Superposition Prompting: Improving and Accelerating RetrievalAugmented Generation
Superposition prompting accelerates and enhances RAG without fine-tuning, addressing long-context LLM challenges.

Superposition prompting accelerates and enhances RAG without fine-tuning, addressing long-context LLM challenges.
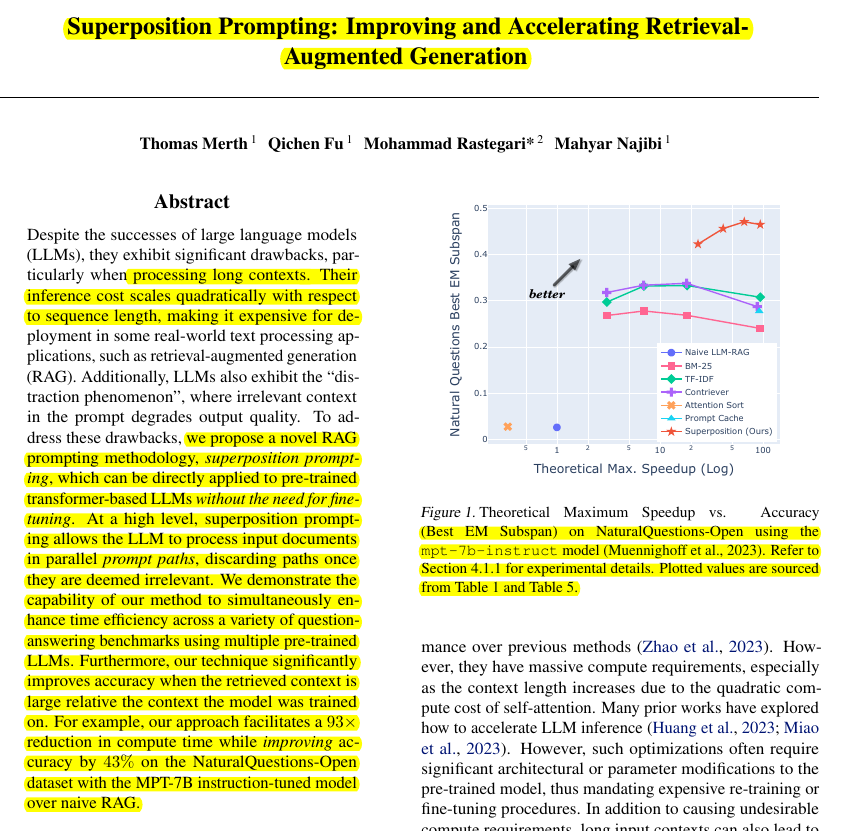
93× reduction in compute time on NaturalQuestions-Open with MPT-7B 🤯
Key Insights from this Paper 💡:
• Parallel processing of input documents can reduce compute time
• Pruning irrelevant paths improves accuracy and efficiency
• Position assignment strategies affect model performance
• Iterative superposition enhances multi-hop reasoning
Solution in this Paper 🧠:
• Superposition prompting: A novel RAG methodology for pre-trained transformer-based LLMs
• ForkJoin topology: Processes documents in parallel prompt paths
• Path pruning: Discards irrelevant paths using Bayesian saliency scoring
• Equilibrium position assignment: Optimizes token positioning for better performance
• Path caching and parallelization: Further accelerates inference
Results 📊:
• 43% improvement in accuracy on the same dataset
• Outperforms baselines like Naive LLM-RAG, BM-25, TF-IDF, and Contriever
• Effective across various model sizes and architectures (OpenELM, BLOOMZ, MPT)
• Demonstrates improved performance on multi-hop reasoning tasks (MuSiQue dataset)

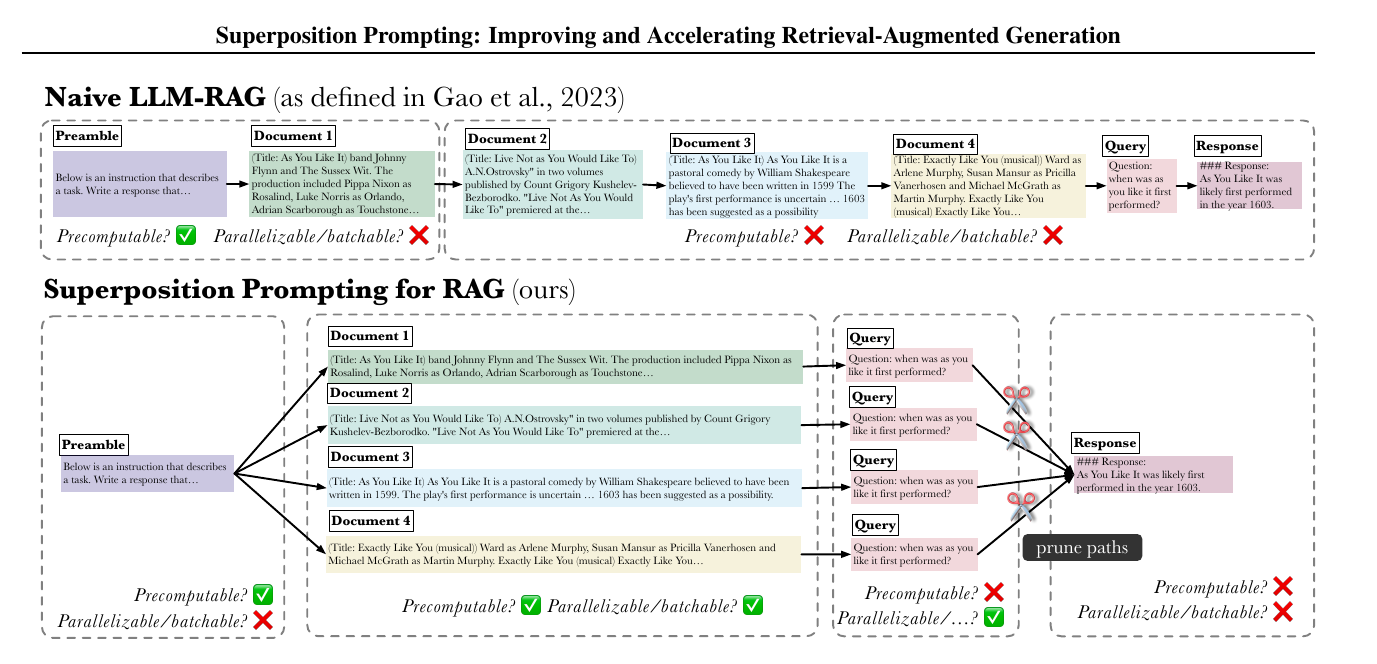
Comparison of superposition prompting vs. the “classical” (Naive LLM-RAG) prompting paradigm.
Whereas the classical approach is a “linked-list” style DAG, superposition prompting arranges token dependencies such that all documents are processed independently. Due to this dependency structure, we can easily leverage the LLM logits to prune irrelevant context, improving long context reasoning.
The dependency structure also allows for faster prompt processing, due to the new opportunities for caching and parallelism of the KV cache and logit computations (each gray box represents, logically, a “batch” that is processed by the LLM, reusing upstream KV caches).