

Some of the most discussed AI papers of from last week (1-Dec-2024 to 7-Dec-2024):
JetFormer: An Autoregressive Generative Model of Raw Images and Text
DeMo: Decoupled Momentum Optimization
Reverse Thinking Makes LLMs Stronger Reasoners
NVILA: Efficient Frontier Visual Language Models
Navigation World Models
Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models
Best-of-N Jailbreaking
Evaluating Language Models as Synthetic Data Generators
o1-Coder: an o1 Replication for Coding
PaliGemma 2: A Family of Versatile VLMs for Transfer
KV Shifting Attention Enhances Language Modeling
Survey of different Large Language Model Architectures: Trends, Benchmarks, and Challenges
LMAct: A Benchmark for In-Context Imitation Learning with Long Multimodal Demonstrations
🗞️ "JetFormer: An Autoregressive Generative Model of Raw Images and Text"

Direct pixel modeling meets transformer architecture for unified multimodal generation.
JetFormer introduces a unified architecture that directly models raw images and text without pre-trained components. It combines a normalizing flow model with an autoregressive transformer, trained end-to-end to maximize data likelihood while maintaining high-fidelity image generation capabilities.
🤔 Original Problem:
Current multimodal models rely heavily on pre-trained components like VQ-VAEs for image processing, which can limit performance and flexibility. Direct pixel-space modeling with transformers is computationally expensive and struggles with image coherence.
🔧 Solution in this Paper:
→ JetFormer uses a normalizing flow model to convert images into soft tokens that can be processed by an autoregressive transformer.
→ The flow model serves as both encoder and decoder, eliminating the need for separate pre-trained components.
→ A noise curriculum during training helps prioritize high-level image structure by gradually reducing noise levels.
→ The model manages redundancy in natural images by factoring out less important dimensions.
💡 Key Insights:
→ End-to-end training of flow models with transformers is viable for joint image-text modeling
→ Noise curriculum significantly improves image generation quality
→ Redundancy management through dimension factoring reduces computational burden
📊 Results:
→ Achieves FID score of 6.64 on ImageNet256, competitive with VQ-VAE based methods
→ Demonstrates strong text-to-image generation capabilities without pre-trained components
→ Maintains good log-likelihood while generating coherent images
🗞️ "DeMo: Decoupled Momentum Optimization"

DeMo slashes GPU communication costs while maintaining model quality through smart momentum handling.
DeMo introduces a novel optimizer that drastically reduces communication between GPUs during LLM training by decoupling momentum updates across accelerators, while maintaining or exceeding model performance compared to AdamW optimizer.
🤖 Original Problem:
Training LLMs requires massive communication between GPUs to synchronize gradients, demanding expensive high-speed interconnects and constraining all accelerators to be in the same data center.
🔧 Solution in this Paper:
→ DeMo leverages the insight that gradients and optimizer states during training exhibit high redundancy and are highly compressible.
→ It uses Discrete Cosine Transform to efficiently extract and synchronize only the most significant "fast-moving" components of momentum tensors.
→ The algorithm decouples momentum updates across accelerators, allowing controlled divergence in optimizer states.
→ Slow-moving components are accumulated locally and gradually transmitted over time.
💡 Key Insights:
→ Fast-moving momentum components show high spatial correlation and concentrate energy in few principal components
→ Fast components need immediate application while slow components benefit from temporal smoothing
→ Slow-moving components, despite high variance, are crucial for long-term convergence
📊 Results:
→ Reduced inter-accelerator communication by several orders of magnitude (2416.6 MB/step to 3.44 MB/step for 1B model)
→ Matched or exceeded AdamW performance on Hellaswag, ARC-Easy, and PiQA benchmarks
→ No noticeable slowdown in convergence or training loss
🗞️ "Reverse Thinking Makes LLMs Stronger Reasoners"

