
Tencent just dropped HunyuanVideo: new 13B param open-source text-to-video model rivaling Runway Gen-3, Luma 1.6
Breaking AI news: Tencent's text-to-video model, Luma's efficient generators, actor-based LLMs, Runway's visual tools, China's mineral strategy.


In today’s Edition (3-Dec-2024):
🎨 Tencent just dropped Hunyuan Video, new open source AI text-to-video model
🖌️ Luma releases new image generation models with 10x cost reduction and superior quality
🤖 Researchers boost LLM performance by treating AI models as actors rather than thinkers
⚡ Runway launches visual interface system enabling natural language AI content creation
🔧 China weaponizes rare mineral exports to counter US chip restrictions
Byte-Size Brief
OpenAI plans ChatGPT ads as costs exceed revenue
Anthropic launches $2,100/week AI safety fellowship program
NotebookLM creator exits Google to start new venture
🎨 Tencent just dropped Hunyuan Video, new open source AI text-to-video model
The Brief
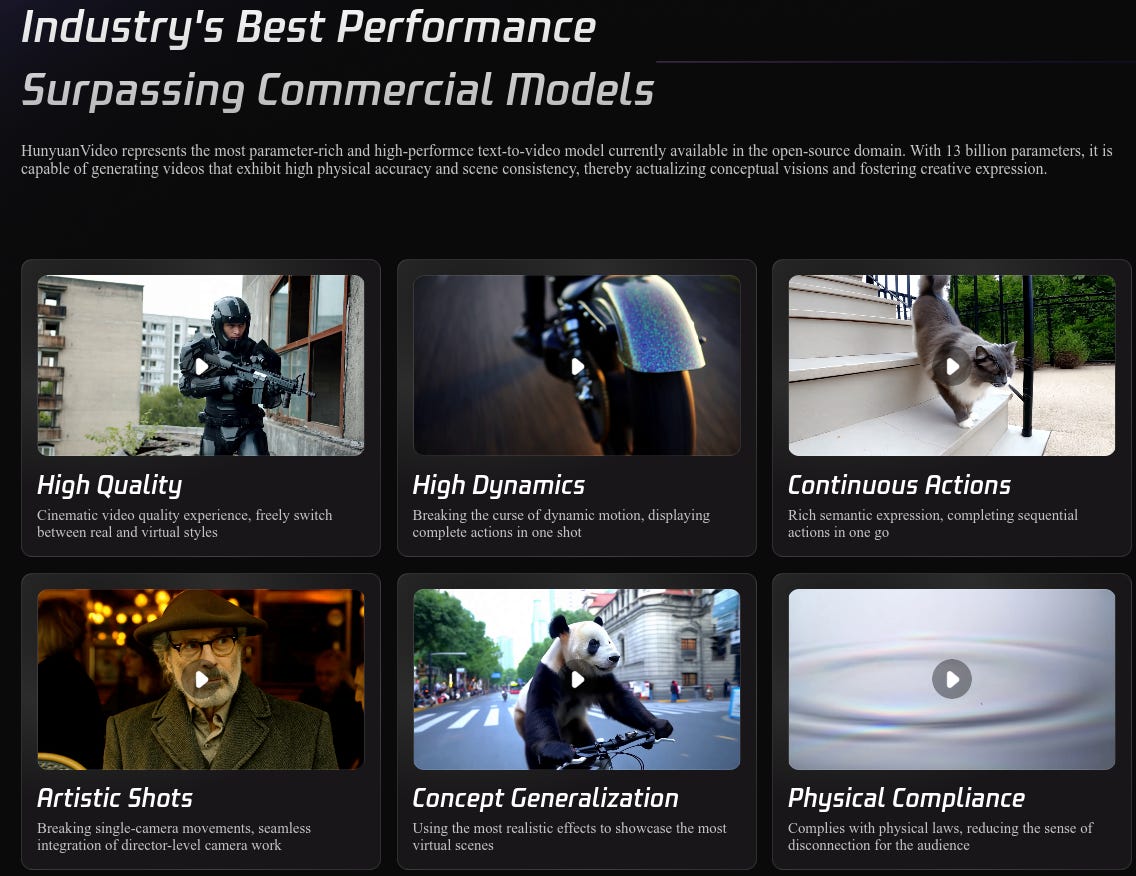
Tencent introduced HunyuanVideo, a 13B-parameter open-source video generation model matching commercial solutions like Runway Gen-3, Luma 1.6, while achieving 68.5% text alignment, 64.5% motion quality, and 96.4% visual quality across 1,533 prompts. Quality looks insane.
HunyuanVideo is the largest open-source text-to-video model with 13 billion parameters
Features innovative video-to-audio synthesis for realistic sound generation
Enables precise control over avatar animations through multiple input methods
Uses advanced scaling techniques to reduce computational costs by up to 80%
The system introduces several technical innovations, including a revolutionary video-to-audio module that can automatically generate synchronized sound effects and background music for videos. This addresses a critical gap in existing video AI tools, which typically produce silent output.
The model's avatar animation capabilities are equally impressive. It can control digital characters through multiple input methods - voice, facial expressions, or body poses - while maintaining consistent identity and high visual quality. This makes it particularly valuable for virtual production and digital content creation.
Technical Details
→ The architecture employs a Causal 3D VAE for intelligent video compression with specific ratios: 4x for time dimension, 8x for spatial dimensions, and 16x for channels. A decoder-only Multimodal LLM serves as text encoder, enabling enhanced image-text alignment.
→ The model supports various aspect ratios including 9:16, 16:9, 4:3, 3:4, and 1:1 with resolutions up to 720p.
→ Running on H800/H20 GPUs, it requires 45-60GB memory (batch size = 1) depending on resolution settings to generate videos.

