
🥊 The AI cold war is heating up: OpenAI Hits the Panic Button
Sam Altman signals Code Red, Anthropic exposes $4.6M exploit, Morgan Stanley bets on 12M TPUs, and Artificial Analysis drops a new AI Openness Index.

Read time: 9 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (2-Dec-2025):
🥊 The AI cold war is heating up: OpenAI Hits the Panic Button as Sam Altman Declares ‘Code Red’ signalling massive competition from Google and Others.
🚫 New Anthropic study shows AI agents find $4.6M in blockchain smart contract exploits
💰Morgan Stanley put out a report today saying that they forecast Alphabet selling approximately 12 million TPUs
🔍 The Artificial Analysis launched a new Openness Index
🥊 The AI cold war is heating up: OpenAI Hits the Panic Button as Sam Altman Declares ‘Code Red’ signalling massive competition from Google and Others.

OpenAI is prioritizing upgrades to ChatGPT after a “code red” memo from the CEO, and planned ads plus other side projects are paused while a new reasoning model aimed at matching or beating Gemini 3 is reportedly coming next week.
The Information and the Wall Street Journal reported Altman has urged staffers to work on ChatGPT’s “day-to-day experience,” including improvements to personalization features, faster and more reliable responses, and the ability to “answer a wider range of questions.”
Competition from Gemini 3 has suddenly raised the bar on long-context stability, multilingual accuracy, and integrated planning across apps.
Google has pushed Gemini 3 past GPT-5 on benchmarks, trained it on its own tensor processing unit chips rather than external GPUs, and plugged it into search and Android, helping the Gemini app reach about 650mn monthly users.
Anthropic on the other hand, built super strong code assistants with huge trust base on enterprise accounts, and is now raising at a valuation above $300bn, giving corporate buyers a serious non OpenAI option.
OpenAI still has a huge 800mn+ weekly ChatGPT users, but it is sprinting on many products while committing around $1.4tn over 8 years for compute with partners like Nvidia and Oracle, a figure far above current revenue that pushes the company to rely on subscriptions, enterprise deals and Sora style ads in markets where the big ad platforms already dominate.
In the 2 weeks since the Gemini launch, ChatGPT unique daily active users (7-day average) are down -6%.

🚫 New Anthropic study shows AI agents find $4.6M in blockchain smart contract exploits
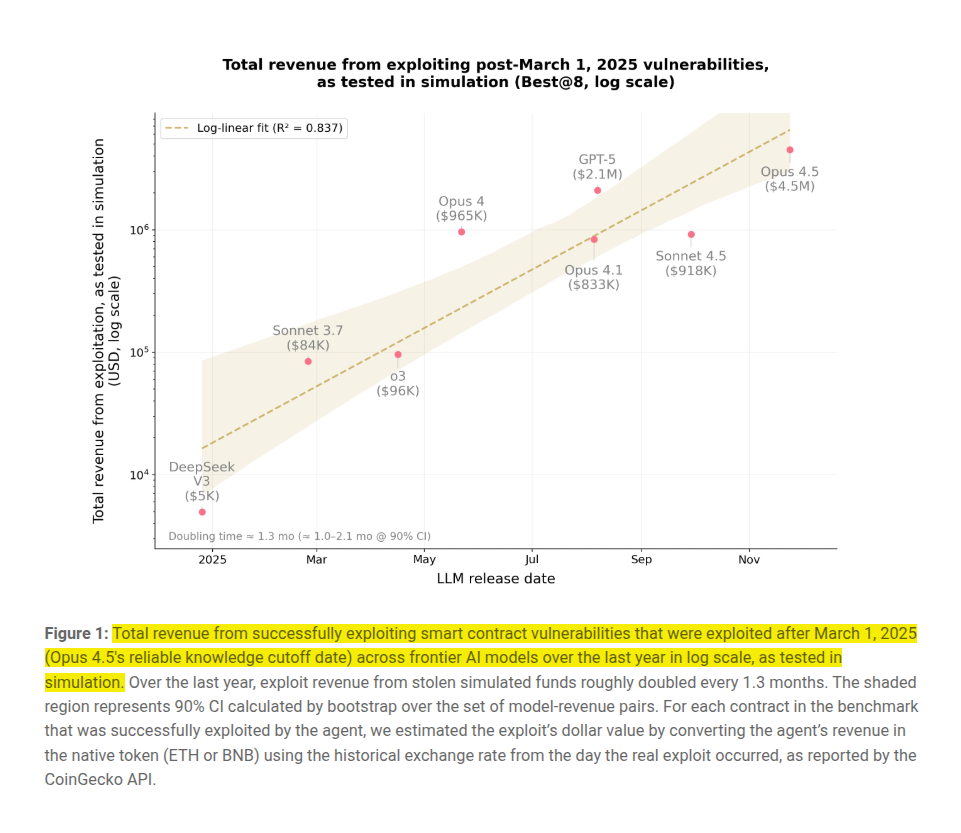
Anthropic basically asked, “What would an AI do in a blockchain simulator?” That question turned into SCONE-bench, a tool that recreates real smart-contract hacks and totals the results in dollars.
When tested against vulnerabilities from after their knowledge cutoff, models like Claude Opus 4.5 and GPT-5 found exploits worth a collective $4.6 million.
Across 10 frontier models, agents exploit 207 problems for about $550M simulated revenue, and on the 34 post March-25 cases success reaches 56% with total revenue near $4.6M.
Sonnet 4.5 and GPT-5 scan 2,849 Binance Smart Chain token contracts, find 2 previously unknown bugs worth $3,694, and spend $3,476 on GPT-5 API calls, about $1.22 per scan.
Median token use per successful exploit drops about 70% across Claude generations, making scans cheaper and shrinking the window to patch vulnerable contracts before automated agents hit them.
Even more concerning is that these agents discovered two zero-day vulnerabilities in completely unrelated, live contracts.
A zero-day vulnerability is a software flaw that is unknown to the developers, meaning hackers can attack it immediately before anyone has time to build a fix.
The study proves that this kind of automated theft is highly profitable because the cost of the attack is negligible.
Scanning nearly 3,000 contracts using GPT-5 cost only $3,476 in API fees, which breaks down to just $1.22 per agent run.
This effectively establishes a lower bound for the economic harm AI can cause, as the potential revenue from theft vastly outweighs the compute costs to find the bugs.
All exploits were tested in a simulated sandbox environment, so no real money was actually stolen from live users.
💰 Morgan Stanley put out a report saying that they forecast Alphabet selling approximately 12 million TPUs