Teaching LLMs to think backward makes them better at reasoning forward
This paper introduces REVTHINK, a framework that enhances LLMs' reasoning abilities by teaching them to think both forward and backward. Unlike previous approaches that only use backward reasoning for verification, REVTHINK incorporates it during training, leading to better performance across diverse reasoning tasks.
🤔 Original Problem:
→ Current LLMs struggle with complex reasoning tasks because they only think in one direction (forward)
→ Existing backward reasoning methods are limited to mathematical domains and only used for verification at test time
🔧 Solution in this Paper:
→ REVTHINK augments training data using a teacher model to generate forward reasoning, backward questions, and backward reasoning
→ It trains student models with three objectives: generate forward reasoning, create backward questions, and solve backward questions
→ The framework validates data points by checking forward reasoning accuracy and backward reasoning consistency
→ At test time, the model only performs forward reasoning, maintaining computational efficiency
💡 Key Insights:
→ Backward thinking can be effectively applied beyond just mathematical reasoning
→ Training with bidirectional reasoning is more effective than using it only for verification
→ Smaller models trained with REVTHINK can outperform larger models using conventional methods
→ The framework shows strong sample efficiency, achieving better results with just 10% of training data
📊 Results:
→ 13.53% improvement over zero-shot performance
→ 6.84% gain over standard knowledge distillation methods
→ 7B model outperforms 176B model's zero-shot performance
→ 40% reduction in average delay compared to legacy methods
🗞️ "NVILA: Efficient Frontier Visual Language Models"

Scale up visual processing, then compress it - that's how NVILA saves GPU power
NVILA introduces an efficient family of visual language models that optimize both accuracy and efficiency through a "scale-then-compress" approach, reducing training costs by 4.5x while maintaining competitive performance with leading models. The paper addresses the critical challenge of making visual language models more resource-efficient without compromising their capabilities.
🤔 Original Problem:
→ Current visual language models are expensive to train, requiring up to 400 GPU days for a 7B model.
→ Fine-tuning requires over 64GB GPU memory, beyond most consumer hardware.
→ Deployment on edge devices is constrained by limited computational resources.
⚡ Solution in this Paper:
→ NVILA uses a "scale-then-compress" strategy that first increases spatial and temporal resolution, then compresses visual tokens.
→ The model employs Dynamic-S2 for adaptive image processing with varying aspect ratios.
→ It introduces DeltaLoss for dataset pruning, reducing training data while maintaining performance.
→ FP8 training accelerates computation while preserving accuracy.
→ Specialized quantization techniques optimize both vision encoder and language model components.
🔍 Key Insights:
→ Higher resolution processing followed by token compression achieves better accuracy-efficiency trade-off
→ Temporal averaging effectively reduces video token redundancy
→ Dataset pruning can halve training data without significant performance loss
📊 Results:
→ 4.5x reduction in training costs
→ 3.4x decrease in fine-tuning memory usage
→ 1.6-2.2x improvement in pre-filling latency
→ 1.2-2.8x boost in decoding throughput
🗞️ "Auto-RAG: Autonomous Retrieval-Augmented Generation for Large Language Models"

Auto-RAG transforms LLMs into autonomous researchers that know when to dig deeper.
Auto-RAG is an autonomous iterative retrieval system that leverages LLMs' reasoning capabilities to make intelligent decisions about when and what to retrieve. Unlike existing methods that rely on manual rules or few-shot prompting, Auto-RAG enables LLMs to independently plan retrievals and refine queries through multi-turn dialogues until sufficient information is gathered.
🤔 Original Problem:
Current Retrieval-Augmented Generation (RAG) systems face limitations in handling complex queries that require multiple information lookups. Existing iterative retrieval methods depend heavily on manual rules and few-shot prompting, which adds computational overhead and underutilizes LLMs' reasoning abilities.
🔧 Solution in this Paper:
→ Auto-RAG introduces a multi-turn dialogue framework between LLM and retriever for autonomous decision-making during retrieval
→ The system employs reasoning for retrieval planning, knowledge extraction, and query refinement
→ It automatically synthesizes reasoning-based instructions for training LLMs in iterative retrieval
→ The model continues retrieving information until it has sufficient knowledge to answer the user's question
→ Auto-RAG expresses the retrieval process in natural language, improving interpretability
💡 Key Insights:
→ LLMs can effectively make autonomous decisions about when and what to retrieve through reasoning
→ The number of iterations can be dynamically adjusted based on question complexity
→ External knowledge should be provided before parametric knowledge for optimal performance
→ The system maintains high interpretability while achieving superior performance
📊 Results:
→ Outperforms existing methods across 6 benchmarks with limited training data
→ Achieves 44.3% average performance compared to 30.2-38.4% for baselines
→ Demonstrates better efficiency with fewer retrieval iterations
🗞️ "Best-of-N Jailbreaking"

