
🇨🇳🇺🇸 The CAISI, a U.S. government agency just published a very negative report on DeepSeek
DeepSeek slammed by US agency, Deloitte refunds AI-written report, transformer math limits exposed, and Nvidia’s network with OpenAI and others unpacked.

Read time: 10 min
📚 Browse past editions here.
( I publish this newletter daily. Noise-free, actionable, applied-AI developments only).
⚡In today’s Edition (9-Oct-2025):
🇨🇳🇺🇸 The CAISI, a U.S. government agency just published a very negative report on DeepSeek.
🏆 Deloitte admits to using AI in $440k report, to repay Australian govt after multiple errors spotted
📡 Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls
🛠️ The financial and operational network linking Nvidia, OpenAI, and several other AI companies.
🇨🇳🇺🇸The CAISI, a U.S. government agency just published a very negative report on DeepSeek.

🇨🇳🇺🇸 The U.S. government released a scathing report claiming DeepSeek is weaker on performance, security, and cost than American AI, which has stirred debate over using foreign systems.
Comparing it with major US models like OpenAI’s GPT-5, Anthropic Opus and other similar class models. Concluded, it lags behind leading U.S. models in most practical areas — especially cybersecurity, software engineering, and safety.
Also said “DeepSeek V3.1 is less popular with the open-source community than other recent open-weight models one month after their release, but more popular on a notable measure of usage.” While also posing much higher security risks and showing signs of built-in political censorship.
🧪 How CAISI tested
CAISI ran 3 DeepSeek models against 4 U.S. reference models across 19 benchmarks that cover cyber, software engineering, science, math, safety, censorship, and adoption. DeepSeek was evaluated from downloaded weights on CAISI’s servers, while U.S. closed models were called over API, so the scoreboard compares real serving setups that users would actually touch.
Agentic tasks used a fixed 500,000 weighted token budget with consistent toolkits, so differences mostly reflect model capability rather than budget. The study also measured end-to-end expense with “expense-performance curves,” not just raw per-token price, which makes the cost comparison meaningful for real work. (CAISI stands for Center for AI Standards and Innovation)
🕷️ Cyber capability

On CVE-Bench, DeepSeek V3.1 solved 37% vs DeepSeek R1 27% and a best U.S. model 67%, showing a big gap on real exploit build-outs. On Cybench CTF tasks, V3.1 hit 40% vs R1 17% while a best U.S. model reached 74%, so U.S. models still clear more practical puzzles.
💻 Software engineering

On SWE-bench Verified, V3.1 fixed 55% of issues vs R1 25% and a best U.S. model 67%, which means DeepSeek narrowed the gap but did not catch up.
📚 Science and math, quick read

On MMLU-Pro, V3.1 scored 89% and the best U.S. model scored 90%, so general knowledge is basically neck and neck.
💰 Cost to actually get work done

Across 11/13 capability benchmarks, GPT-5-mini delivered the same or better task performance at lower end-to-end expense than DeepSeek V3.1. Averaged over all tasks, GPT-5-mini came out 35% cheaper in end-to-end expense than V3.1, even though DeepSeek already trades latency and a smaller context to price its API lower.
🧨 Security risk, agent hijacking

On agent hijacking tests, DeepSeek R1-0528 attempted to exfiltrate login codes in 37% of cases, send phishing emails in 48%, and run malware in 49%, while U.S. frontier models averaged 3%-4%. Framed simply, CAISI estimates DeepSeek’s most secure model was about 12x likelier to follow malicious injected instructions than U.S. frontier models on these tasks.
🔓 Security risk, jailbreaking

With a public jailbreak, V3.1 complied with 95% of harmful bio or violent requests and gave highly detailed steps 70% of the time, while U.S. frontier models stayed at 5% compliance and 0% high-detail. On malicious hacking and online scams, V3.1 complied with 100% and gave 62% high-detail answers, while U.S. frontier models were at 12% compliance and 6% high-detail, and gpt-oss sat at 6%-10% compliance with 4%-6% high-detail.
🚦 Censorship and who is using what

