
Steering Knowledge Selection Behaviours in LLMs via SAE-Based Representation Engineering
Sparse autoencoders (SAEs) navigate LLM knowledge conflicts by tweaking neural activations and fix them without retraining.


Sparse autoencoders (SAEs) navigate LLM knowledge conflicts by tweaking neural activations and fix them without retraining.
Original Problem 🎯:
LLMs face conflicts between parametric knowledge (stored in model weights) and contextual knowledge (from external sources), leading to inconsistent or incorrect outputs. Existing solutions require multiple model interactions or complex fine-tuning.
Solution in this Paper 🔧:
• Introduces SpARE - a training-free representation engineering method using pre-trained sparse auto-encoders (SAEs)
• Detects knowledge conflicts by probing residual stream in mid-layers
• Decomposes complex representations into monosemantic features using SAEs
• Identifies and manipulates functional features controlling knowledge selection
• Applies targeted edits to internal activations at inference time
• Uses less than 0.05% SAE activations for steering knowledge behavior
Key Insights 💡:
• Knowledge conflicts are detectable in mid-layer residual streams
• SAEs enable precise control over knowledge selection
• Mid-layers are most effective for steering behavior
• Input-dependent editing outperforms static intervention
• Both feature removal and addition are crucial for effective control
Results 📊:
• Outperforms existing representation engineering methods by 10%
• Surpasses contrastive decoding approaches by 15%
• Achieves 7% better performance than in-context learning
• Successfully controls knowledge selection using minimal SAE features
• Most effective at mid-layers where conflict signals are strongest
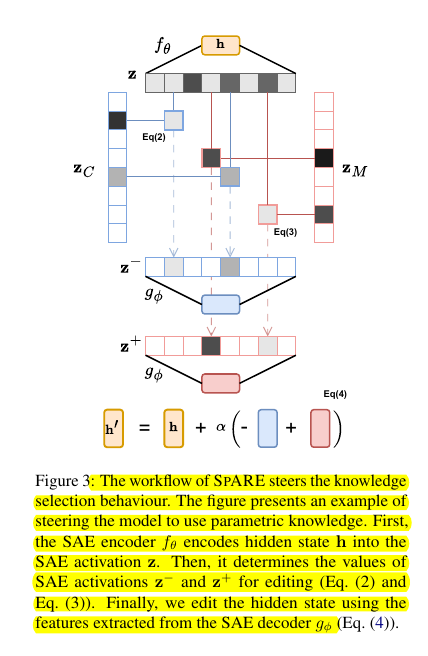
🧪 How does SpARE detect and resolve knowledge conflicts?
SpARE first identifies that knowledge conflicts can be detected by probing the residual stream of mid-layers in LLMs.
It then uses SAEs to decompose complex representations into monosemantic features, identifies the features related to knowledge selection behaviors, and applies them to edit internal activations at inference time to steer the model toward using either contextual or parametric knowledge.
🔧 SpARE's approach differ from existing methods.
Unlike existing representation engineering methods that directly modify polysemantic dense vectors, SpARE uses SAEs to decompose them into monosemantic features for more precise editing.
It differs from contrastive decoding and in-context learning approaches by providing an efficient inference-time solution that doesn't require additional model interactions or input modifications.