
🥉 Tencent released world’s first Text-and-images-to-3D AI model, Hunyuan3D-2.0
AI advances spotlight Tencent’s 3D model, Minimax’s emotional T2A, Microsoft’s math boost, Meta’s CoT enhancement, and tools for LLM memory, video, and data structuring.
Read time: 5 min 51 seconds
⚡In today’s Edition (21-Jan-2025):
🥉 Tencent released world’s first Text-and-images-to-3D AI model, Hunyuan3D-2.0
🏆 Minimax Unveils T2A-01-HD, The Text-To-Audio With Unmatched Emotional Depth, And Multilingual Authenticity
🗞️ Byte-Size Brief:
Microsoft open-sources rStar-Math, boosting Qwen-7B accuracy to 90% on MATH dataset using MCTS and self-evolution.
Titan releases Huggingface Model Memory Calculator for device-specific LLM batch size planning.
Meta open-sources Coconut, enhancing LLM reasoning with continuous latent CoT paths.
ComfyUI adds Nvidia Cosmos support for text-to-video, creating dynamic 121-frame outputs on 12GB GPUs.
Firecrawl launches "Extract," turning websites into structured data with 500K free tokens in beta.
Moonshot AI debuts Kimi k1.5, a multi-modal LLM with SOTA results, 128k token window, and CoT reasoning.
🧑🎓 Deep Dive Tutorial
🥉 Tencent released world’s first Text-and-images-to-3D AI model, Hunyuan3D-2.0
🎯 The Brief
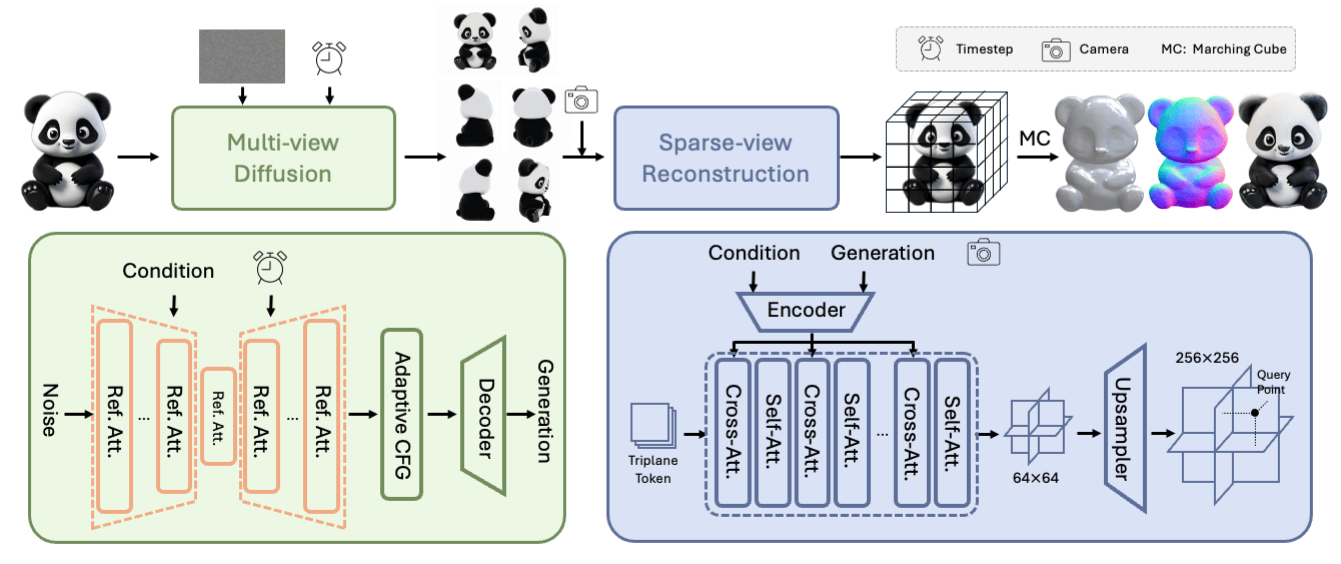
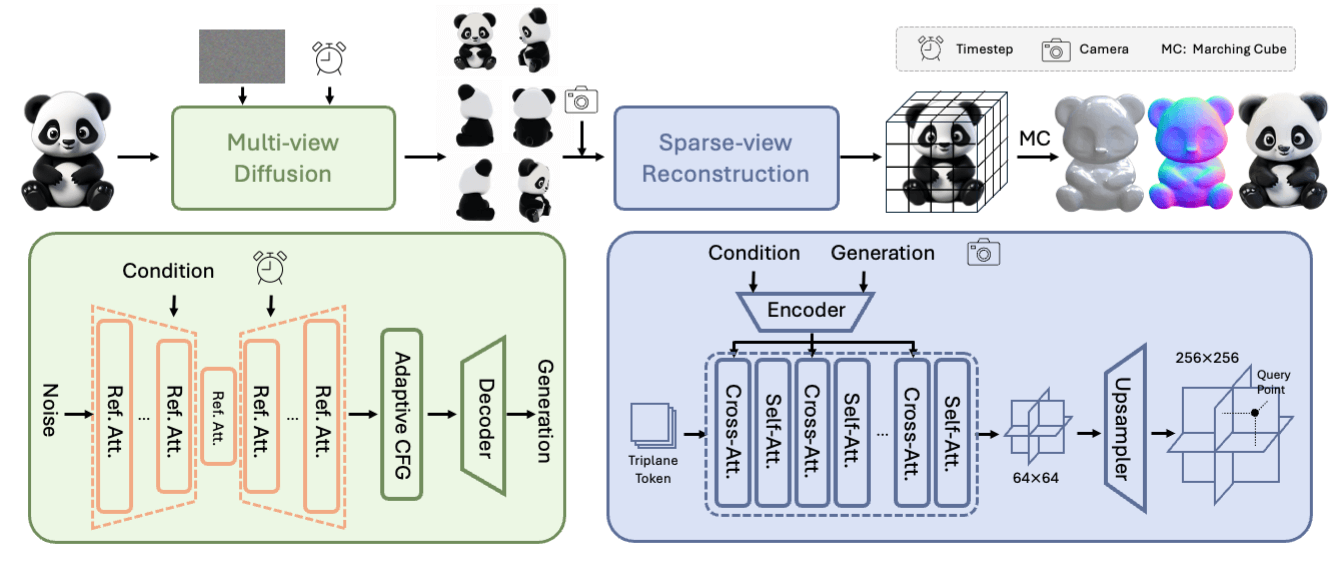
Tencent has released Hunyuan3D 2.0, high-resolution textured 3D asset generation. It outperforms existing models in geometry detail, texture quality, and condition alignment, making it a transformative step in 3D asset creation.