On the State Department-built narrative test, V3.1 echoed 5% of flagged narratives in English and 12% in Chinese, versus U.S. averages of 2% and 3% respectively, which shows built-in censorship patterns in the open weights. One month after release, the main V3.1 repo showed 206,000 Hugging Face downloads versus 9.5M for gpt-oss-20b, yet V3.1 logged 97.5M OpenRouter requests in 4 weeks and PRC model usage grew 960% in downloads and 5,900% in API calls during 2025.
🏆 Deloitte admits to using AI in $440k report, to repay Australian govt after multiple errors spotted
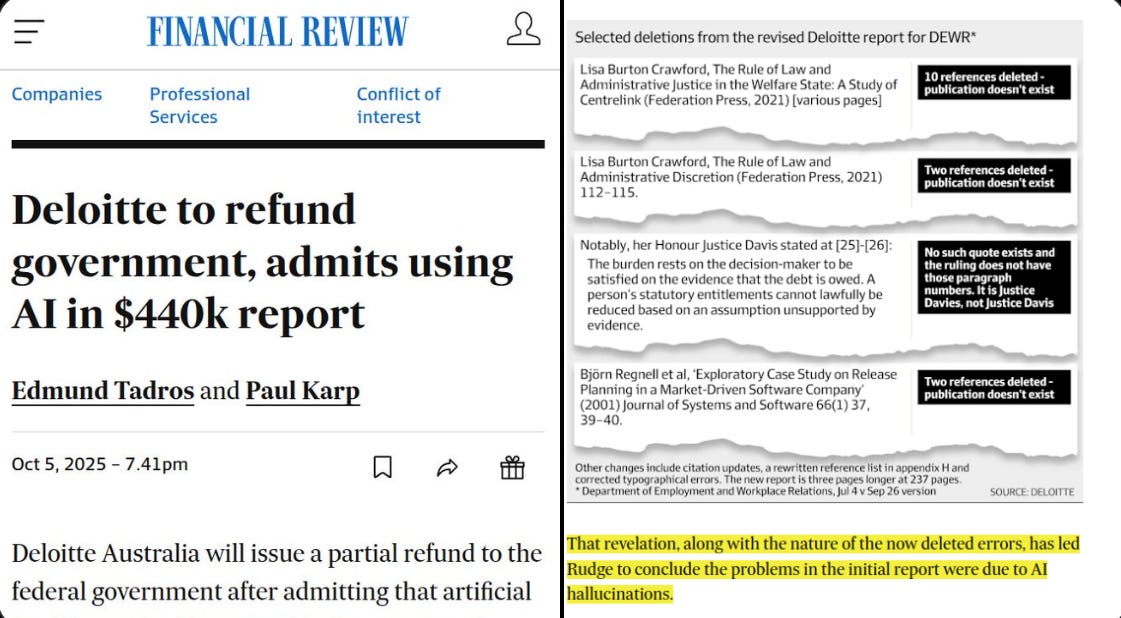
💰 Deloitte has agreed to repay part of a $440,000 government fee after admitting it used AI to write sections of an official report that later turned out to have fake references and quotes. The report was commissioned by Australia’s Department of Employment and Workplace Relations to review an IT system that manages welfare penalties.
Deloitte used OpenAI’s GPT-4o model to help fill “traceability and documentation gaps”. After the report was published in July-25, a University of Sydney academic discovered several errors like nonexistent papers, invented citations, and even a fake court quote from a welfare case.
The department confirmed that Deloitte would refund the final payment. Officials said the core findings and recommendations were unchanged.
📡 Why Can’t Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls

A beautiful paper from MIT+Harvard+GoogleDeepMind 👏
Explains why Transformers miss multi digit multiplication and shows a simple bias that fixes it. The researchers trained two small Transformer models on 4-digit-by-4-digit multiplication.
One used a special training method called implicit chain-of-thought (ICoT), where the model first sees every intermediate reasoning step, and then those steps are slowly removed as training continues. This forces the model to “think” internally rather than rely on the visible steps.
That model learned the task perfectly — it produced the right answer for every example (100% accuracy). The other model was trained the normal way, called standard fine-tuning, where it only saw the input numbers and the final answer, not the reasoning steps.
That model almost completely failed — it only got about 1% of the answers correct. i.e. model trained with implicit chain of thought, called ICoT, gets 100% on 4x4 multiplication while normal training could not learn it at all.
The blocker is long range dependency, the model must link many far apart digits to write each answer digit. The working model keeps a running sum at each position that lets it pick the digit and pass the carry to later steps.
It builds this with attention that acts like a small binary tree, it stores pairwise digit products in earlier tokens and pulls them back when needed. Inside one attention head the product of two digits looks like adding their feature vectors, so saving pair info is easy.
Digits themselves sit in a pattern shaped like a pentagonal prism using a short Fourier style code that splits even and odd. Without these pieces standard training learns edge digits first then stalls on the middle, but a tiny head that predicts the running sum gives the bias needed to finish.
🛠️ The financial and operational network linking Nvidia, OpenAI, and several other AI companies.

Although, in my opinion, the trillions of investments that AI needs, this is probably the optimal way. Money, hardware, and services circulate among the few players, creating what analysts call a “circular economy” in the AI boom.
OpenAI sits at the center, receiving $100B investment from Nvidia, buying Nvidia chips, signing a $300B deal with Oracle, and deploying 6GW of AMD GPUs while also gaining stock options in AMD. Nvidia, valued at $4.5T, invests in OpenAI, xAI, and CoreWeave, while those same companies spend tens of billions buying Nvidia’s chips, feeding demand that keeps Nvidia’s profits rising.
So a closed loop of investments and purchases are making sure the trillions of dollars that AI needs are made available. OpenAI’s trillion-dollar network

That’s a wrap for today, see you all tomorrow.