Taming Overconfidence in LLMs: Reward Calibration in RLHF
New training methods teach LLMs to stop being overconfident about wrong answers.


New training methods teach LLMs to stop being overconfident about wrong answers.
PPO-M and PPO-C make LLMs admit when they're unsure, just like humans do
Original Problem 🚨:
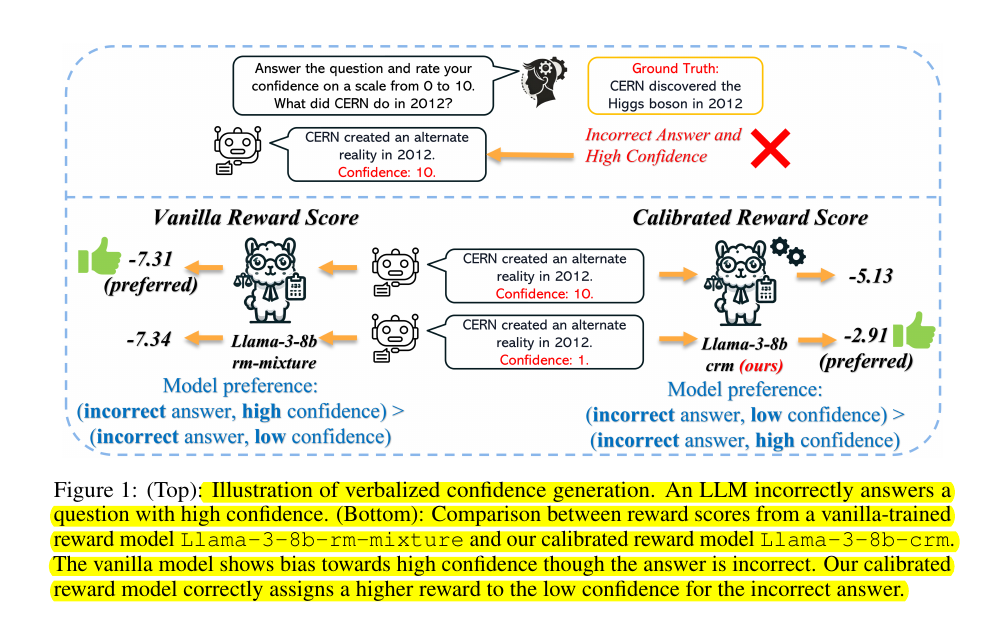
RLHF-trained LLMs exhibit overconfidence, expressing high confidence in responses regardless of their quality. This stems from biases in reward models that favor high-confidence scores, leading to poor calibration.
Solution in this Paper 🛠️:
PPO-M (Proximal Policy Optimization with Calibrated Reward Modeling):
Integrates explicit confidence scores into reward model training.
Encourages alignment between confidence levels and response quality.
PPO-C (Proximal Policy Optimization with Calibrated Reward Calculation):
Adjusts reward scores during training based on a moving average of past rewards.
Reduces bias towards high-confidence responses.
Key Insights from this Paper 💡:
Overconfidence in RLHF-LLMs is linked to biased reward models.
Calibration can be improved without additional golden labels.
Both PPO-M and PPO-C can be integrated into existing RLHF frameworks.
Results 📊:
PPO-M and PPO-C reduce Expected Calibration Error (ECE) while maintaining accuracy.
On Llama3-8B, PPO-M reduces ECE by 6.44 points and increases accuracy by 2.73 points on GSM8K.
Both methods preserve capabilities in open-ended conversation settings.