⚙️ The Details
→ Hunyuan3D 2.0 integrates two primary components: Hunyuan3D-DiT, a shape-generation model utilizing diffusion transformers, and Hunyuan3D-Paint, a texture synthesis model leveraging multi-view geometry and diffusion techniques. Together, they ensure seamless generation of detailed, textured 3D assets.
→ The shape generation pipeline starts with Hunyuan3D-ShapeVAE, which compresses 3D shapes into compact latent tokens. This improves reconstruction fidelity and detail.
→ Hunyuan3D-Paint creates multi-view texture maps, ensuring alignment with input images while maintaining multi-view consistency.
→ The system is publicly released as an open-source project, with code and pre-trained weights available. This fills a critical gap in the 3D open-source community for scalable foundation models.
→ Users can access Hunyuan3D-Studio, a platform for 3D asset editing, animation, and stylization, catering to professionals and beginners alike.
The model is available in Huggingface and also there’s a live demo and a Github Repo.
Key Points of Tencent Hunyuan Community License:
License excludes the EU, UK, and South Korea.
Allows non-transferable, royalty-free use, modification, and distribution of Tencent Hunyuan works within the territory.
Prohibits use for improving other AI models, certain harmful activities, or military purposes.
IP Ownership: Outputs are owned by users; derivative works require compliance.
