The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
✨ Microsoft 1-bit era paper (released in Feb) is really a masterpiece.

✨ Microsoft 1-bit era paper (released in Feb) is really a masterpiece.
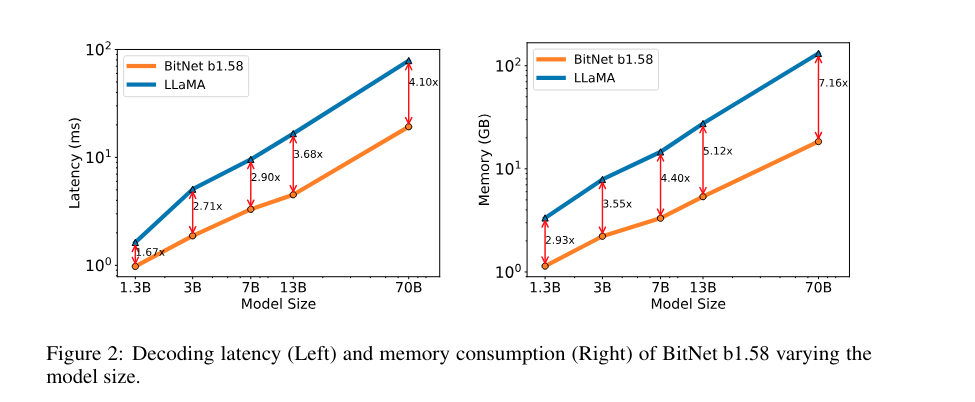
BitNet b1.58 70B was 4.1 times faster and 8.9 times higher throughput capable than the corresponding FP16 LLama.
📌 Requires almost no multiplication operations for matrix multiplication and can be highly optimized.
📌 BitNet b1.58 is a 1-bit LLM, where every single parameter (or weight) of the LLM is ternary {-1, 0, 1}.
They introduce a significant 1-bit LLM variant called BitNet b1.58, where every parameter is ternary, taking on values of {-1, 0, 1}. We have added an additional value of 0 to the original 1-bit BitNet, resulting in 1.58 bits in the binary system.
📌 The term "1.58 bits" refers to the information content of each parameter.
What "1.58 bits" means is that it is log base 2 of 3, or 1.5849625... Actually decoding data at that density takes a lot of math.Since each parameter can take one of three possible values (-1, 0, 1), the information content is log2(3) ≈ 1.58 bits.
Here all weight values are ternary, taking on values {-1, 0, 1}.
Its quantization function is absmean in which, the weights are first scaled by their average absolute value and then rounded to the nearest integer ε {-1,0,1}.
It is an efficient extension of 1-bit BitNet by including 0 in model parameters.
So BitNet b1.58 is based upon BitNet architecture (replaces nn.linear with BitLinear).
It is highly optimized as it removes floating point multiplication overhead, involving only integer addition (INT-8), and efficiently loads parameters from DRAM.
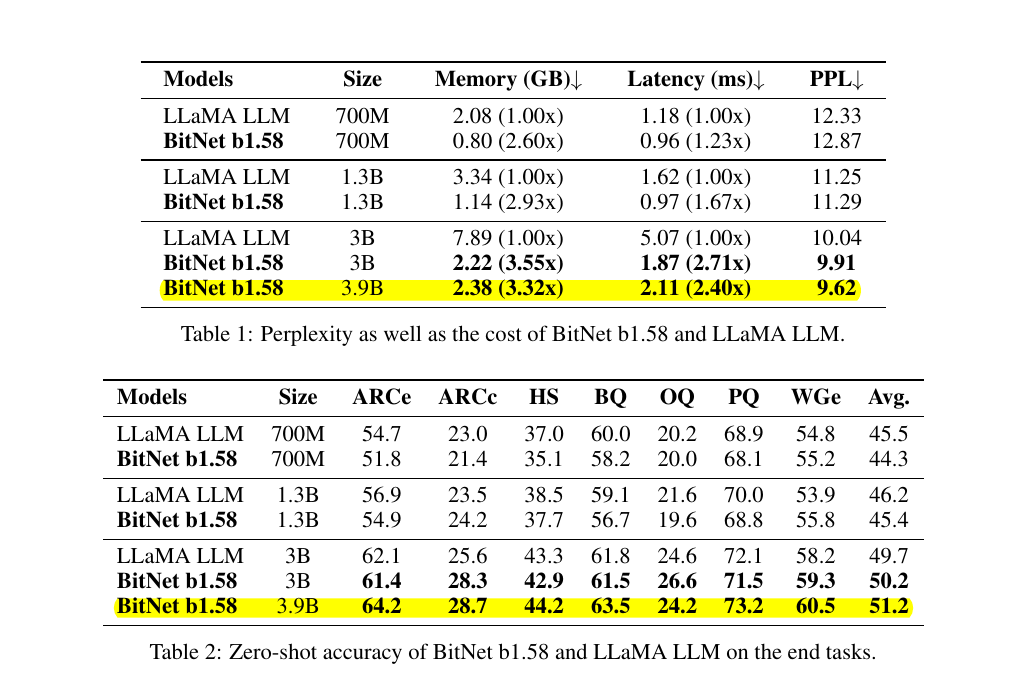
Can b1.58 LLMs replace Float 16 Models?
The authors of BitNet b1.58 compared it with a reproduced FP16-LLaMA by pretraining both models with the same configurations and evaluated the zero-shot performance on various language tasks. The results reveal that BitNet b1.58 starts to match LLaMA at 3B model size and continues to narrow the performance gap onwards, outperforming full-precision models on perplexity and end-task results. Particularly, a 3.9B BitNet b1.58 was 2.4 times faster and consumed 3.32 times less memory than LLaMA 3B, thus reducing memory and latency costs. This demonstrates that BitNet b1.58 is capable of competing with the full-precision LLMs.