TemporalBench: Benchmarking Fine-grained Temporal Understanding for Multimodal Video Models
TemporalBench, introduced in this paper, reveals that top AI models can only understand 38% of video actions that humans easily grasp.


TemporalBench, introduced in this paper, reveals that top AI models can only understand 38% of video actions that humans easily grasp.
TemporalBench exposes the limitations of current video understanding models through fine-grained temporal evaluation.
Original Problem 🔍:
Existing video benchmarks often resemble static image tasks and fail to evaluate models' ability to understand temporal dynamics in videos. This leads to inflated performance metrics that don't reflect true video comprehension capabilities.
Solution in this Paper 🛠️:
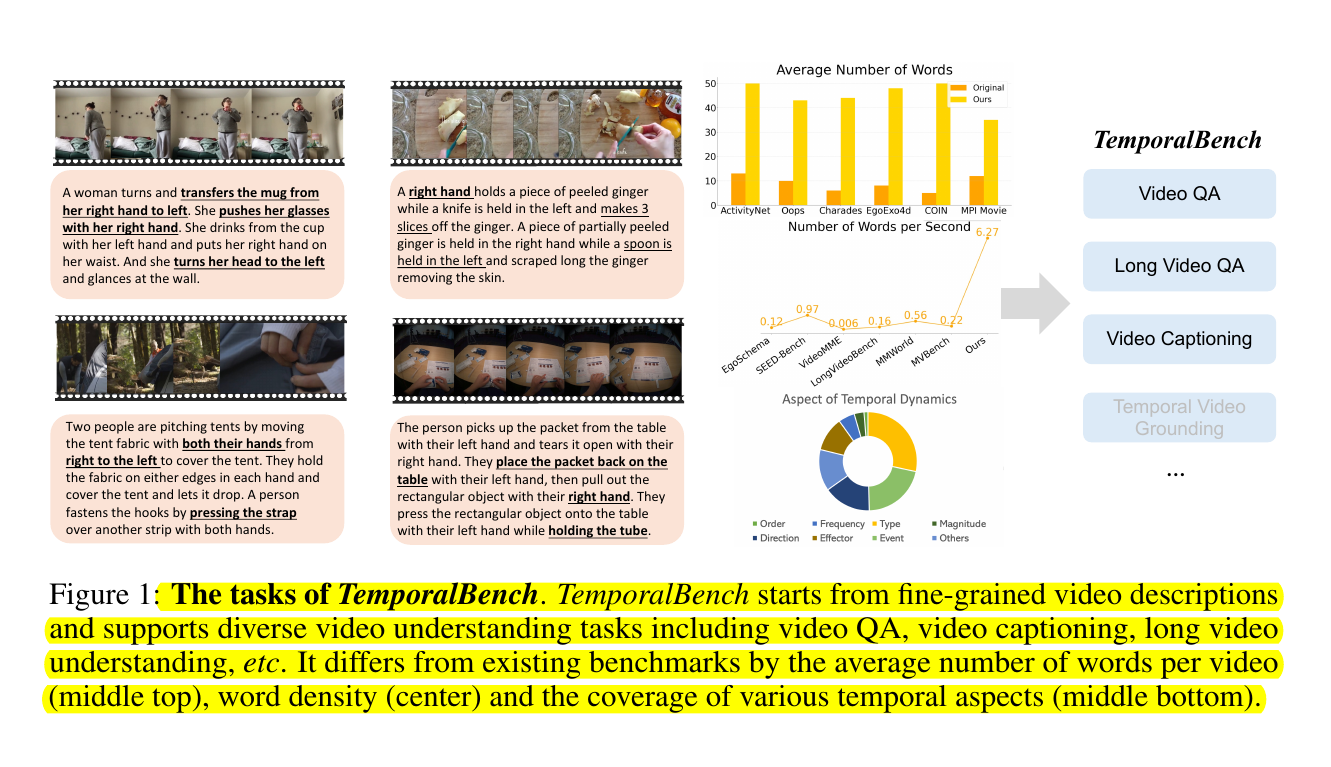
• TemporalBench: A new benchmark with ~10K video question-answer pairs from ~2K human-annotated captions
• Focuses on fine-grained temporal understanding in videos
• Supports diverse tasks: video QA, captioning, long video understanding, retrieval, grounding, text-to-video generation
• Proposes Multiple Binary Accuracy (MBA) metric to address multi-choice QA biases
Key Insights from this Paper 💡:
• Fine-grained temporal annotations enable more challenging and meaningful video understanding evaluation
• Current models struggle with action frequency, motion magnitude, and event order reasoning
• Long video understanding remains extremely difficult for existing models
• MBA provides a more robust evaluation metric than standard multi-choice QA
Results 📊:
• State-of-the-art GPT-4o achieves only 38.5% MBA on short video QA (vs 67.9% human performance)
• All models show significant performance drop on long video understanding
• Video embedding models like XCLIP perform near random chance
• Models struggle most with action frequency tasks
🧠 Key abilities does TemporalBench evaluate
It evaluates various temporal understanding and reasoning abilities such as:
Action frequency
Motion magnitude
Event order
Action types
Motion direction/orientation
Action effectors