TPUs are now being modeled as a huge new hardware revenue line if the company sells them to outside customers instead of keeping them only for internal workloads. Morgan Stanley now expects Google to ship 5 million TPUs in 2027 and 7 million in 2028, and estimates that every 500000 units sold externally could add about $13B revenue, 11% to Google Cloud, and roughly 3% or $0.40 to Alphabet EPS.
TPUs are Google’s in house AI accelerators designed around matrix math and large batch parallelism, so selling them directly means exposing the same silicon that powers internal products like Search and Gemini to any enterprise that can integrate with the stack. This turns Google from a pure AI cloud provider into a merchant accelerator vendor, which pushes it into more direct competition with Nvidia on raw price performance, availability, and roadmap transparency for big training and inference clusters. For AI customers, a serious TPU roadmap in the open market would add a second large scale ecosystem for accelerators, with different compiler tools, different networking assumptions, and potentially better cost per unit of useful compute on some workloads.
🔍 Artificial Analysis launched a new Openness Index for AI Models.

The newly launched Artificial Analysis Openness Index is a standardized and independently assessed measure of AI model openness across availability and transparency.
Scores AI models on availability and transparency, with OLMo leading and many closed models scoring low. Almost all the top ranking models are from China.
The chart breaks the score into 2 parts, model availability and 3 transparency buckets covering methodology, pre-training data, and post-training data. Each bar shows how much a model gets from those components up to 18, then rolled into the overall index.
OLMo reaches 16/18 on components because it releases weights, code, training details, and datasets, matching its overall index lead of 89.
Nemotron Nano 9B v2 performs well on documentation and datasets, landing 67, which is high among commercial labs.
Open weights without method or data barely move the transparency bars, for example releases like gpt-oss-120B score on weights and license but have thin disclosure.
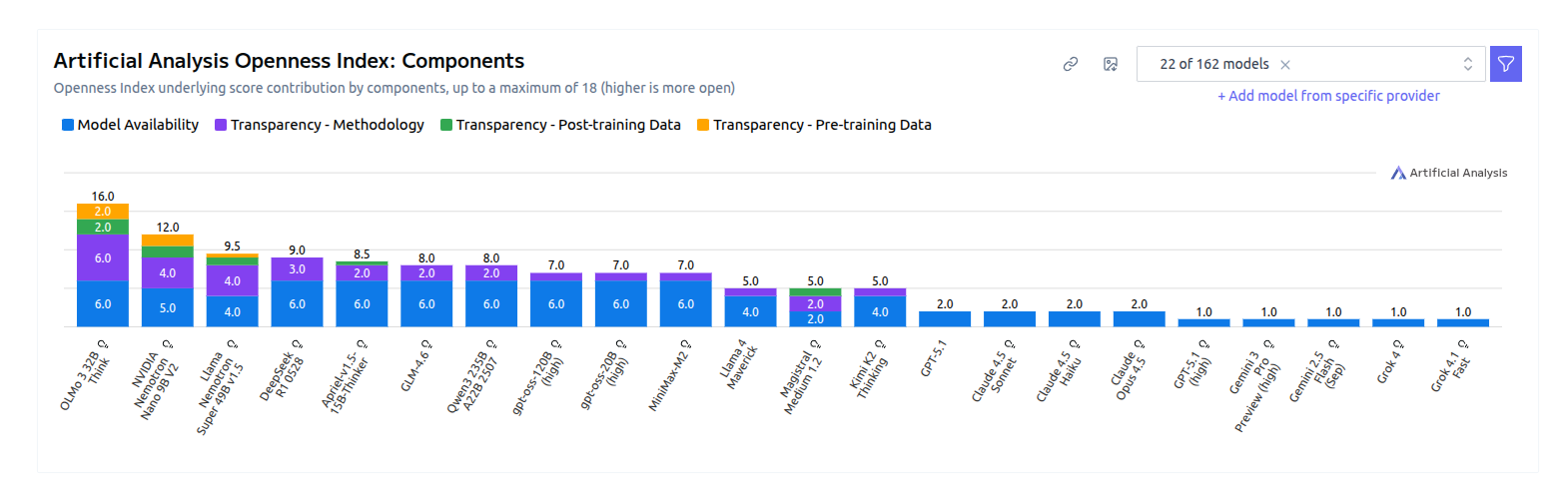
Closed models appear too, and most sit at 1-5 on components because method and data visibility are minimal.
The design rewards full reproducibility - i.e. permissive license, weights, training code, and both data phases, anything missing drags the score.
That’s a wrap for today, see you all tomorrow.