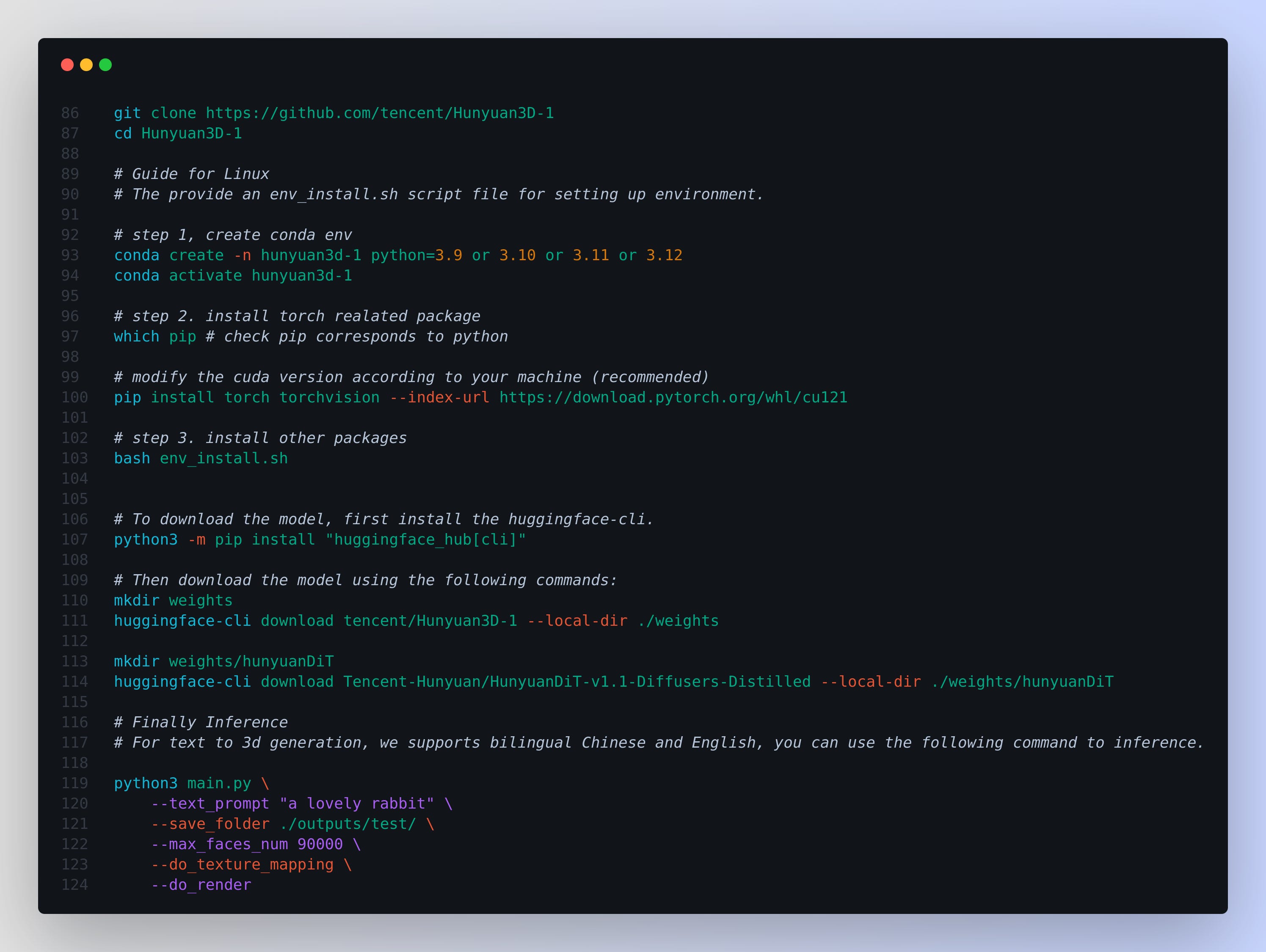
Installation guide - Get started very eazily
🏆 Minimax Unveils T2A-01-HD, The Text-To-Audio With Unmatched Emotional Depth, And Multilingual Authenticity

🎯 The Brief
MiniMax has launched T2A-01-HD, under the Hailuo Audio HD brand, a revolutionary Text-to-Audio model offering highly realistic, customizable, and multilingual voice synthesis. It features emotional intelligence, fluency in 17+ languages, and voice cloning with just 10 seconds of input, making it a significant advancement in synthetic voice technology.
