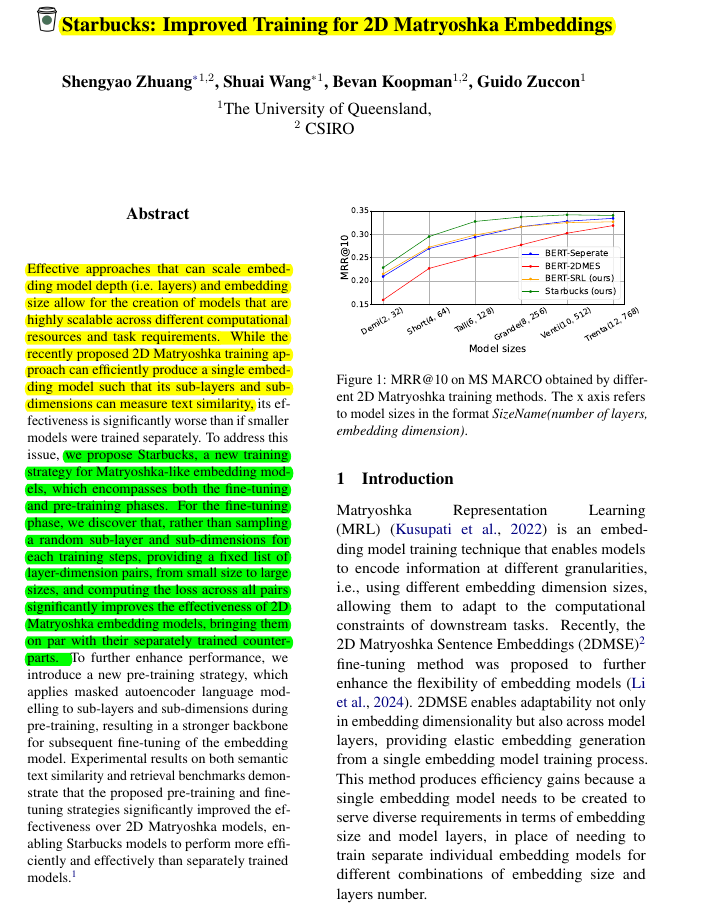
• STS tasks: Average Spearman correlation of 0.7837 vs 0.7644 for separate models
• MS MARCO retrieval: MRR@10 of 0.3116 vs 0.2917 for separate models
• SMAE pre-training provides additional 2-3% effectiveness gains for smaller sizes
Starbucks provides a single model with flexible configurations in terms of embedding dimensionality and network layer.
🚀 How does Starbucks improve over existing 2D Matryoshka models?
Instead of trying to cover all possible layer-dimension combinations, Starbucks:
Uses a targeted list of layer-dimension pairs during training
Focuses on practical configurations from small to large sizes
Adds KL divergence loss to align embeddings across different sizes
Introduces SMAE pre-training to create a stronger foundation.