BoN Jailbreaking: A simple algorithm that systematically breaks AI safety through random variations.
Random input mutations reveal fundamental weaknesses in AI safety mechanisms.
Best-of-N Jailbreaking introduces a simple yet powerful method to bypass AI safety measures across text, vision, and audio modalities. By repeatedly sampling variations of harmful prompts with random augmentations until finding one that succeeds, it achieves high attack success rates on frontier LLMs like GPT-4 and Claude.
🔒 Original Problem:
→ Current AI systems have safety measures to prevent harmful outputs, but these defenses can be bypassed through carefully crafted inputs called "jailbreaks". Finding reliable jailbreak methods that work across different input types remains challenging.
🛠️ Solution in this Paper:
→ Best-of-N (BoN) Jailbreaking repeatedly samples variations of a harmful prompt using modality-specific augmentations until finding one that bypasses safety measures.
→ For text, it applies random capitalization, character scrambling and noising.
→ For images, it varies text color, size, font and position on different backgrounds.
→ For audio, it modifies speed, pitch, volume and adds background noise to spoken requests.
💡 Key Insights:
→ Attack success improves with more samples following a power-law scaling pattern
→ Successful jailbreaks stem from input variance rather than specific augmentation patterns
→ Combining BoN with other techniques like optimized prefixes further improves effectiveness
📊 Results:
→ 89% success rate on GPT-4 and 78% on Claude with 10,000 text samples
→ 56% success on GPT-4 vision and 72% on GPT-4 audio
→ 28x improvement in sample efficiency when combined with other techniques
🗞️ "Evaluating Language Models as Synthetic Data Generators"

Not all powerful LLMs are good at generating training data - here's how to measure it.
This paper introduces AgoraBENCH, a comprehensive benchmark for evaluating how well LLMs generate synthetic training data. Through extensive experiments generating 1.26 million training instances using 6 LLMs and training 99 student models, it reveals distinct strengths among different LLMs in data generation capabilities.
Original Problem 🤔:
While synthetic data generation using LLMs is becoming crucial for model training, there's no standardized way to evaluate different LLMs' abilities as data generators. Current research focuses on developing generation methods rather than comparing LLMs' generation capabilities.
Solution in this Paper 🛠️:
→ AgoraBENCH provides standardized settings and metrics across nine configurations, combining three domains (math, instruction-following, code) with three data generation methods.
→ It introduces Performance Gap Recovered (PGR) metric to measure relative improvement of models trained on synthetic data.
→ The benchmark evaluates 6 LLMs including GPT-4o, Claude-3.5-Sonnet, and Llama-3.1 variants.
Key Insights from this Paper 💡:
→ Different LLMs show distinct strengths - GPT-4o excels at generating new problems while Claude-3.5-Sonnet performs better at enhancing existing ones
→ An LLM's data generation ability doesn't necessarily correlate with its problem-solving capability
→ Multiple intrinsic features collectively indicate data generation quality
Results 📊:
→ GPT-4o achieves highest PGR in 5 out of 9 settings
→ Top-5 principal components explain 93.4% variance in PGR values
→ JSON format shows 4.45% lower performance compared to free-form generation
🗞️ "o1-Coder: an o1 Replication for Coding"