→ Progressive training strategy implements three stages: low-resolution short videos, low-resolution long videos, and high-resolution long videos. The framework includes sophisticated prompt rewriting and data filtering pipelines.
→ Applications span video generation, avatar animation, audio synthesis, and expression/pose control through a unified system.
→ The complete system, including the video-to-audio module and avatar animation tools, is now available on GitHub. Tencent has also released comprehensive performance evaluations and technical documentation detailing the model's architecture and training methods.
The Impact
HunyuanVideo bridges closed-source/open-source performance gap, enabling broader community access to high-quality video generation capabilities. Also note, since the announcement of Sora by OpenAI, Chinese tech has picked up some great acceleration and has released many text-video models namely CogVideoX, MiniMax, Kling, etc.
🖌️ Luma releases new image generation models with 10x cost reduction and superior quality

The Brief
Luma AI launches two new text-to-image models - Photon and Photon Flash, delivering superior quality at 10x cost efficiency and 60.1% preference score over competing models.
The Details
→ Photon models introduce groundbreaking architecture with large context windows and enhanced language understanding. Cost structure is highly competitive at $0.015 for 1080p image with Photon and $0.002 with Photon Flash.
→ Model demonstrates exceptional capabilities in prompt adherence, character consistency, and multi-image referencing. Unique feature allows generating consistent characters from single input image across multiple scenes.
→ In blind evaluations, Photon outperforms major competitors like Stable Diffusion 3.5, Ideogram, Midjourney, and Flux 1.1 across diverse prompts including film, design, art styles, and fashion categories.
The Impact
By significantly reducing creation costs, Luma hopes to enable more creators to realize their creative visions and drive the development of the entire creative industry.
🤖 Researchers boost LLM performance by treating AI models as actors rather than thinkers

