TableRAG: Million-Token Table Understanding with Language Models
A smart retrieval system lets AI handle massive tables by grabbing only what it needs


A smart retrieval system lets AI handle massive tables by grabbing only what it needs
TableRAG picks important data from huge tables like finding needles in digital haystacks
Original Problem 🎯:
LLMs struggle with handling large tables due to context length constraints and positional bias. Current methods require entire tables as input, leading to performance degradation and computational inefficiencies when dealing with large-scale tabular data.
Solution in this Paper 🔧:
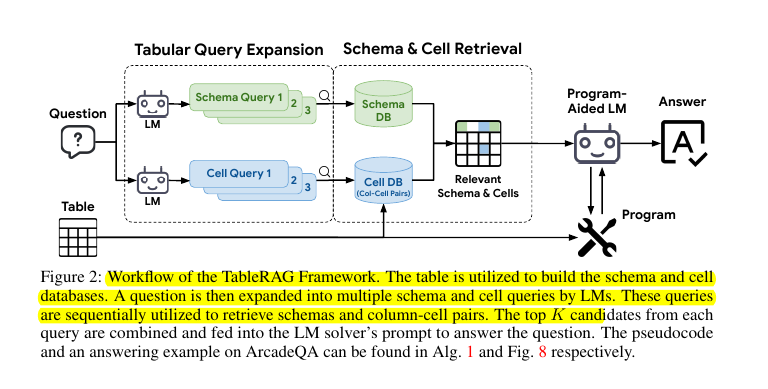
• TableRAG introduces a novel retrieval framework combining schema and cell retrieval
• Uses query expansion to identify crucial columns and data types using just column names
• Implements cell retrieval to find keywords for indexing and locating relevant columns
• Builds cell database by encoding distinct values independently
• Employs frequency-aware truncation to handle large tables within token budgets
• Integrates with program-aided LM agents for efficient table reasoning
Key Insights 💡:
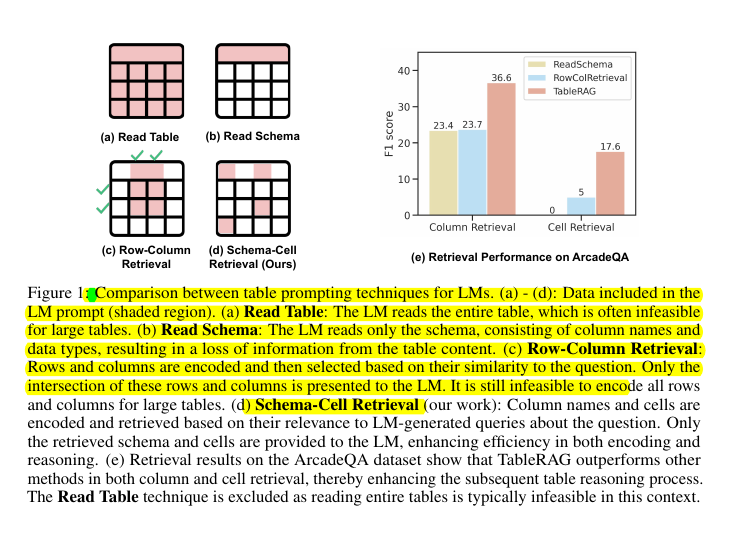
• Encoding entire rows/columns becomes infeasible for large tables with millions of cells
• Query expansion significantly improves retrieval quality for both schema and cells
• Most tables contain far fewer distinct values than total cells, enabling efficient retrieval
• Schema-only approaches miss crucial cell-level information needed for accurate answers
Results 📊:
• Achieves highest retrieval quality in both column and cell retrieval on ArcadeQA dataset
• Maintains 68.4% accuracy on 1000x1000 synthetic tables vs 83.1% on smaller tables
• Outperforms existing methods on WikiTableQA benchmark with 57.03% accuracy
• Demonstrates consistent performance across various table scales while using fewer tokens
Single Sentence
💡 TableRAG's retrieval mechanism works by using two key components:
Schema retrieval identifies important columns and data types using just column names
Cell retrieval enables finding keywords for indexing and locating columns containing necessary information
Both processes use query expansion with dedicated prompts to ensure thorough data extraction.