Self-improving AI system that writes better code by learning from its own mistakes.
O1-CODER is a novel framework that replicates OpenAI's O1 model specifically for coding tasks. It combines reinforcement learning with Monte Carlo Tree Search to enhance System-2 thinking capabilities, focusing on generating high-quality code through structured reasoning and automated test case validation.
Original Problem 🤔:
Traditional LLMs lack systematic reasoning capabilities for complex coding tasks, primarily exhibiting fast, intuitive responses without intermediate reasoning steps.
Solution in this Paper 🛠:
→ The framework introduces a Test Case Generator (TCG) that automatically creates standardized test cases for code validation.
→ It employs Monte Carlo Tree Search to generate code with detailed reasoning processes, including validity indicators.
→ The system uses a "think before acting" approach where it first generates pseudocode before producing executable code.
→ A Process Reward Model evaluates the quality of intermediate reasoning steps during code generation.
→ The framework implements self-play reinforcement learning, continuously generating new reasoning data to improve model performance.
Key Insights 💡:
→ Pseudocode-based reasoning significantly improves code generation quality when reasoning is correct
→ Combining supervised fine-tuning with Direct Preference Optimization enhances test case generation
→ Self-play reinforcement learning creates a continuous improvement cycle for both reasoning and code generation
Results 📊:
→ Test Case Generator achieved 89.2% pass rate after DPO, up from 80.8% after initial fine-tuning
→ Qwen2.5-Coder-7B showed 74.9% Average Sampling Pass Rate with pseudocode approach, a 25.6% improvement
🗞️ PaliGemma 2: A Family of Versatile VLMs for Transfer
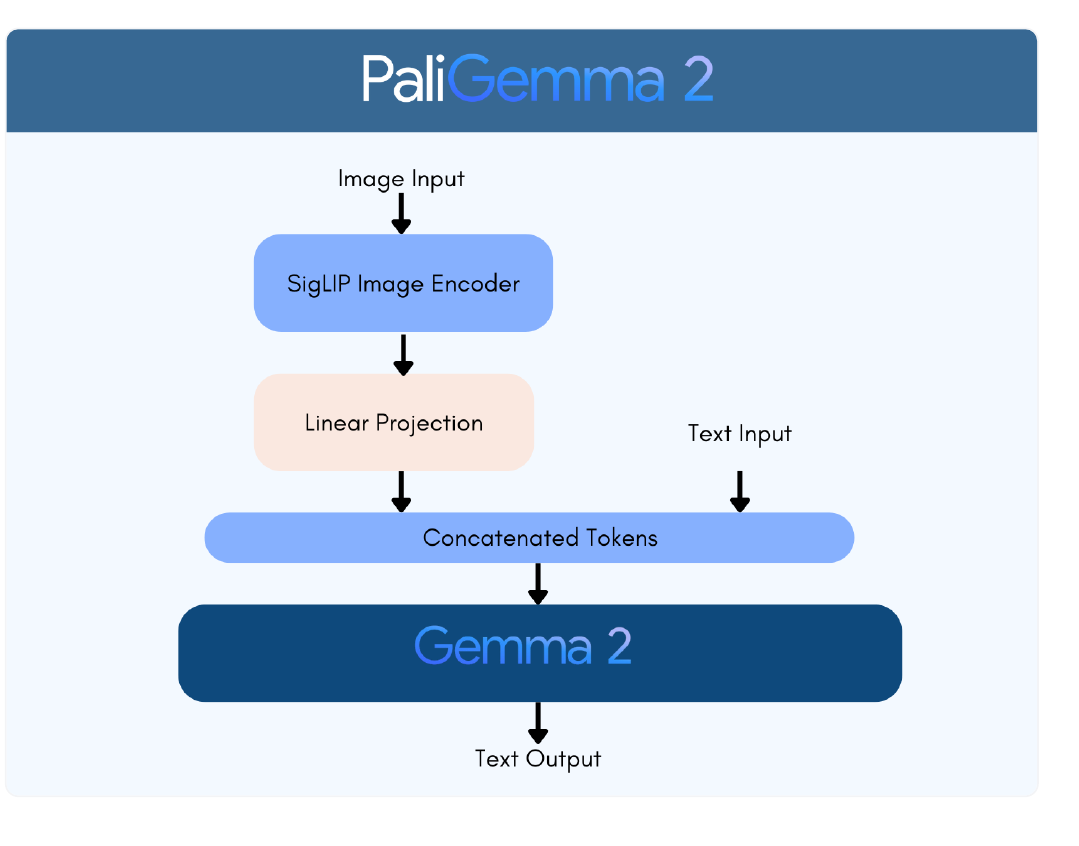
Google releases PaliGemma 2 vision-language models, upgrading from SigLIP vision encoder to Gemma 2 text decoder, offering 3 model sizes and 3 resolution options for enhanced flexibility and performance.
The Details
→ The model comes in 3B, 10B, and 28B parameter variants, supporting input resolutions of 224x224, 448x448, and 896x896. Pre-training leverages diverse datasets including WebLI, CC3M-35L, VQ2A, OpenImages, and WIT.
→ Performance testing shows minimal degradation with quantization: bfloat16 achieves 60.04% accuracy, 8-bit reaches 59.78%, and 4-bit maintains 58.72% on TextVQA validation set.
→ On DOCCI benchmark, PaliGemma 2 10B variant achieves 20.3 NES score, outperforming competitors like LLaVA-1.5 (40.6) and MiniGPT-4 (52.3). The model supports LoRA, QLoRA, and model freezing for efficient fine-tuning.
🗞️ "KV Shifting Attention Enhances Language Modeling"

