
SWITCH: Studying with Teacher for Knowledge Distillation of Large Language Models
Smart teacher intervention during knowledge distillation prevents student models from going off track


Smart teacher intervention during knowledge distillation prevents student models from going off track
Like having a backup teacher who steps in exactly when needed
🤖 Original Problem:
Knowledge Distillation (KD) for LLMs faces challenges with student-generated outputs (SGOs). These outputs often produce noisy and biased sequences, leading to misguidance from teacher models, especially in long sequences. This affects the quality of knowledge transfer and model compression.
🔧 Solution in this Paper:
• SWITCH (Studying WIth TeaCHer) strategically incorporates teacher model during student sequence generation
• Uses Jensen-Shannon divergence to detect discrepancies between teacher-student token probabilities
• Implements exponential decaying threshold that increases teacher involvement as sequence length grows
• When divergence exceeds threshold, switches from student to teacher for next token generation
• Decay factor of 1/10 achieves optimal balance between student (47%) and teacher (53%) token generation
💡 Key Insights:
• Teacher intervention becomes more crucial as sequence length increases
• Exponential decay performs better than linear decrease or constant threshold
• Strategic teacher involvement prevents error accumulation in longer sequences
• Balanced token generation between student-teacher improves knowledge transfer
📊 Results:
• Outperforms baselines across 5 instruction-following benchmarks and 3 model families
• Shows significant gains with larger size differences between student-teacher models
• Achieves 26.2 Rouge-L score on Dolly dataset (vs 24.9 baseline)
• Maintains 47%/53% student-teacher token generation ratio
🔍 What makes SWITCH different from existing knowledge distillation methods?
Unlike traditional methods that rely solely on student-generated outputs, SWITCH selectively involves the teacher model during sequence generation based on distribution discrepancy.
This balanced approach preserves the benefits of student learning while preventing misguidance through strategic teacher intervention.
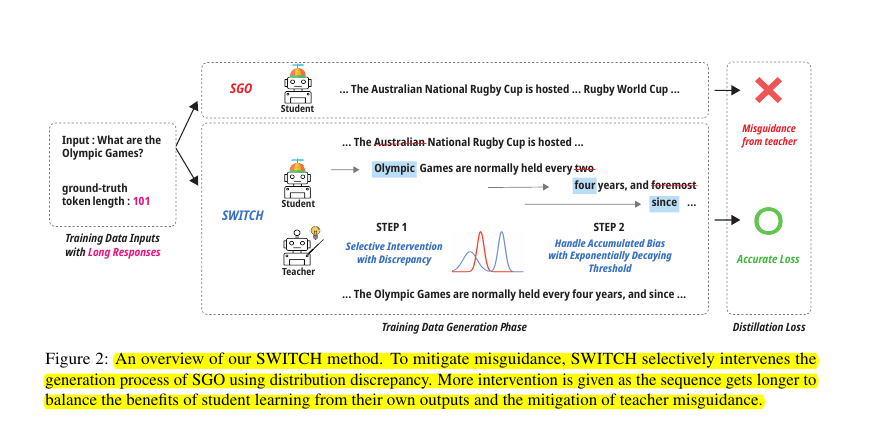
🎯 SWITCH identifies discrepancies between token probabilities of teacher and student models using Jensen-Shannon divergence.
When divergence exceeds a threshold, it switches from student to teacher model for generating the next token. The threshold decays exponentially as sequence length increases to prevent error accumulation in longer sequences.