⚙️ The Details
→ Hailuo Audio HD allows precise voice cloning by replicating subtle emotional nuances and tones from just 10 seconds of audio.
→ A library of 300+ pre-built voices is available, categorized by language, age, gender, accent, and style. Users can also fine-tune pitch, speed, and emotional tone, along with professional effects like room acoustics and filters.
→ It supports 17+ languages, including English (US, UK, India, Australia), Chinese (Mandarin, Cantonese), Spanish, French, Arabic, and more, with regional accents and idiomatic speech.
→ Emotional intelligence is a standout, featuring automatic emotion detection or manual control, enabling precise expression for storytelling, branding, and interactive content.
→ Applications span entertainment, customer service, education, and marketing, such as audiobook narration, virtual assistants, and e-learning.
→ API integration is available for developers, with the platform offering a free trial. Pricing details were not mentioned.
🎧 Try It for FREE: https://hailuo.ai/audio
🔗 API Platform: https://intl.minimaxi.com
🗞️ Byte-Size Brief
The code for that groundbreaking rStar-Math paper now open-souced by Microsoft. This technique upgrades small models to outperform OpenAI’s o1-preview at math problems. By using Monte Carlo Tree Search (MCTS) and self-evolution strategies. Applied to models like Qwen-7B and Phi3-mini, it surpassed OpenAI’s o1-preview on key benchmarks, such as improving Qwen2.5-Math-7B’s accuracy on the MATH dataset from 58.8% to 90.0%.
Titan released a Huggingface space Model Memory Calculator to help you estimate the memory footprint of your model and the maximum batch size/sequence length combination you can run on your device.
Meta opened sourced the code for their groundbreaking research work - Coconut (learning continuous latent CoT). Paper “Training Large Language Models to Reason in a Continuous Latent Space”. Which can significantly boost LLM's reasoning power. Basically the paper says, imagine if your brain could skip words and share thoughts directly - that's what this paper achieves for AI. By skipping the word-generation step, LLMs can explore multiple reasoning paths simultaneously.
ComfyUI now supports Nvidia Cosmos, specifically the 7B and 14B text to video and image to video diffusion models. So now, you can turn text or images into smooth, high-res videos with Nvidia Cosmos on ComfyUI. Supported in ComfyUI, Nvidia Cosmos models are memory-friendly, work on 12GB GPUs, and excel in creating dynamic 121-frame videos with precise control.
Firecrawl launched "Extract" - turns any website into structured data with just one prompt. And you can do this from one or multiple URLs, including wildcards. Using natural language prompts to extract structured data, now available in open beta with 500K free tokens. It offers a no-code integration via Zapier, supports Python and Node.js SDKs, and adapts to website changes without rewriting scripts. Supports gathering datasets for training or testing, handling multilingual websites, and dynamic content like prices and inventory.
Moonshot AI (an AI lab based in China) introduced Kimi k1.5, a multi-modal reasoning LLM utilizing reinforcement learning with long and short-chain-of-thought (CoT). with up to 128k tokens context-window. As per their self-published report, achieves SOTA performance on benchmarks like AIME (77.5), MATH-500 (96.2), and LiveCodeBench (47.3).
🧑🎓 Deep Dive Tutorial
DeepSeek-R1 - Under-the-hood peek into how Group Relative Policy Optimization (GRPO) and Cold-start training changed everything

I wrote in detail exploring DeepSeek-R1's innovative RL training techniques for reasoning in LLMs.
📚 Key Takeaways
Reinforcement learning (RL) for training LLMs without supervised fine-tuning (SFT).
Group Relative Policy Optimization (GRPO), a lightweight RL method replacing traditional critic networks.
Cold-start training to develop reasoning without human-labeled data or SFT reliance.
Rule-based rewards ensuring accurate and structured outputs, avoiding pitfalls of learned reward models.
Emergent reasoning behaviors like self-reflection and iterative improvement from reward-driven optimization.
Distillation techniques for transferring reasoning capabilities to smaller models like Qwen and Llama.
Efficient methods to outperform larger models on tasks like math and coding using compact architectures.