KV shifting lets transformers learn patterns with half the layers, making models lighter and faster.
This paper introduces KV shifting attention, a modification to transformer architecture that enables single-layer models to learn induction heads efficiently. Traditional transformers need multiple layers for induction heads, which help models identify repeating patterns. KV shifting attention reduces model depth and width requirements while improving performance.
🤔 Original Problem:
LLMs rely on induction heads to identify patterns and perform in-context learning. Traditional transformers require at least two layers to implement induction heads, making models deeper and wider than necessary.
🔧 Solution in this Paper:
→ KV shifting attention decouples the key and value pairs in attention mechanism, allowing a token to access information from surrounding tokens.
→ When a token attends to the i-th position's key, it can get values from positions i-1 and i, maintaining causal masking.
→ The method adds only four learnable parameters per attention head: α1, α2, β1, β2, making it lightweight and easy to implement.
→ This modification enables single-layer transformers to effectively learn induction patterns that previously required multiple layers.
💡 Key Insights:
→ Induction heads can be implemented more efficiently by modifying attention mechanism
→ Model depth and width requirements can be reduced without sacrificing performance
→ KV shifting provides smoother optimization and faster convergence
📊 Results:
→ 2.9B parameter model with KV shifting achieved 38.57 MMLU score vs 36.45 baseline
→ Single-layer KV shifting matches performance of two-layer vanilla transformer
→ Faster convergence across model scales from toy models to 19B parameters
🗞️ "Survey of different Large Language Model Architectures: Trends, Benchmarks, and Challenges"

This survey paper provides a comprehensive analysis of LLM architectures, exploring their evolution, capabilities, and challenges. It examines three core architectures - encoder-only, decoder-only, and encoder-decoder models, while analyzing their performance across various benchmarks and tasks.
🛠️ Methods used in this Paper:
→ The paper introduces a systematic categorization of LLM architectures into auto-encoding, auto-regressive, and sequence-to-sequence models.
→ It analyzes key innovations in model compression, including LoRA, quantization, and knowledge distillation.
→ The research examines multimodal integration techniques that enable LLMs to process text, images, audio, and video.
→ It explores distributed computation strategies that enable training of models with over trillion parameters.
💡 Key Insights:
→ Auto-regressive models excel at generation but sacrifice bidirectional context
→ Encoder-decoder architectures offer the best balance for tasks requiring both understanding and generation
→ Model compression techniques can reduce computational costs by 90% while maintaining performance
→ Multimodal architectures require specialized fusion mechanisms to align different data types effectively
🗞️ "LMAct: A Benchmark for In-Context Imitation Learning with Long Multimodal Demonstrations"

LMAct shows current LLMs still can't consistently learn to act from examples, even with hundreds of demonstrations
LMAct introduces a benchmark to test if LLMs can learn decision-making from expert demonstrations. It evaluates models' ability to generalize from multimodal examples in contexts up to 1M tokens across games like chess, Atari, and grid worlds.
🤔 Original Problem
Today's LLMs struggle with simple decision-making tasks even when they have good factual knowledge about solving them. They often fail to translate knowledge into effective actions.
🔧 Solution in this Paper
→ Created a benchmark called LMAct to test LLMs' decision-making abilities using up to 512 expert demonstrations
→ Evaluated 6 frontier models (Claude 3.5, Gemini 1.5, GPT-4o, o1) on interactive tasks like chess, tic-tac-toe, Atari games
→ Used both text and image state representations to test multimodal capabilities
→ Pushed context lengths up to 1M tokens to test long-context reasoning
💡 Key Insights
→ Most models rarely reach expert performance despite having many demonstrations
→ Performance often independent of number of demonstrations shown
→ Some models show strong in-context learning on specific tasks like grid world navigation
→ Text representations generally work better than image-based ones
📊 Results
→ Only o1-preview reached near-expert performance on crosswords and tic-tac-toe
→ Most models struggled with Atari games, performing below random baseline
→ Grid world navigation saw best results across models
→ Increasing demonstrations beyond 1-2 episodes rarely improved performance