The Brief
Researchers introduce "Method Actors" framework for LLM prompt engineering, achieving 86% success rate in solving complex word puzzles through novel approach treating LLMs as performers rather than thinkers.
The Details
→ The core concept reframes LLMs as actors performing scripts (prompts) rather than simulating thought processes. Framework establishes four key principles: prompt engineering as directing, performance preparation, task decomposition, and non-LLM method compensation.
→ Testing using Connections puzzles revealed significant performance improvements. The vanilla approach achieved 27% success, Chain-of-Thought improved to 41%, while the Method Actor approach reached 78%, and Actor-2 peaked at 86%.
→ With o1-preview model, performance increased further. One-shot approach achieved 79% success, vanilla approach reached 100% with multiple attempts, and Method Actor achieved 87% perfect solutions.
The Impact
Method Acting framework demonstrates superior LLM performance by focusing on imitation rather than simulated reasoning.
⚡ Runway launches visual interface system enabling natural language AI content creation
The Brief
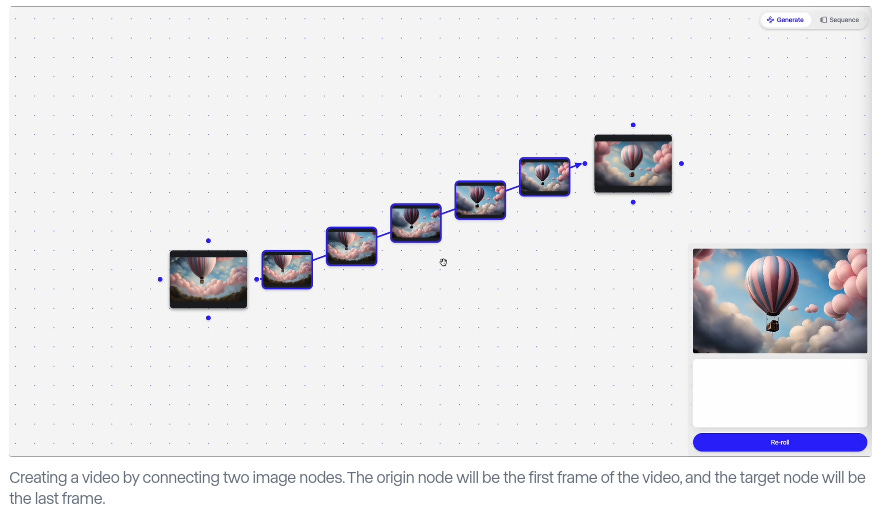
Runway introduces a novel graph-based interface for creative exploration in AI latent spaces, transforming how creators interact with generative models through natural language commands and visual navigation.
The Details
→ The system reimagines creative software by treating creativity as a search process in latent space. Instead of using sliders or buttons to create AI art/videos, this system treats creativity like searching through a map of possibilities - where each point represents a different AI-generated creation. You can naturally control transitions, styles, and variations through simple commands.
→ So you can modify AI-generated videos by connecting image points in a graph, like plotting waypoints on a map.
→ Core innovation lies in the graph structure, where images function as nodes and videos as edges. Users can navigate through this space by connecting nodes, creating transitions across the latent space and time.
→ The interface balances control and serendipity through two key affordances: precise node manipulation and relational image transformations that allow controlled unpredictability.
→ System enables non-linear exploration through branching paths and spatial organization of experiments, supporting both divergent and convergent creative thinking.
The Impact
Graph-based navigation and natural language control revolutionize creative tool interfaces, enabling intuitive exploration of AI-generated possibilities.
🔧 China weaponizes rare mineral exports to counter US chip restrictions

The Brief
China bans export of critical semiconductor materials to US, including gallium, germanium, and antimony. China controls 98% of global gallium and 60% of germanium production, directly impacting semiconductor manufacturing capabilities worldwide.
The Details
→ Chinese commerce ministry implemented immediate export controls on dual-use materials vital for semiconductor production and military applications. The move responds to US restrictions targeting China's AI development capabilities.
→ Four major Chinese trade associations, representing internet, auto, semiconductor, and communications sectors, advised members to reduce American chip purchases, citing reliability concerns.
→ Earlier The US blacklisted 136 Chinese companies, including major Apple supplier Wingtech. This action led to a 10% drop in Wingtech's stock value over two days.
→ Japanese chip equipment suppliers benefited from these restrictions, with companies like Tokyo Electron, Disco Corp, and Lasertec seeing 4-6% stock gains.
The Impact
Export restrictions disrupt global semiconductor supply chains, forcing Western nations to diversify material sources.
Byte-Size Brief
OpenAI might start showing ads in ChatGPT to help pay its billion-dollar electricity and computing bills. The company hired advertising experts from Google and Meta, though executives remain divided. Current revenue streams cover only 80% of operational costs despite generating $4B annually.
Anthropic just launched Anthropic Fellows Program for AI Safety Research. Engineers can now get paid to learn AI safety directly from Anthropic's research team. The 6-month fellowship provides $2,100 weekly, compute credits, and 1:1 mentorship. Fellows work on critical problems like robustness, oversight, and interpretability in Bay Area or London.
The NotebookLM product-lead, Raiza Martin left Google, to found her own new company. She spent 5.5 years transforming an experimental concept into a full-fledged research assistant, marking a significant milestone in AI-powered podcast-generation and teaching tools.